
大白话用Transformer做BEV 3D目标检测
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
作者 | 张恒
单位 | 法国国家信息与自动化研究所
研究方向 | 目标检测、传感器融合
编辑 | PaperWeekly
如何利用车载环视相机采集到的多张图像实现精准的 3D 目标检测,是自动驾驶感知领域的重要课题之一。针对这个问题,传统的检测方案可以概括为:先利用一个 2D 模型在各自的相机视角获取 3D 检测结果,再通过后处理算法将各个视角的 3D 检测框投影到 ego frame 再组合在一起。这样的做法简单有效,但是由于将多视角融合的步骤排除在模型学习之外,导致其难以检测相邻环视相机重叠部分中被截断的物体,也难以实现与 3D 点云传感器 (LiDAR) 的数据级/特征级融合。
▲ Perspective view VS BEV view 3D object detection
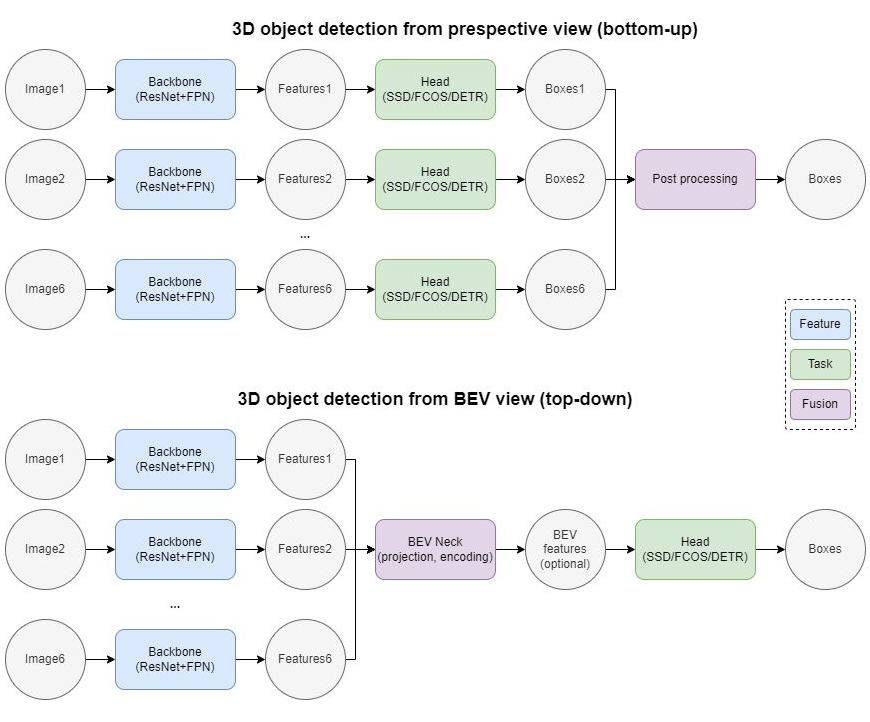
随着 Attention 机制在 Vision 领域的成功应用,大家开始关注如何将多个 Perspective view 的图片表征 (image representation) 转化为一个统一的BEV view (Bird's Eye View, 鸟瞰图) 的场景表征 (scene representation),从而实现完整统一的 3D 目标检测。具体而言,传统的 2D 网络包含 Backbone 和 Head 两个模块,分别用于特征提取和目标检测。BEV 网络则在二者之间增加一个 BEV Neck,用于 2D 到 3D 的 BEV 投影以及 BEV 视角下的特征提取。本文尝试盘点一下目前市面上几种主流的 Transformer-based BEV 3D object detection 的方法,重点着眼于如何高效的从环视相机视角提取 BEV 特征。 以下文章或多或少都借鉴了 DETR [1] 的检测思路,不了解的同学建议复习一下前篇解读 —— 大白话用Transformer做Object Detection,以做到无缝衔接。
Feature point sampling
DETR3D [2] 将原本的 DETR 模型拓展到 3D 空间。具体而言:在 2D Image feature extraction 部分,利用共享权重的 ResNet+FPN (output stride = 1/8, 1/16, 1/32, 1/64) 提取环视相机所采集到的 6 张图片的特征。 在 3D Transformer decoder 部分,每个 object query 先通过一个子网络预测所查询物体在真实世界的 3D 坐标 (reference point),再利用由相机的内参外参所构造的坐标变换矩阵 (camera transformation matrices, 3x4) 将真实世界的 3D 坐标投影至环视相机的 2D 像素坐标,并应用双线性插值采样各个相机视角、各个 PFN 层级同一位置的特征点(投影在图像外的特征点用 0 填充),最后利用所采样到的 6x4=24 个特征点的均值作为物体特征更新 object query。 Feature point sampling有很多优点:1)计算量小(毕竟只采样 24 个特征点);2)兼容 FPN(应该对检测不同距离的物体有帮助);3)避免了 dense depth prediction(只需要预测 sparse object query 的 3D 坐标,不需要预测每张图片、每个像素的深度信息)。 Global cross-attention
无法直接用 3D object query 在 2D spatial features 上实现查询匹配的原因之一,是二者空间上的不一致:在 2D 图片上两个点之间的坐标距离难以表述 3D 世界中这两个点的实际距离。 为了将 2D 的图像特征扩展到 3D 检测空间(以方便 3D object query 查询匹配),PETR [3] 选择在 Positional embedding 方面做改进:为 2D 特征图上的每个像素生成一个对应真实世界中的 3D 坐标列表(2D 图片上的一个点对应 3D 真实世界中以相机镜头为起始点的一条射线 (camera ray),列表即是在这条射线上采样的 N 个点的 3D 坐标集合),再通过 MLP 将这个坐标列表转化为 3D Positional embedding。 下图展示了前视相机的左中右三个点与其他所有相机视角的 3D Positional embedding 的相似度比较,可以发现与这三个点所对应真实世界的三条射线夹角较小的区域相似度较高,证明这种 2D 到 3D 的转换是有效的。


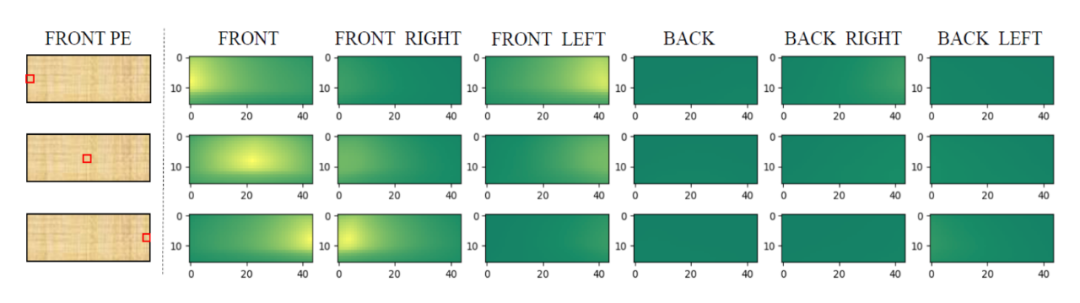
▲ 图片来自PETR

Deformable cross-attention
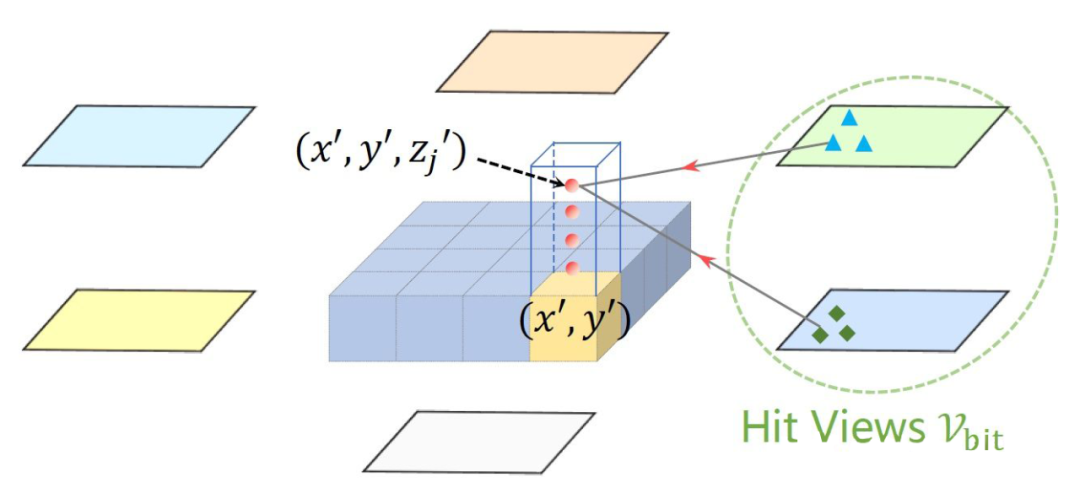

Lift-Splat
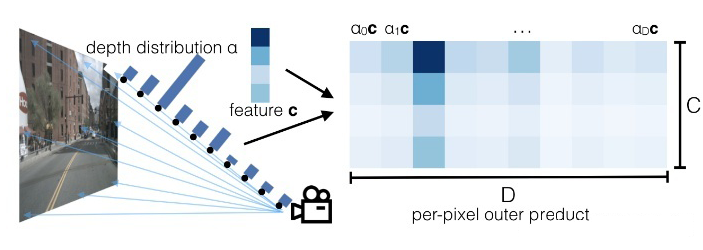 ▲ 图片来自Lift, Splat, Shoot
▲ 图片来自Lift, Splat, Shoot

Future directions

参考文献
[1] End-to-End Object Detection with Transformers https://arxiv.org/abs/2005.12872
[2] DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries https://arxiv.org/abs/2110.06922
[3] PETR: Position Embedding Transformation for Multi-View 3D Object Detection https://arxiv.org/abs/2203.05625
[4] Anchor DETR: Query Design for Transformer-Based Object Detection https://arxiv.org/abs/2109.07107
[5] BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers https://arxiv.org/abs/2203.17270
[6] Deformable DETR: Deformable Transformers for End-to-End Object Detection https://arxiv.org/abs/2010.04159
[7] Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D https://arxiv.org/abs/2008.05711
[8] Categorical Depth Distribution Network for Monocular 3D Object Detection https://arxiv.org/abs/2103.01100
[9] BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation https://bevfusion.mit.edu/assets/paper.pdf
[10] BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework https://arxiv.org/abs/2205.13790
[11] Sparse R-CNN: End-to-End Object Detection with Learnable Proposals https://arxiv.org/abs/2011.12450
[12] FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection https://arxiv.org/abs/2104.10956
本文仅做学术分享,如有侵权,请联系删文。
—THE END—