必看!重点高校教授带你读数据库顶会论文
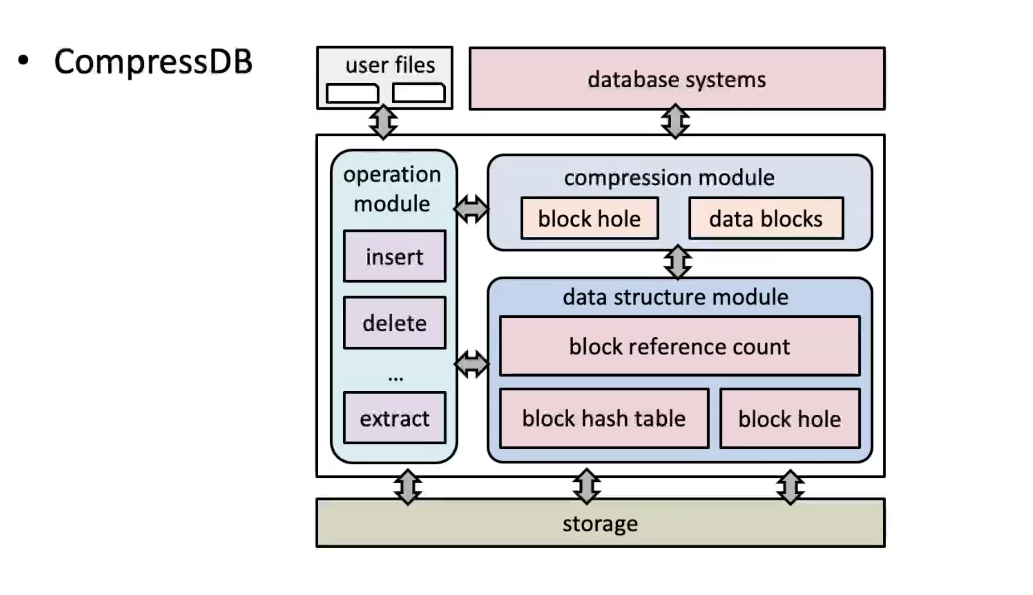
基于压缩数据直接计算
技术的数据库系统研究
中国人民大学副教授、博士生导师、腾讯犀牛鸟
基金获得者,张峰
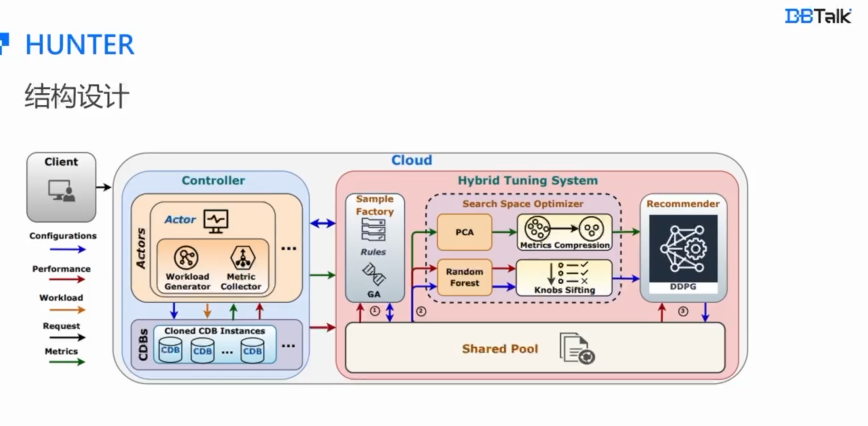
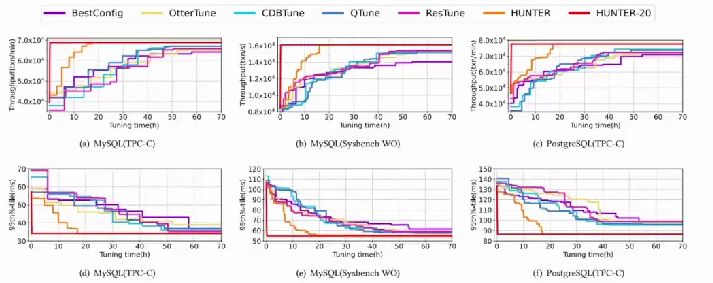
面向个性化需求的在线
云数据库混合调优系统
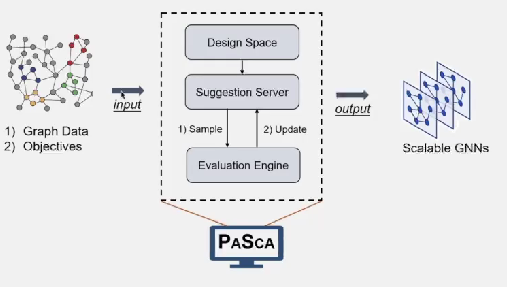
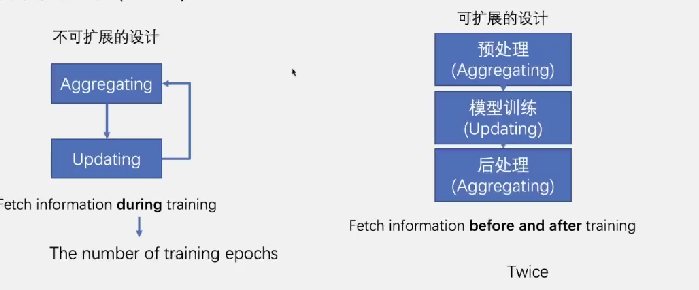
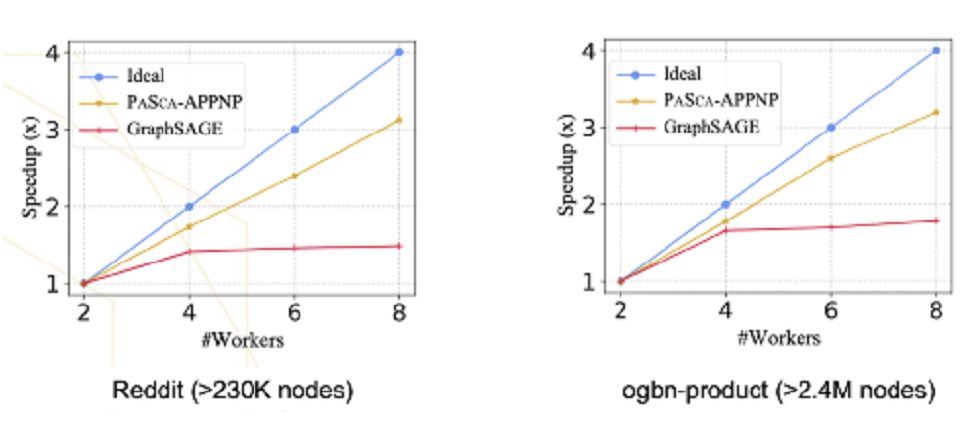
可扩展的图神经结构搜索系统
圆桌讨论:产学研协同,合作共赢
写在最后
﹀
﹀
﹀

基于压缩数据直接计算技术,定义新型数据库处理 | SIGMOD 2022入选论文解读

三篇论文入选国际顶会SIGMOD,厉害了腾讯云数据库
↓↓点击阅读原文,了解更多优惠
评论

基于压缩数据直接计算
技术的数据库系统研究
中国人民大学副教授、博士生导师、腾讯犀牛鸟
基金获得者,张峰
面向个性化需求的在线
云数据库混合调优系统
可扩展的图神经结构搜索系统
圆桌讨论:产学研协同,合作共赢
写在最后
﹀
﹀
﹀
基于压缩数据直接计算技术,定义新型数据库处理 | SIGMOD 2022入选论文解读
三篇论文入选国际顶会SIGMOD,厉害了腾讯云数据库
↓↓点击阅读原文,了解更多优惠