
读博了
机器学习算法与Python实战
共 4557字,需浏览 10分钟
·
2022-07-26 14:09
大家好哇,新同学都叫我张北海,老同学都叫我老胡,其实是一个人,只是我特别喜欢章北海这个《三体》中的人物,张是错别字。

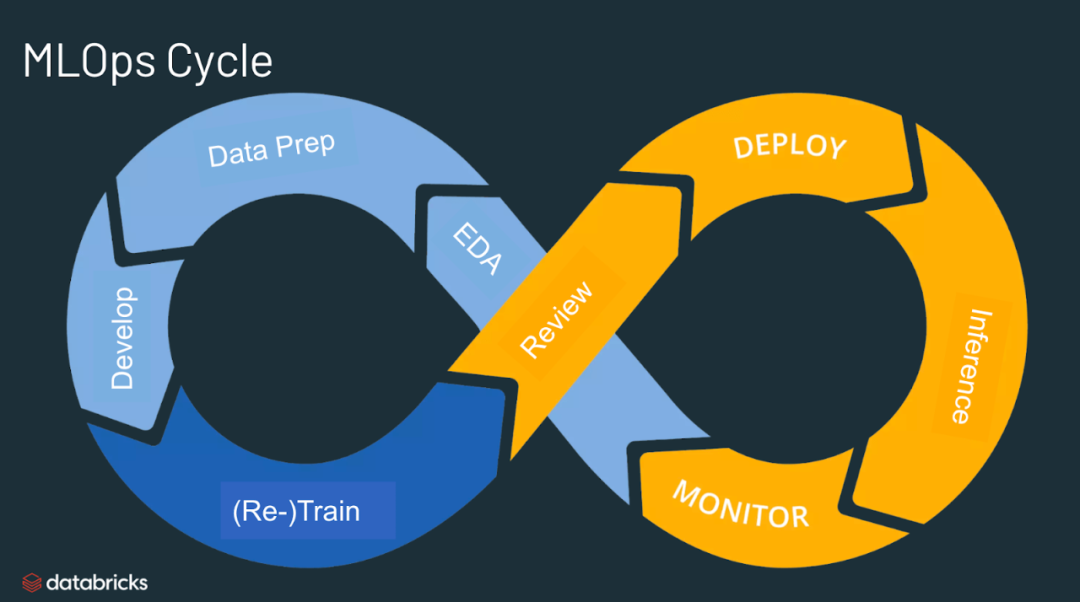
Platform MLE 负责 pipeline 功能的创建,Task MLE 负责 pipeline 使用功能; Platform MLE 负责模型训练框架,Task MLE 负责编写模型架构的配置文件和重新训练; Platform MLE 负责触发 ML 性能下降警报,Task MLE 对警报采取行动。
推荐阅读
整理不易,点赞三连↓
评论