
微积分、线性代数和概率统计,这里有份详细的机器学习数学路线图
选自towardsdatascience
作者:Tivadar Danka
机器之心编译
编辑:小舟、陈萍
转自:机器之心
大学时期学的数学现在可能派上用场了,机器学习背后的原理涉及许多数学知识。深入挖掘一下,你会发现,线性代数、微积分和概率论等都和机器学习背后的算法息息相关。

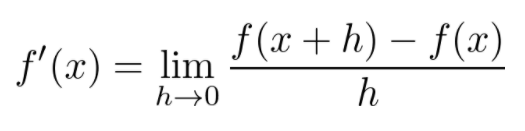
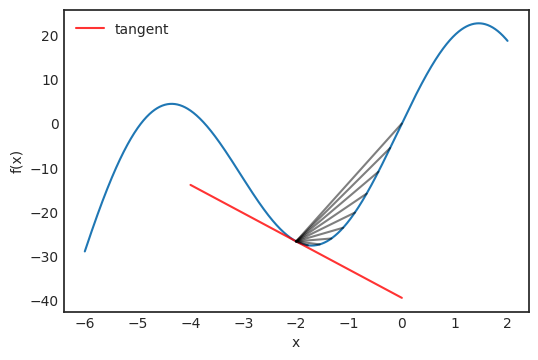

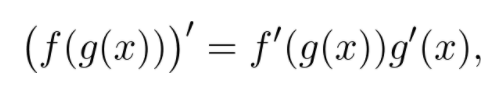
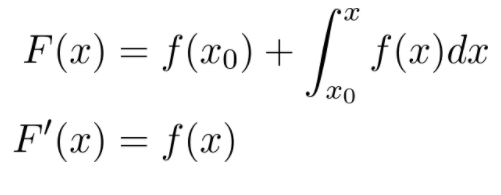
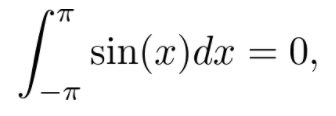
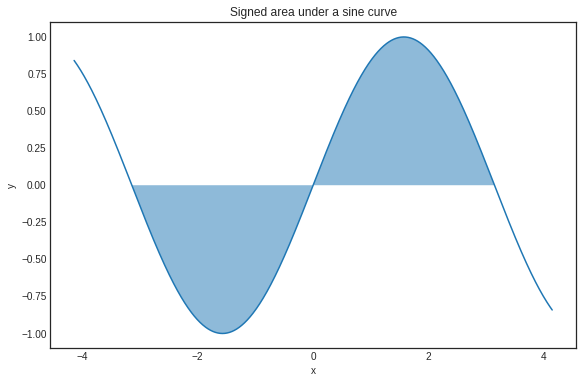
MIT 课程链接:https://www.youtube.com/playlist?list=PL590CCC2BC5AF3BC1
教科书链接:https://ocw.mit.edu/resources/res-18-001-calculus-online-textbook-spring-2005/textbook/
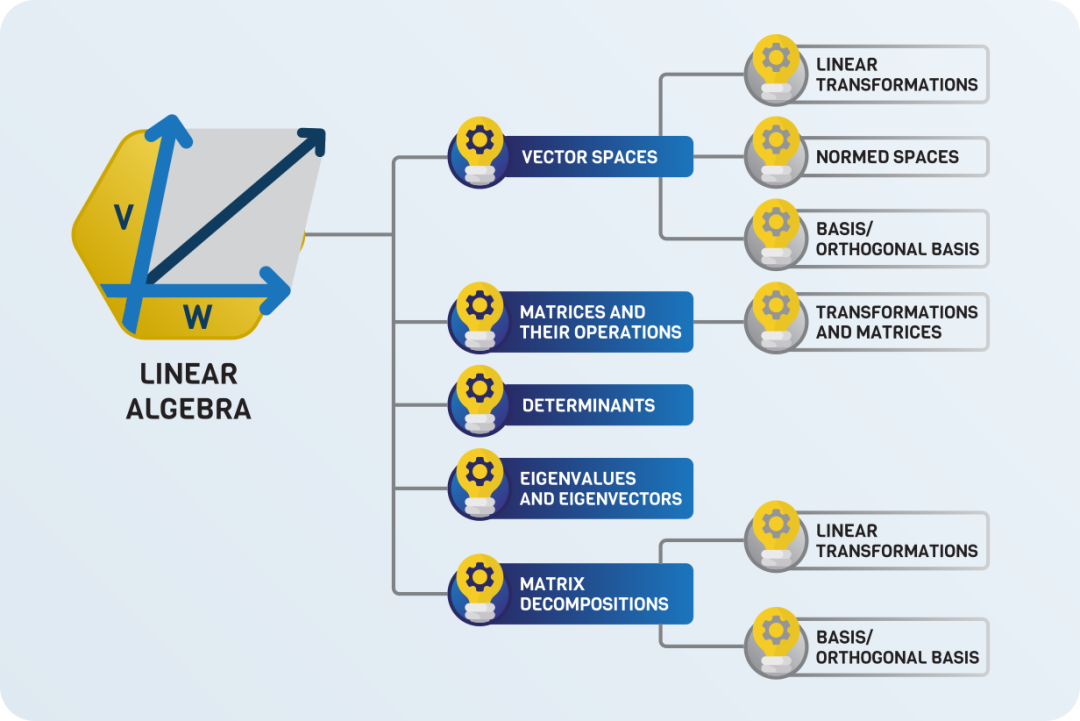
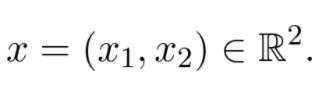
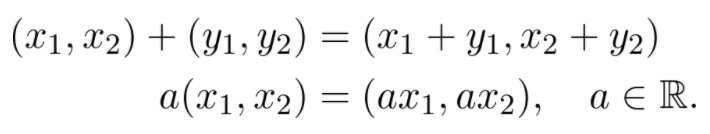
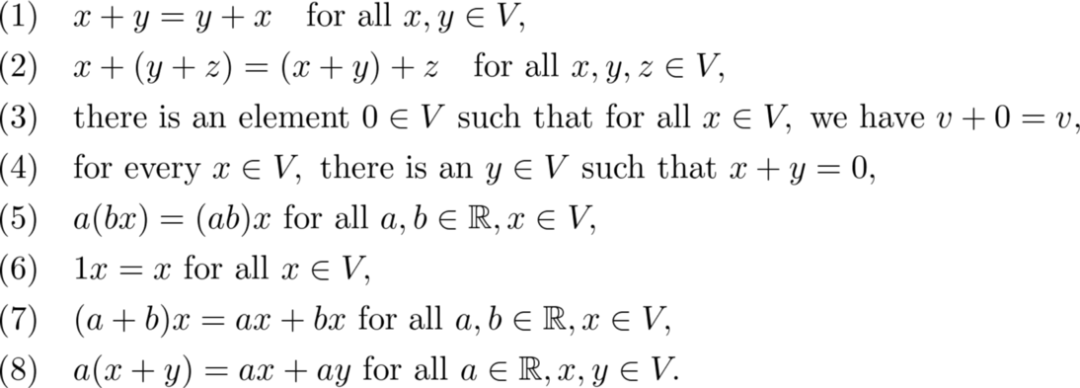
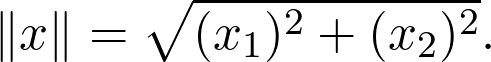
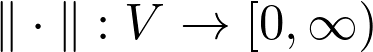
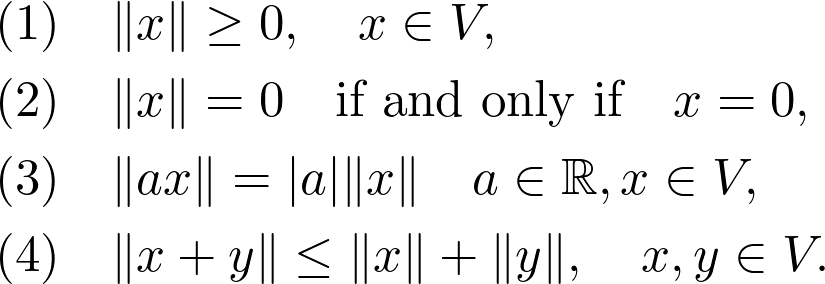
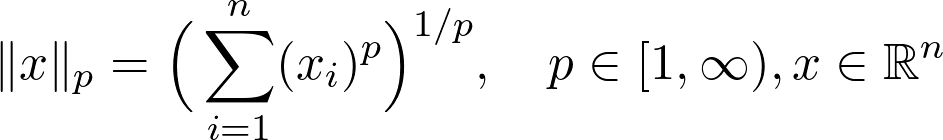

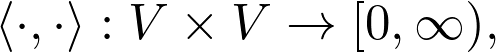
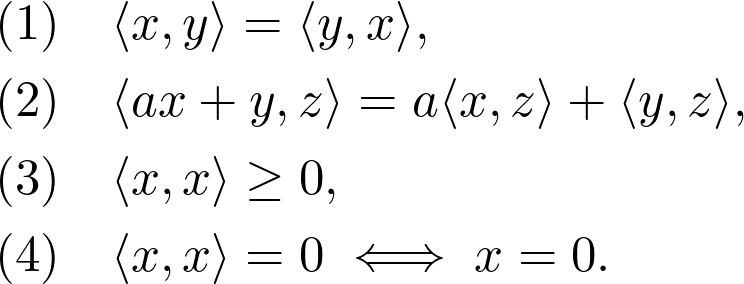
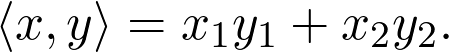
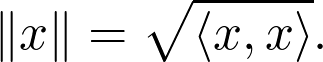
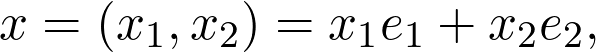
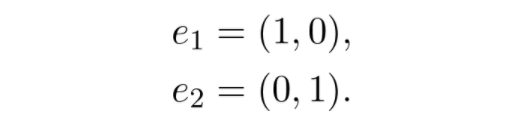
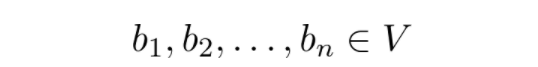
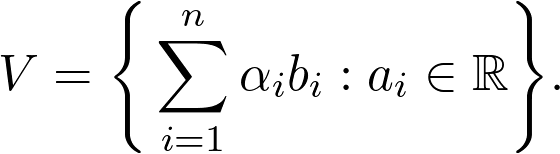
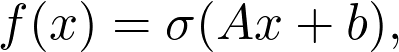

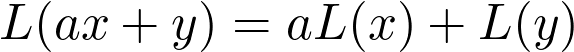
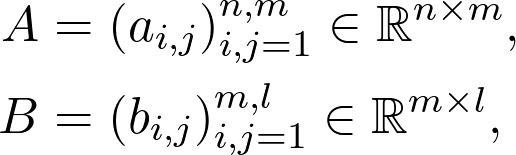
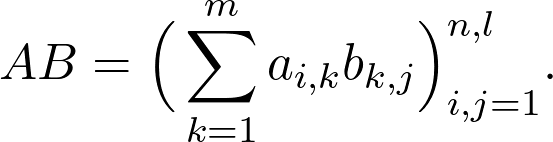

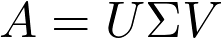
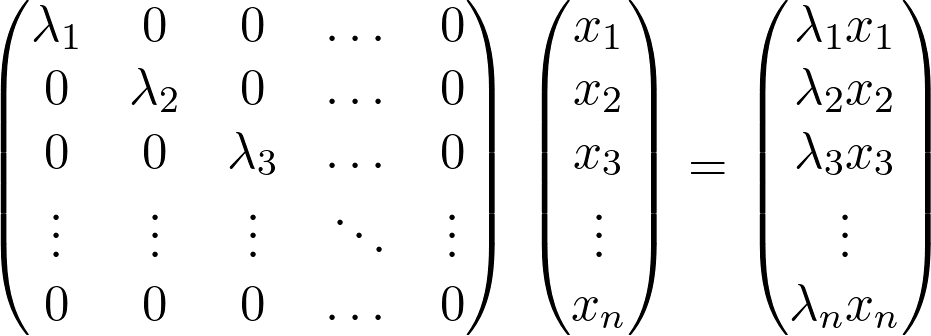
Sheldon Axler 的教材地址:http://linear.axler.net/
MIT 的网络公开课地址:https://www.youtube.com/playlist?list=PL49CF3715CB9EF31D
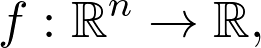
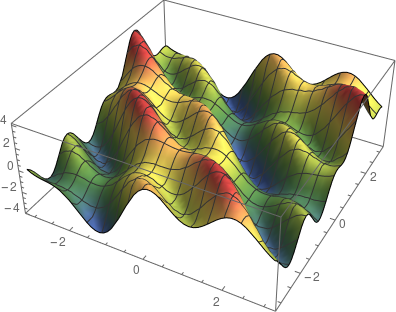
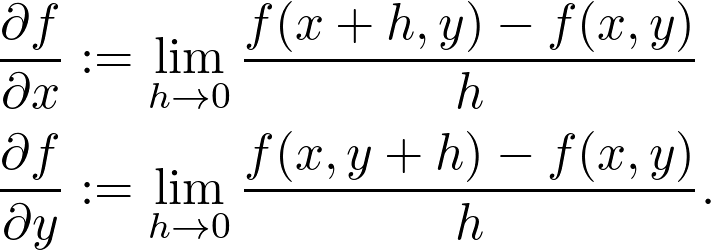
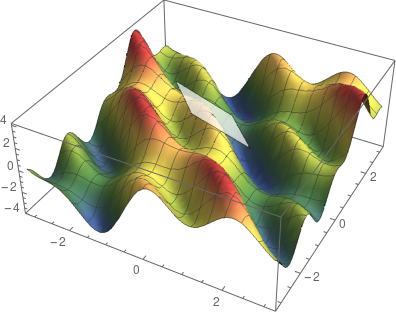
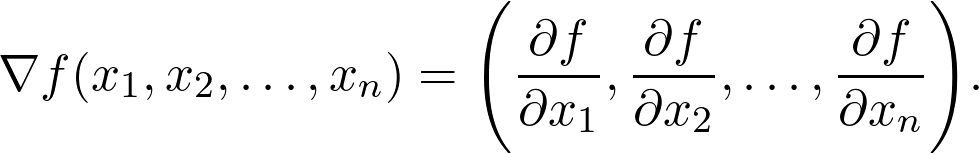
计算当前位置 x_0 处的梯度。
在梯度方向上走一小步即可到达点 x_1(步长称为学习率)。
返回步骤 1,重复该过程,直至收敛为止。
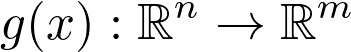
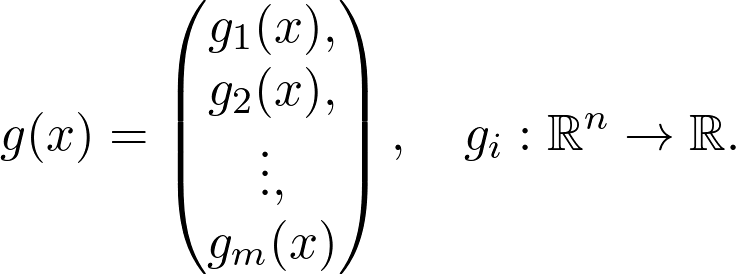
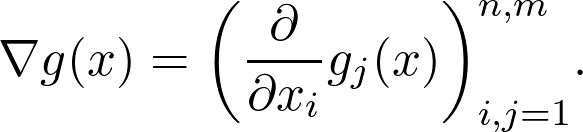
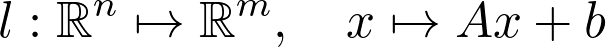
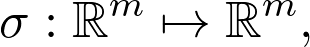
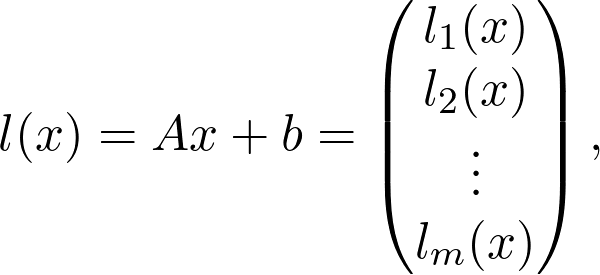
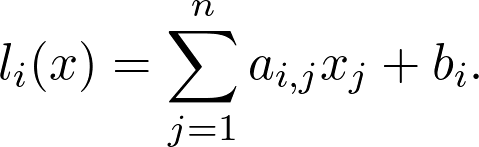
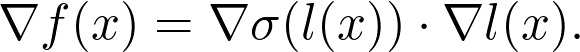
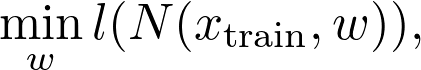
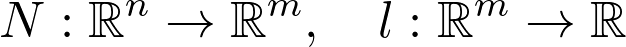
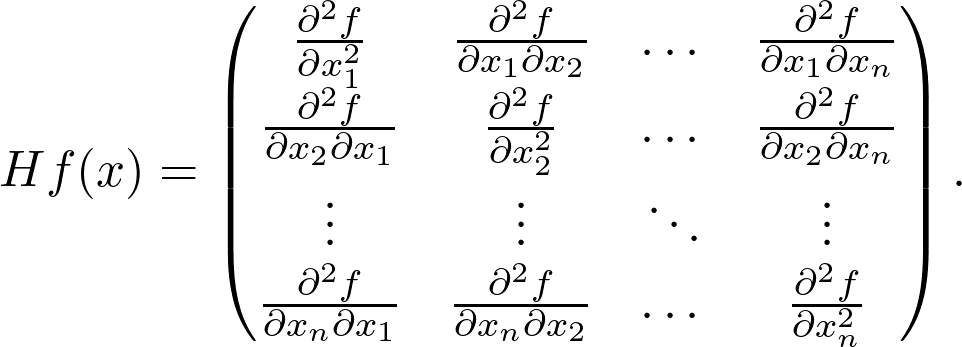
https://www.youtube.com/playlist?list=PLSQl0a2vh4HC5feHa6Rc5c0wbRTx56nF7,
https://www.youtube.com/playlist?list=PL4C4C8A7D06566F38。
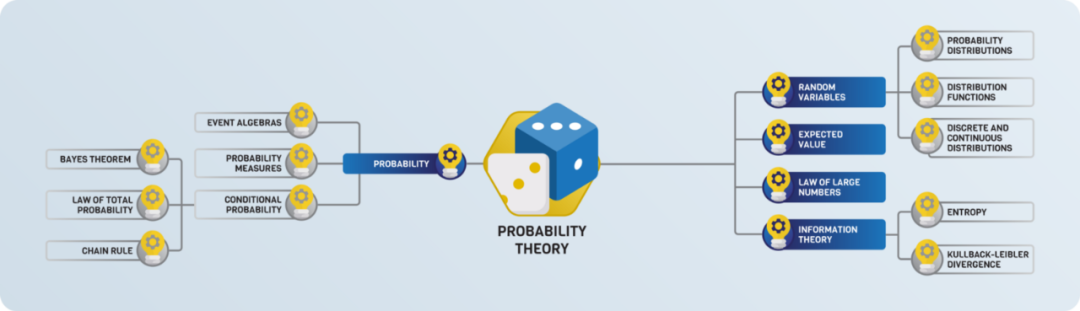

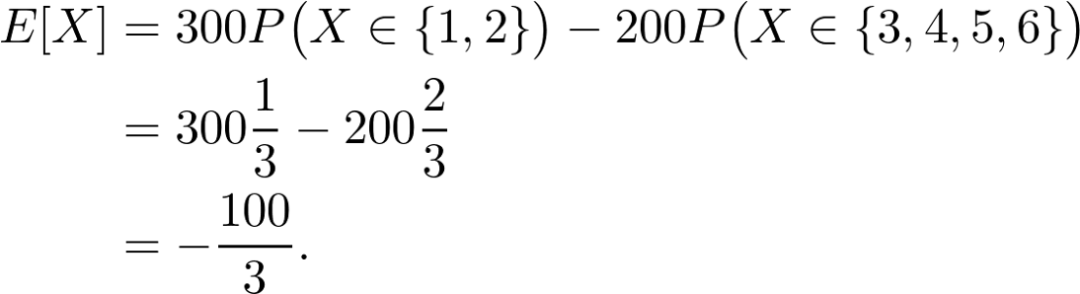
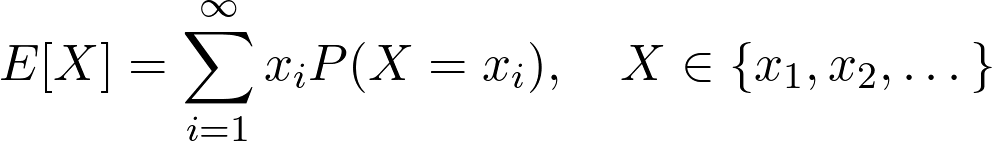
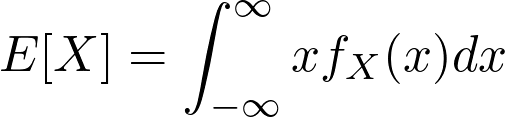
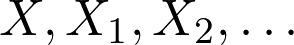
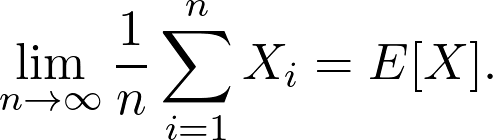
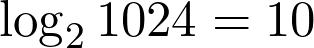
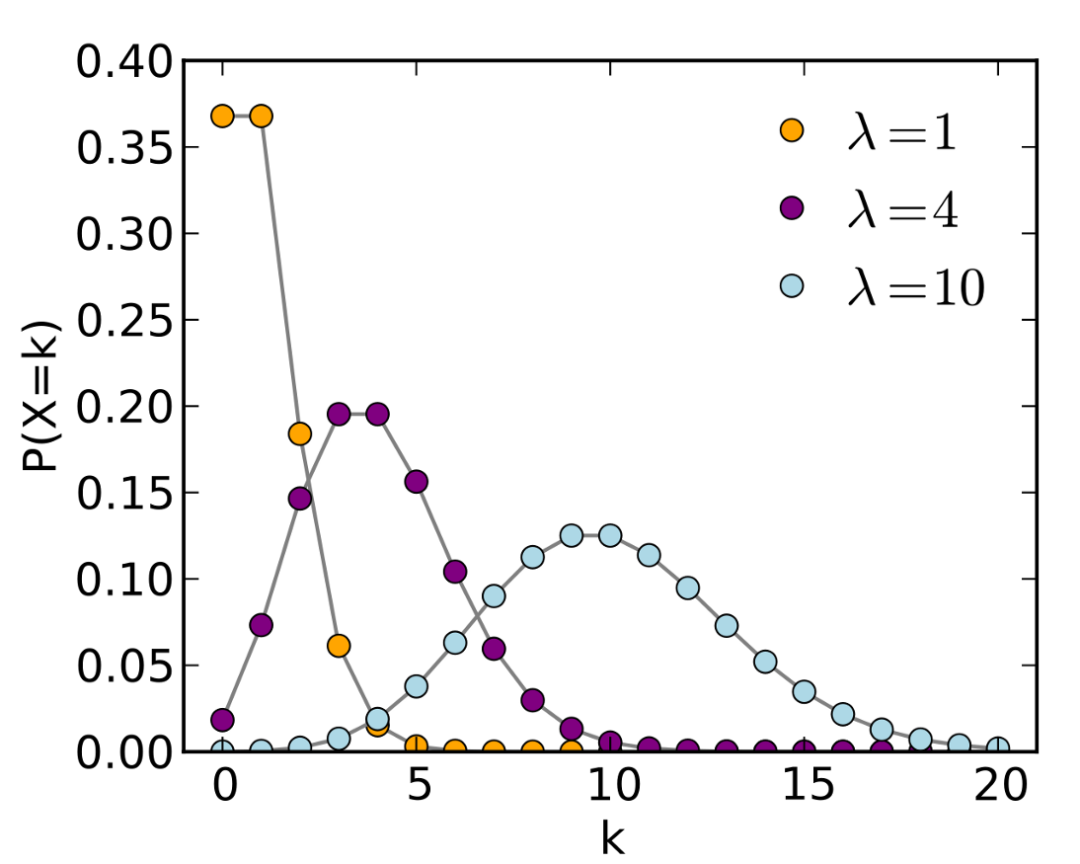
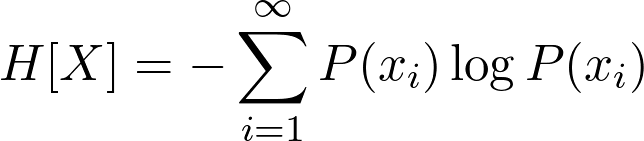
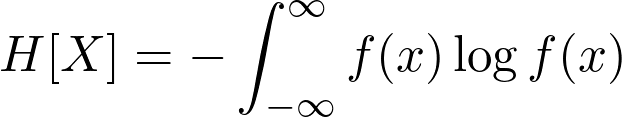
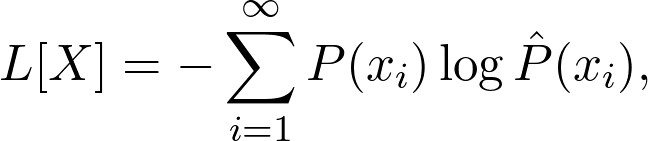
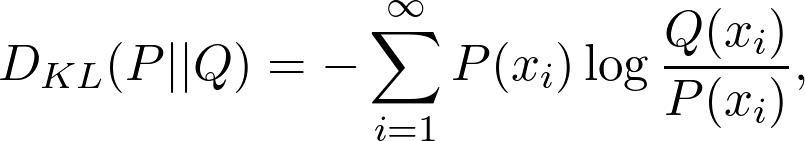
Pattern Recognition and Machine Learning by Christopher Bishop
The Elements of Statistical Learning by Trevor Hastie, Robert Tibshirani, and Jerome Friedman
