
Hinton,Lecun和Bengio三巨头联手再发万字长文:深度学习的昨天、今天和明天
共 4933字,需浏览 10分钟
·
2021-07-08 23:26

新智元报道
新智元报道
来源:ACM
编辑:Priscilla Emil
【新智元导读】2018图灵奖获得者Yoshua Bengio, Yann LeCun和Geoffrey Hinton再次受ACM邀请共聚一堂,共同回顾了深度学习的基本概念和一些突破性成果,讲述了深度学习的起源、发展及未来的发展面临的挑战。
2018年,ACM(国际计算机学会)决定将计算机领域的最高奖项图灵奖颁给Yoshua Bengio、Yann LeCun 和 Geoffrey Hinton,以表彰他们在计算机深度学习领域的贡献。

这也是图灵奖第三次同时颁给三位获奖者。
用于计算机深度学习的人工神经网络在上世纪80年代就已经被提出,但是在当时科研界由于其缺乏理论支撑,且计算力算力有限,导致其一直没有得到相应的重视。
是这三巨头一直在坚持使用深度学习的方法,并在相关领域进行了深入研究。通过实验发现了许多惊人的成果,并为证明深度神经网络的实际优势做出了贡献。
所以说他们是深度学习之父毫不夸张。
在AI界,当Yoshua Bengio、Yann LeCun 和 Geoffrey Hinton 这三位大神同时出场的时候,一定会有什么大事发生。
最近,深度学习三巨头受ACM通讯杂志之邀,共同针对深度学习的话题进行了一次深度专访,提纲挈领地回顾了深度学习的基本概念、最新的进展,以及未来的挑战。
广大的AI开发者们,看了高人指点之后是不是对于未来之路更加明晰了?下面我们来看看他们都聊了些什么。
深度学习的兴起
在2000年代早期,深度学习引入的一些元素,让更深层的网络的训练变得更加容易,也因此重新激发了神经网络的研究。
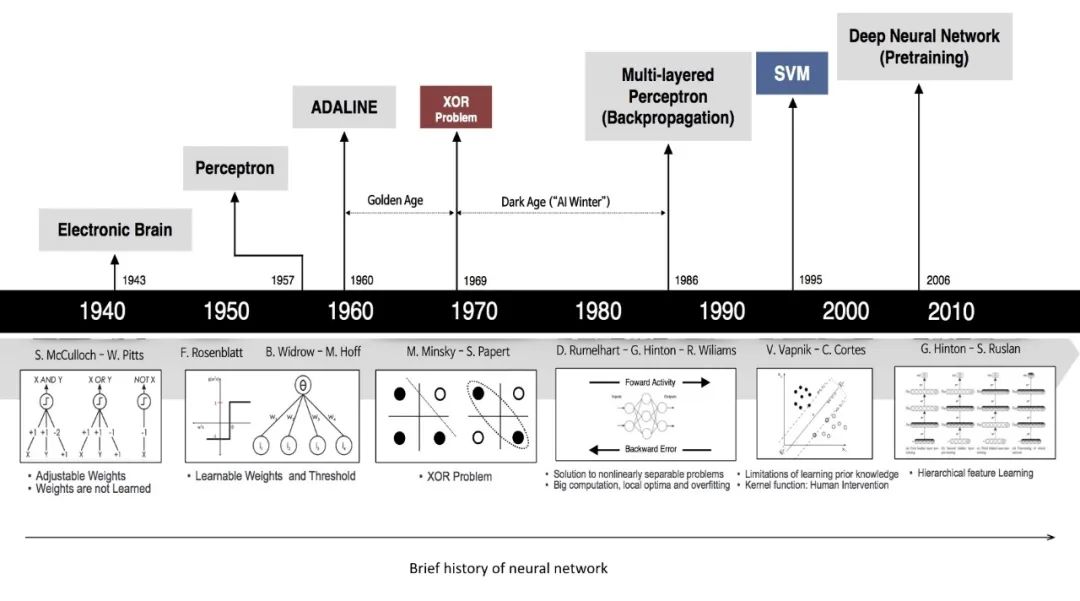
GPU和大型数据集的可用性是深度学习的关键因素,也得到了具有自动区分功能、开源、灵活的软件平台(如Theano、Torch、Caffe、TensorFlow等)的增强作用。训练复杂的深度网络、重新使用最新模型及其构建块也变得更加容易。而更多层网络的组合允许更复杂的非线性,在感知任务中取得了意料之外的结果。

深度学习深在哪里?有人认为,更深层次的神经网络可能更加强大,而这种想法在现代深度学习技术出现之前就有了。但是,这样的想法其实是由架构和训练程序的不断进步而得来的,并带来了与深度学习兴起相关的显著进步。
更深层的网络能够更好地概括「输入-输出关系类型」,而这不仅只是因为参数变多了。深度网络通常比具有相同参数数量的浅层网络具有更好的泛化能力。例如,时下流行的计算机视觉卷积网络架构类别是ResNet系列,其中最常见的是ResNet-50,有50层。
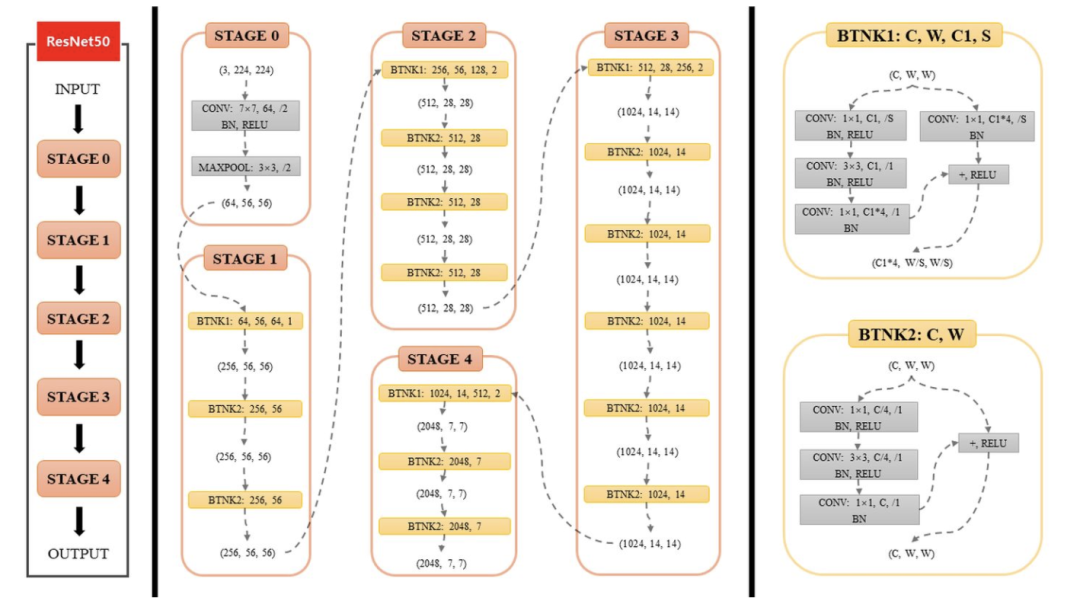
图源:知乎@臭咸鱼
深度网络之所以能够脱颖而出,是因为它利用了一种特定形式的组合性,其中一层的特征以多种不同的方式组合,这样在下一层就能够创建更多的抽象特征。
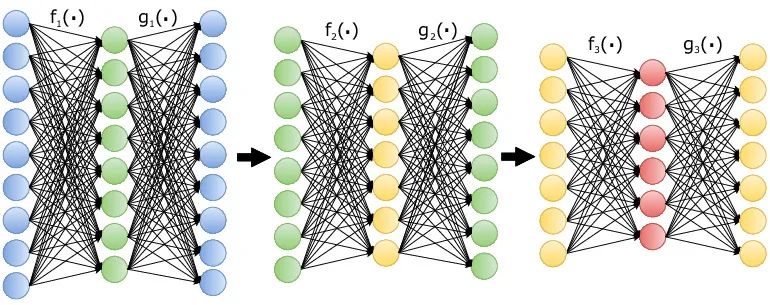
无监督的预训练。当标记训练示例的数量较小,执行任务所需的神经网络的复杂性也较小时,能够使用一些其他信息源来创建特征检测器层,再对这些具有有限标签的特征检测器进行微调。在迁移学习中,信息源是另一种监督学习任务,具有大量标签。但是也可以通过堆叠自动编码器来创建多层特征检测器,无需使用任何标签。
线性整流单元的成功之谜。早期,深度网络的成功,是因为使用了逻辑sigmoid非线性函数或与之密切相关的双曲正切函数,对隐藏层进行无监督的预训练。
长期以来,神经科学一直假设线性整流单元,并且已经在 RBM 和卷积神经网络的某些变体中使用。让人意想不到的是,人们惊喜地发现,非线性整流通过反向传播和随机梯度下降,让训练深度网络变得更加便捷,无需进行逐层预训练。这是深度学习优于以往对象识别方法的技术进步之一。
语音和物体识别方面的突破。声学模型将声波转换为音素片段的概率分布。Robinson、Morgan 等人分别使用了晶片机和DSP芯片,他们的尝试均表明,如果有足够的处理能力,神经网络可以与最先进的声学建模技术相媲美。

2009年,两位研究生使用 NVIDIA GPU ,证明了预训练的深度神经网络在 TIMIT 数据集上的表现略优于 SOTA。这一结果重新激起了神经网络中几个主要语音识别小组的兴趣。2010 年,在不需要依赖说话者训练的情况下,基本一致的深度网络能在大量词汇语音识别方面击败了 SOTA 。2012 年,谷歌显着改善了 Android 上的语音搜索。这是深度学习颠覆性力量的早期证明。
大约在同一时间,深度学习在 2012 年 ImageNet 竞赛中取得了戏剧性的胜利,在识别自然图像中的一千种不同类别的物体时,其错误率几乎减半。这场胜利的关键在于,李飞飞及其合作者为训练集收集了超过一百万张带标签的图像,以及Alex Krizhevsky 对多个 GPU 的高效使用。

深度卷积神经网络具有新颖性,例如,ReLU能加快学习,dropout能防止过度拟合,但它基本上只是一种前馈卷积神经网络,Yann LeCun 和合作者多年来一直都在研究。
计算机视觉社区对这一突破的反应令人钦佩。证明卷积神经网络优越性的证据无可争议,社区很快就放弃了以前的手工设计方法,转而使用深度学习。
深度学习近期的主要成就
三位大神选择性地讨论了深度学习的一些最新进展,如软注意力(soft attention)和Transformer 架构。
深度学习的一个重大发展,尤其是在顺序处理方面,是乘法交互的使用,尤其是软注意力的形式。这是对神经网络工具箱的变革性补充,因为它将神经网络从纯粹的矢量转换机器,转变为能够动态选择对哪些输入进行操作的架构,并且将信息存储在关联存储器中。这种架构的关键特性是,它们能有效地对不同类型的数据结构进行操作。
软注意力可用于某一层的模块,可以动态选择它们来自前一层的哪些向量,从而组合,计算输出。这可以使输出独立于输入的呈现顺序(将它们视为一组),或者利用不同输入之间的关系(将它们视为图形)。

Transformer 架构已经成为许多应用中的主导架构,它堆叠了许多层“self-attention”模块。同一层中对每个模块使用标量积来计算其查询向量与该层中其他模块的关键向量之间的匹配。匹配被归一化为总和1,然后使用产生的标量系数来形成前一层中其他模块产生的值向量的凸组合。结果向量形成下一计算阶段的模块的输入。
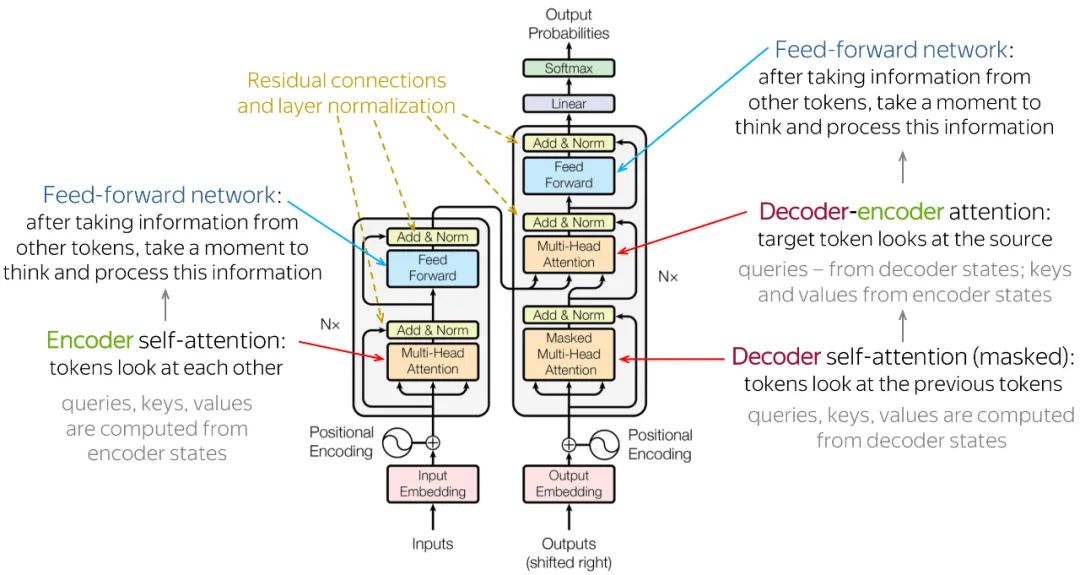
模块可以是多向的,以便每个模块计算几个不同的查询、键和值向量,从而使每个模块有可能有几个不同的输入,每个输入都以不同的方式从前一阶段的模块中选择。在此操作中,模块的顺序和数量无关紧要,因此可以对向量集进行操作,而不是像传统神经网络中那样对单个向量进行操作。例如,语言翻译系统在输出的句子中生成一个单词时,可以选择关注输入句子中对应的一组单词,与其在文本中的位置无关。
未来的挑战
未来的挑战
深度学习的重要性以及适用性在不断地被验证,并且正在被越来越多的领域采用。对于深度学习而言,提升它的性能表现有简单直接的办法——提升模型规模。
通过更多的数据和计算,它通常就会变得更聪明。比如有1750亿参数的GPT-3大模型(但相比人脑中的神经元突触而言仍是一个小数目)相比只有15亿参数的GPT-2而言就取得了显著的提升。

但是三巨头在讨论中也透露到,对于深度学习而言仍然存在着靠提升参数模型和计算无法解决的缺陷。
比如说与人类的学习过程而言,如今的机器学习仍然需要在以下几个方向取得突破:
1、监督学习需要太多的数据标注,而无模型强化学习又需要太多试错。对于人类而言,像要学习某项技能肯定不需要这么多的练习。

2、如今的系统对于分布变化适应的鲁棒性比人类差的太远,人类只需要几个范例,就能够快速适应类似的变化。
3、如今的深度学习对于感知而言无疑是最为成功的,也就是所谓的系统1类任务,如何通过深度学习进行系统2类任务,则需要审慎的通用步骤。在这方面的研究令人期待。
在早期,机器学习的理论学家们始终关注于独立相似分布假设,也就是说测试模型与训练模型服从相同的分布。而不幸的是,在现实世界中这种假设并不成立:比如说由于各种代理的行为给世界带来的变化,就会引发不平稳性;又比如说总要有新事物去学习和发现的学习代理,其智力的界限就在不断提升。
所以现实往往是即便如今最厉害的人工智能,从实验室投入到实际应用中时,其性能仍然会大打折扣。
所以三位大神对于深度学习未来的重要期待之一,就是当分布发生变化时能够迅速适应并提升鲁棒性(所谓的不依赖于分布的泛化学习),从而在面对新的学习任务时能够降低样本数量。
如今的监督式学习系统相比人类而言,在学习新事物的时候需要更多的事例,而对于无模型强化学习而言,这样的情况更加糟糕——因为相比标注的数据而言,奖励机制能够反馈的信息太少了。
所以,我们该如何设计一套全新的机械学习系统,能够面对分布变化时具备更好的适应性呢?
从同质层到代表实体的神经元组
如今的证据显示,相邻的神经元组可能代表了更高级别的向量单元,不仅能够传递标量,而且能够传递一组坐标值。这样的想法正是胶囊架构的核心,在单元中的元素与一个向量相关联,从中可以读取关键向量、数值向量(有时也可能是一个查询向量)。
适应多个时间尺度
大多数神经网络只有两个时间尺度:权重在许多示例中适应得非常慢,而行为却在每个新输入中对于变化适应得非常快速。通过添加快速适应和快速衰减的“快速权重”的叠加层,则会让计算机具备非常有趣的新能力。
尤其是它创建了一个高容量的短期存储,可以允许神经网络执行真正的递归,,其中相同的神经元可以在递归调用中重复使用,因为它们在更高级别调用中的活动向量可以重建稍后使用快速权重中的信息。
多时间尺度适应的功能在元学习(meta-learning)中正在逐渐被采纳。
更高层次的认知
在考虑新的任务时,例如在具有不一样的交通规则的城市中驾驶,甚至想象在月球上驾驶车辆时,我们可以利用我们已经掌握的知识和通用技能,并以新的方式动态地重新组合它们。
但是当我们采用已知的知识来适应一个新的设置时,如何避免已知知识对于新任务带来的噪音干扰?开始步骤可以采用Transformer架构和复发独立机制Recurrent Independent Mechanisms)。
对于系统1的处理能力允许我们在计划或者推测时猜测潜在的好处或者危险。但是在更高级的系统级别上,可能就需要AlphaGo的蒙特卡罗树搜索的价值函数了。
机械学习依赖于归纳偏差或者先验经验,以鼓励在关于世界假设的兼容方向上学习。系统2处理处理的性质和他们认知的神经科学理论,提出了几个这样的归纳偏差和架构,可以来设计更加新颖的深度学习系统。那么如何训练神经网络,能够让它们发现这个世界潜在的一些因果属性呢?
在20世纪提出的几个代表性的AI研究项目为我们指出了哪些研究方向?显然,这些AI项目都想要实现系统2的能力,比如推理能力、将知识能够迅速分解为简单的计算机运算步骤,并且能够控制抽象变量或者示例。这也是未来AI技术前进的重要方向。
听完三位的探讨,大家是不是觉得在AI之路上,光明无限呢?
参考资料:
https://cacm.acm.org/magazines/2021/7/253464-deep-learning-for-ai/fulltext
-往期精彩-


