
如何从 0 到 1 搭建性能检测系统
前言
前端页面性能对用户留存、用户直观体验有着重要影响,当页面加载时间超过 2 秒后,加载时间每增加一秒,就会有大量的用户流失,所以做好页面性能优化,无疑对网站来说是一个非常重要的步骤。
那如何才能知道一个页面的性能情况呢?知道了页面性能情况后又如何进行优化呢?一个页面的性能指标非常多,面对一大堆性能指标,可能一个老手也一时间不知道从何开始分析。而且不同团队,负责的业务不同,性能分析的指标也不能够一概而论。打个比方说,对于一般的电商网站,一定会有很多图片,那图片加载的性能提升对网站的性能提升作用就比较大。而对于一些由表单组成的中台页面,提升图片加载速度的收益远小于电商网站。
总结来说,不同的团队有着各自不同的业务,业务之间千差万别,性能指标也不能一概而论,所以用一套统一的检测模型覆盖所有场景是不现实的。本文将介绍如何定制一个属于自己团队的性能检测平台。
先看下政采云的性能检测平台——百策
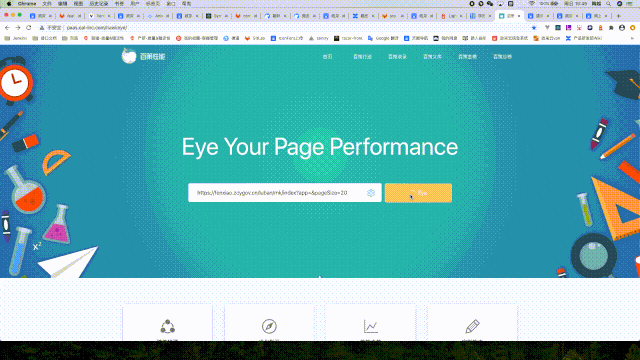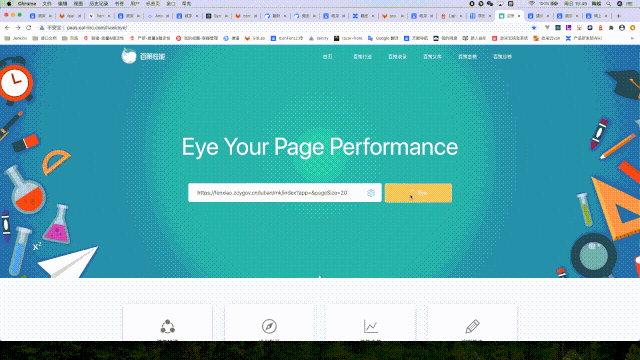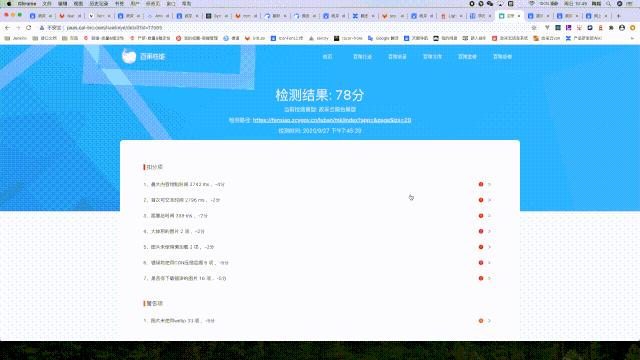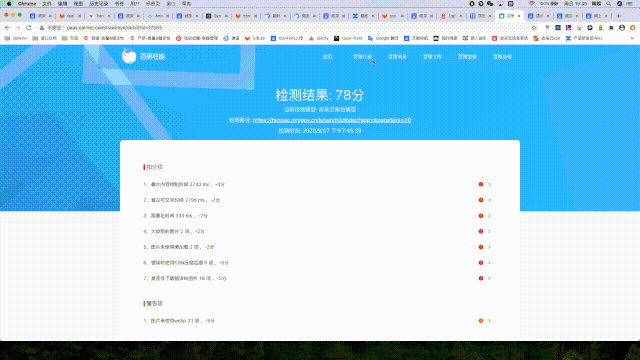
在聊性能指标之前,先讲一下 Lighthouse。
Lighthouse
Lighthouse 是一个开源的自动化工具,用于分析和改善 Web 应用的质量。运行 Lighthouse 共有 4 种方式,分别在 Chrome 开发者工具,Chrome 扩展程序,Node CLI 和 Node module。百策主要基于 Node module 方式,在其基础上进行扩展开发,Lighthouse 详细使用参见 Git:https://github.com/GoogleChrome/lighthouse
下图为 Lighthouse 检测页面性能的一个最终结果,可以看到其实指标已经比较完善了。
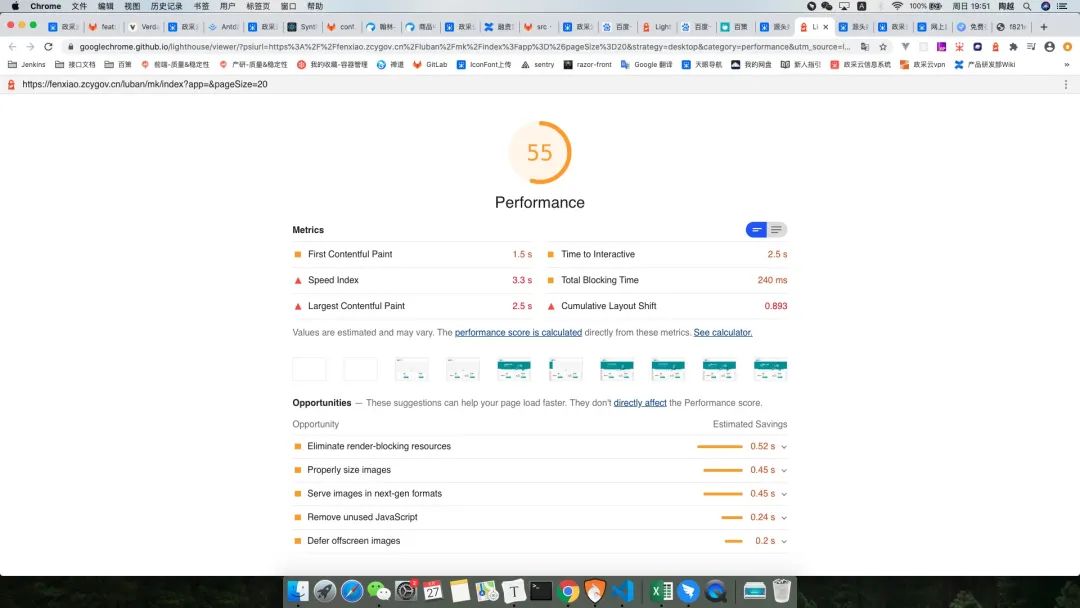
可能有人会问,为什么不直接使用 Lighthouse。首先,由于不可描述的原因,国内直接使用 Chrome 开发者工具中的 Lighthouse 时,会一直处于 Lighthouse is warming up 状态。其次,Chrome 扩展程序对于需要登录的页面也不支持。最后,对于前言中,某一些定制需求 Lighthouse 也不能全然满足,所以要基于 Lighthouse 进行定制,做一个满足业务要求的性能检测平台。
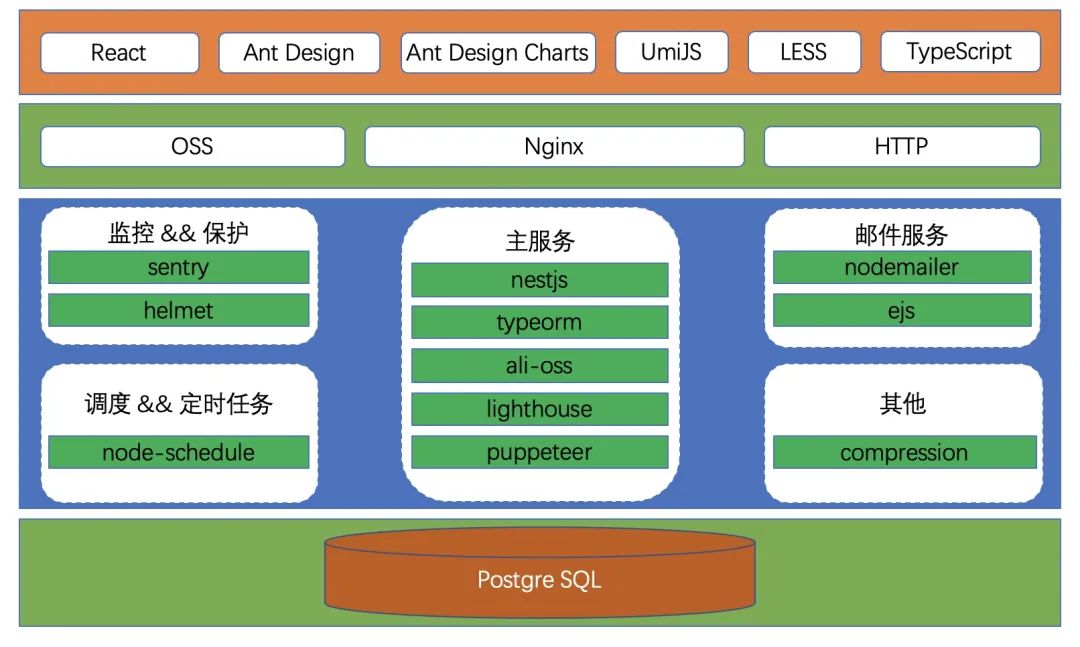
整体设计架构
下图是百策系统的一个整体架构
-
前端主要使用的是 Antd 和 Antd Charts,包含常规页面的展示和部分性能走势图表的展示。 -
服务端基于 nestjs 开发,接入 Sentry 做报警监控。helmet 用于保护系统免受一些众所周知的 Web 漏洞影响。 -
node-schedule 用于每周定时计算已统计入系统的页面性能,并通过 nodemailer 发送邮件。 -
Compression 主要用于启用 gzip。 -
最主要的检测服务基于 Puppeteer 和 Lighthouse 开发。
百策采集页面性能数据的流程
百策系统监控页面的方式主要采用的方式是合成监控,对于什么是合成监控,可以参考此文章:蚂蚁金服如何把前端性能监控做到极致 (https://www.infoq.cn/article/Dxa8aM44oz*Lukk5Ufhy)。总结来说,合成监控的优势就是:能够采集的数据更丰富,并且可以根据不同的场景定制不同的运行环境等。首先百策要根据不同的场景,比如政采云前台页面、政采云中台页面制定不同的检测模型。其次百策的主要目标是提升页面性能,并且需要保证环境和硬件条件一致的情况下对页面做性能比对,所以选择采用合成监控更加适合。
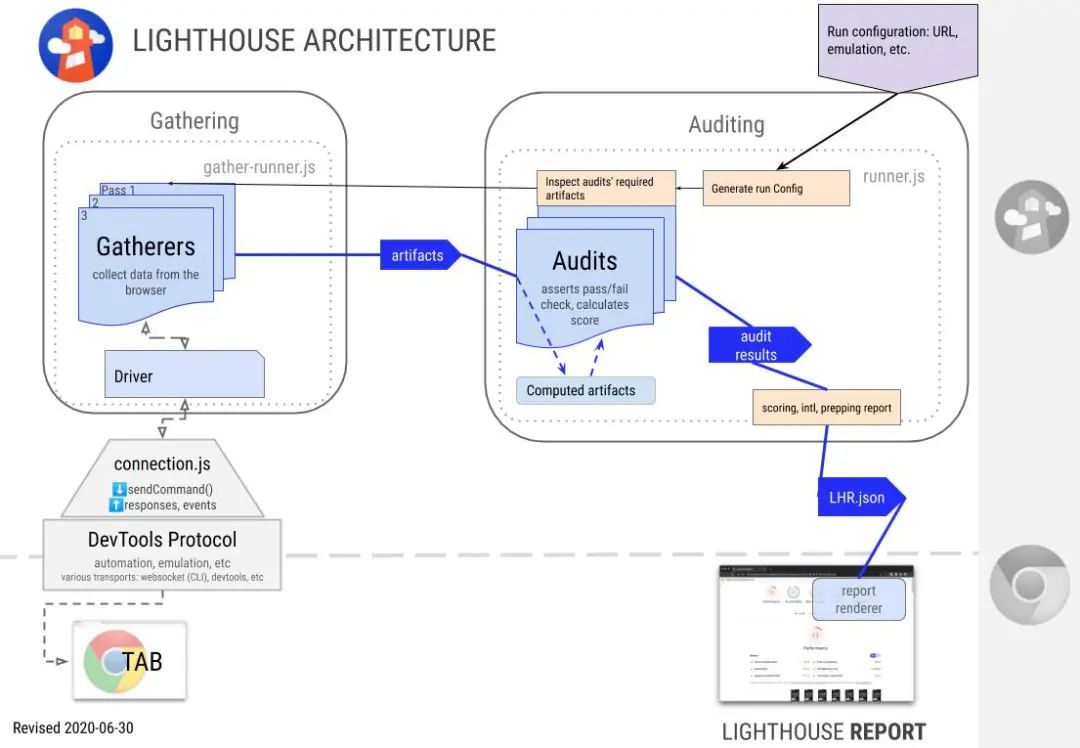
先看下 Chrome Lighthouse 的架构图(图来源于 Lighthouse Git),主要基于 4 个主要步骤实现,分别是交互驱动,收集,审计以及记录组成,参考了 Chrome Lighthouse,百策的检测模型逻辑也主要由这 4 步组成:
1、页面交互后,发起请求调用服务。
2、遍历当前页面所需要的收集器,合并为一个总的收集器,并采集数据。
3、将第二步采集到的数据做性能计算和评分。
4、将性能检测结果存入数据库。
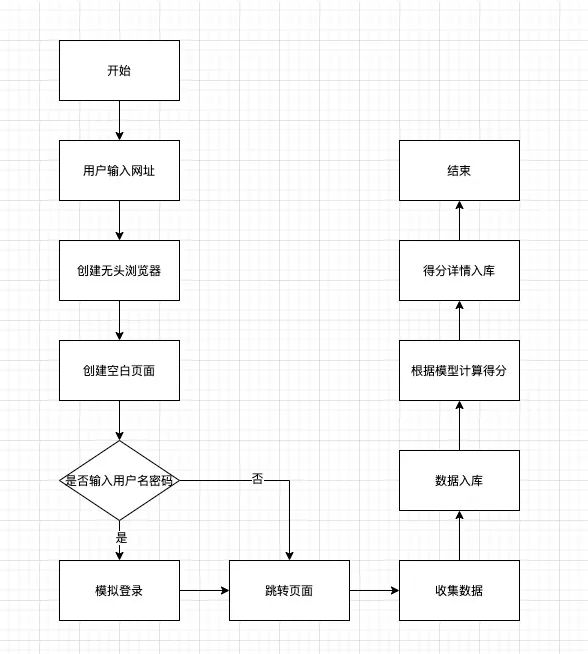
百策采集页面性能数据的实现方案
百策实现页面性能数据采集的方案主要依靠无头浏览器 Puppeteer 结合 Lighthouse,Puppeteer 是 Chrome 团队提供的一个无界面 Chrome 工具,人称无头浏览器,通过 API 来控制 Node 端的 Chrome。百策的主要逻辑是在服务端起一个无需显示的 Chrome,通过 Lighthouse 的 API 新建一个标签页并打开,Lighthouse 会计算具体的性能指标,具体的检测逻辑可以参考下图。接下来我会用关键代码说明如何实现其中的关键步骤。
○ 开始入口
以下是百策价值 1 个亿的代码,主要流程如下,钩子函数是用于在页面打开的不同时间获取性能数据
/**
* 执行页面信息收集
*
* @param {PassContext} passContext
*/
async run(runOptions: RunOptions) {
const gathererResults = {};
// 使用 Puppeteer 创建无头浏览器,创建页面
const passContext = await this.prepare(runOptions);
try {
// 根据用户是否输入了用户名和密码判断是否要登录政采云
await this.preLogin(passContext);
// 页面打开前的钩子函数
await this.beforePass(passContext);
// 打开页面,获取页面数据
await this.getLhr(passContext);
// 页面打开后的钩子函数
await this.afterPass(passContext, gathererResults);
// 收集页面性能
return await this.collectArtifact(passContext, gathererResults);
} catch (error) {
throw error;
} finally {
// 关闭页面和无头浏览器
await this.disposeDriver(passContext);
}
}
○ 创建无头浏览器
创建无头浏览器和页面,并指定浏览器对应的宽高,指定运行的参数,关于浏览器的参数可以参考如下文章:Puppeteer API (https://zhaoqize.github.io/puppeteer-api-zh_CN/#?product=Puppeteer&version=v5.3.0&show=api-puppeteerlaunchoptions)。可以将 headless 设置为 false 看到浏览器的创建和 page 的新建,本地调试可以使用。
/**
* 登录前准备工作,创建浏览器和页面
*
* @param {RunOptions} runOptions
*/
async prepare(runOptions: RunOptions) {
// puppeteer 启动的配置项
const launchOptions: puppeteer.LaunchOptions = {
headless: true, // 是否无头模式
defaultViewport: { width: 1440, height: 960 }, // 指定打开页面的宽高
// 浏览器实例的参数配置,具体配置可以参考此链接:https://peter.sh/experiments/chromium-command-line-switches/
args: ['--no-sandbox', '--disable-dev-shm-usage'],
executablePath: '/usr/bin/chromium-browser', // 默认 Chromium 执行的路径,此路径指的是服务器上 Chromium 安装的位置
};
// 服务器上运行时使用服务器上独立安装的 Chromium
// 本地运行的时候使用 node_modules 中的 Chromium
if (process.env.NODE_ENV === 'development') {
delete launchOptions.executablePath;
}
// 创建浏览器对象
const browser = await puppeteer.launch(launchOptions);
// 获取浏览器对象的默认第一个标签页
const page = (await browser.pages())[0];
// 返回浏览器和页面对象
return { browser, page };
}
○ 模拟登录
模拟登录的场景可以参考另一篇,自动化 Web 性能分析之 Puppeteer 爬虫实践中的第四节,大致的实现逻辑如下:通过无头浏览器打开政采云登录页,通过 Puppeteer API 模拟输入用户名密码,并模拟点击登录按钮。根据同一浏览器下相同的域名共享 Cookie 的特性,再新开标签页打开需要检测的 URL,便可以开始性能检测。
○ 打开页面
如何在 Puppeteer 中使用 Lighthouse 可以参考 Using Puppeteer with Lighthouse (https://github.com/GoogleChrome/lighthouse/blob/master/docs/puppeteer.md)。下面的代码主要检测的是桌面端 Web 页面的性能,后续会放开更改检测环境的功能:可以根据政采云域名来判断页面是手机端还是电脑端,根据不同的系统环境,切换不同的浏览器参数。
/**
* 在 Puppeteer 中使用 Lighthouse
*
* @param {RunOptions} runOptions
*/
async getLhr(passContext: PassContext) {
// 获取浏览器对象和检测链接
const { browser, url } = passContext;
// 开始检测
const { artifacts, lhr } = await lighthouse(url, {
port: new URL(browser.wsEndpoint()).port,
output: 'json',
logLevel: 'info',
emulatedFormFactor: 'desktop',
throttling: {
rttMs: 40,
throughputKbps: 10 * 1024,
cpuSlowdownMultiplier: 1,
requestLatencyMs: 0, // 0 means unset
downloadThroughputKbps: 0,
uploadThroughputKbps: 0,
},
disableDeviceEmulation: true,
onlyCategories: ['performance'], // 是否只检测 performance
// chromeFlags: ['--disable-mobile-emulation', '--disable-storage-reset'],
});
// 回填数据
passContext.lhr = lhr;
passContext.artifacts = artifacts;
}
○ 钩子函数
钩子函数实际是一个抽象类,在运行不同的 Gathering 时,对应的 Class 会实现该抽象类。钩子函数的主要功能在于不同时期注册回调,主要有 2 个钩子函数,beforePass 和 afterPass。beforePass 的作用主要是在页面还没加载前先注册一些监听器,比如说想在页面 load 之后,就拿到 DOM 节点的深度,那就需要在 beforePass 中注册监听。afterPass 主要是页面性能统计完成之后,返回结构化的数据。
/**
* 执行所有收集器中的 afterPass 方法
*
* @param {PassContext} passContext
* @param {GathererResults} gathererResults
*/
async afterPass(passContext: PassContext, gathererResults: GathererResults) {
const { page, gatherers } = passContext;
// 遍历所有收集器,执行 afterPass 方法
for (const gatherer of gatherers) {
const gathererResult = await gatherer.afterPass(passContext);
gathererResults[gatherer.name] = gathererResult;
}
// 执行完所有方法后截图记录
gathererResults.screenshotBuffer = await page.screenshot();
}
○ 收集器的实现
百策总共有 6 个收集器,分别是 Domstats Gathering,Image Elements Gathering,Lighthouse Gathering,Metrics Gathering, Network Recorder Gathering 和 Performance Gathering。
每个收集器都会实现特定的收集功能:
-
Domstats Gathering:收集 DOM 相关的数据,比如 DOM 元素数量,DOM 最大深度,document 是否有滚动条等。 -
Image Elements Gathering:收集所有的图片,并记录下图片的宽高,定位等属性。 -
Lighthouse Gathering:收集 Lighthouse 相关的指标:比如 FCP、LCP、TBT、CLS 等等。 -
Metrics Gathering:收集 JS 事件监听数量,JS 堆栈大小等。 -
Network Recorder Gathering:收集所有页面请求,包括状态码,请求方式,请求头,响应头等。 -
Performance Gathering:主要记录了 window.performance 下的一些数据,用于计算一些时间。
以 Domstats Gathering 做为例子,详细说明如何获取页面检测数据。首先实现抽象类的 2 个方法:beforePass 和 afterPass。beforePass 的实现逻辑是对 page 对象添加 domcontentloaded 时间点的监听方法,监听方法的主要功能是判断 document 是否有横向滚动条。afterPass 方法主要是获取 Lighthouse lhr 中的数据,分析并得到 DOM 最大深度,DOM 节点数等。
import { Gatherer } from './gatherer';
import { PassContext } from '../interfaces/pass-context.interface';
// 实现 Gatherer 抽象类
export default class DOMStats extends Gatherer {
horizontalScrollBar;
/**
* 页面打开前的钩子函数
*
* @param {PassContext} passContext
*/
async beforePass(passContext: PassContext) {
const { browser } = passContext;
// 当浏览器的对象发生变化的时候,说明新打开页面了,此时可以获取到标签页 page 对象
browser.on('targetchanged', async target => {
const page = await target.page();
// 等待 dom 文档加载完成的时候
page.on('domcontentloaded', async () => {
// 通过 evaluate 方法可以获取到页面上的元素和方法
this.horizontalScrollBar = await page.evaluate(() => {
return document.body.scrollWidth > document.body.clientWidth;
});
});
});
}
/**
* 页面执行结束后的钩子函数
*
* @param {PassContext} passContext
*/
async afterPass(passContext: PassContext) {
const { artifacts } = passContext;
// 从 lighthouse 结果对象 lhr 中获取 dom 节点的 depth,width 和 totalBodyElements
const {
DOMStats: { depth, width, totalBodyElements },
} = artifacts;
return {
numElements: totalBodyElements,
maxDepth: depth.max,
maxWidth: width.max,
hasHorizontalScrollBar: !!this.horizontalScrollBar,
};
}
}
等待所有 Gathering 都执行完成之后,数据就可以落库了。
○ 根据模型计算得分
数据入库后还要根据不同的模型计算不同的得分。前台页面重展示,并且图片加载会比较多,中台页面重表单提交,所以不同的模型一定有不同的计算逻辑。在政采云,前台页面我们使用的框架是 Vue, 中台页面使用的是 React(部分页面由于历史原因用的还是 jQuery)。所以大致可以根据框架来区分模型。判断框架是 Vue 还是 React 可以根据 DOM 是否包含 _reactRootContainer 和 __vue__ 来判断。
/**
* 计算得分方法,根据模型上的得分配置项最终生成得分并入库
*
* @param {Artifact} artifact
* @param {string[]} whitelist
*/
async calc(artifact: Artifact, whitelist?: string[]): Promise
{
// 根据每条 metaid 动态加载不同的计算方法文件,每个 metaid 指的就是一个性能评分指标,比如说是否有横向滚动条
const audit =
await
import(
`../audits/${this.meta.id}`).then(
m => m.default);
// 执行每个计算方法文件中的 audit 方法,计算得分,比如没有横向滚动条的时候得5分,有横向滚动条不得分
const { rawValue, score, displayValue, details = [] } = audit.audit(artifact, whitelist);
const auditDto =
new AuditDto();
auditDto.id =
this.meta.id;
// 检测指标名称展示
auditDto.title =
this.meta.title;
// 检测指标描述
auditDto.description =
this.meta.description;
// 检测指标详情
auditDto.details = details;
// 检测指标登记,判断是否计算入得分
auditDto.level =
this.level;
// 扣分上限根据不同的 meta,可能上限也有不同,upperLimitScore 指的是扣分上限,从数据库获取
auditDto.score = score *
this.weight <= -
this.upperLimitScore ? -
this.upperLimitScore : score *
this.weight;
// 得分情况
auditDto.rawValue = rawValue;
// 得分如何展示
auditDto.displayValue = displayValue;
return auditDto;
}
以下是政采云前台模型,每一项都是一个检测指标,告警项只做提示,不实际扣分,前台主要以图片加载和展示为准,所以模型设计上,会更加侧重页面加载时间的关键指标,并且会着重考虑图片的展示。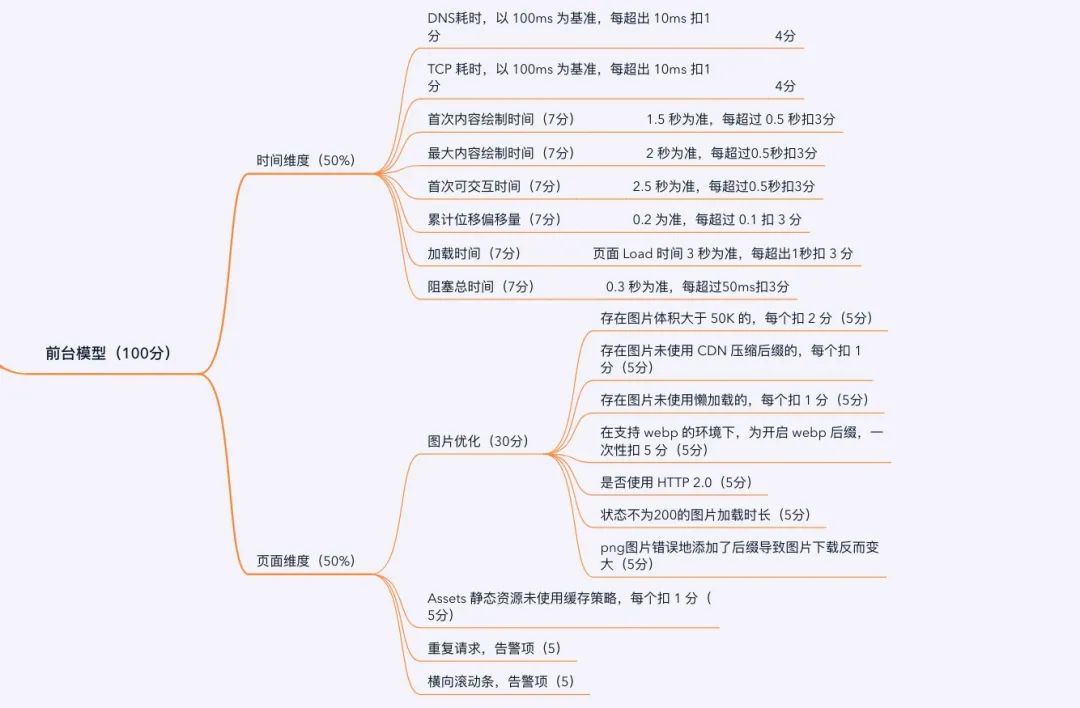
前面内容主要介绍了百策的数据采集和评分功能,这也是百策最主要的功能。除了核心功能外,百策还有数据看板、提供性能解决方案、性能走势,性能对比,定时监测等功能。在这篇文章中我也不一一阐述了。
○ 自动检测
当然除了上面这些手动检测以外,百策也支持自动检测。自动检测的主要目的是统计所有收录在系统中的页面,统计哪些页面性能优化的最好,哪些优化欠佳。具体的逻辑:每周五 2 点会对所有收录在百策中的页面进行检测,将检测成绩最高的 10 个页面,检测成绩最低的 10 个页面,检测成绩进步最快的 10 个页面,自动检测的逻辑主要通过 node-schedule 实现。发送邮件可以 ejs 实现渲染模版,定义好模版后通过 nodemailer 发送即可。
import {
Injectable,
OnModuleInit,
} from '@nestjs/common';
import * as schedule from 'node-schedule';
@Injectable()
export class ScheduleService implements OnModuleInit {
onModuleInit() {
this.init();
}
async init() {
// 本地启动时不执行一系列定时任务
if (process.env.NODE_ENV !== 'development') {
// 每周五02:00开始收集页面性能
schedule.scheduleJob(`hawkeye-weekly-report`, '0 0 2 * * 5', async () => {
// 调用检测接口记录性能评分
await this.report();
});
// 每周五18:00发送周报
schedule.scheduleJob(`hawkeye-weekly-send`, '0 0 18 * * 5', async () => {
// 发送邮件的具体实现方法,主要通过 ejs 渲染模版,通过 nodemailer 发送邮件
await this.send();
});
}
}
}
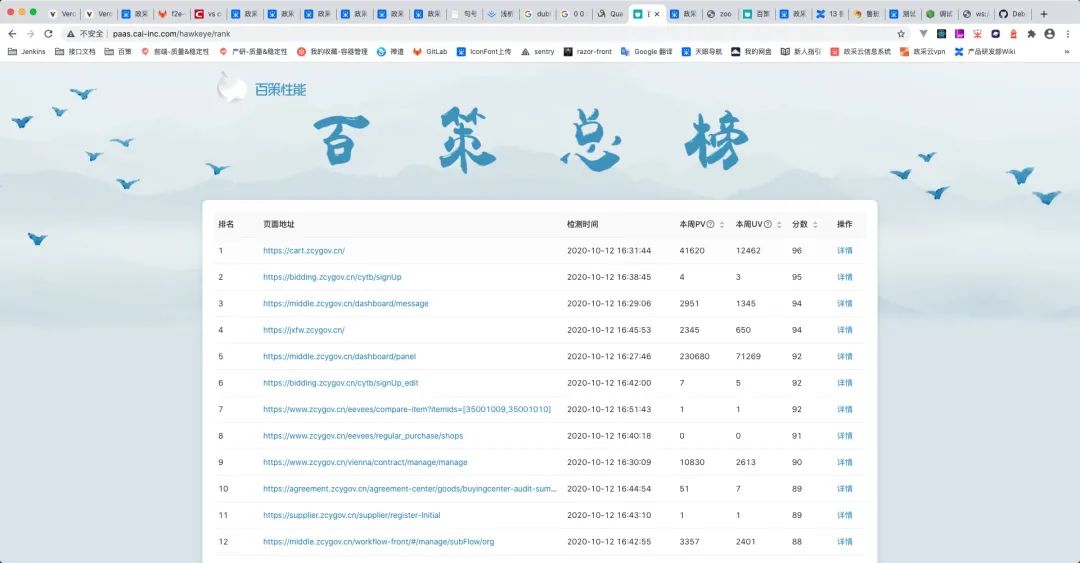
○ 对接鲁班
关于鲁班是什么,可以参考这篇文章:前端工程实践之可视化搭建系统,用一句话来总结,可以说鲁班就是政采云的页面搭建系统。
在对接鲁班时,主要包括了鲁班页面的性能数据的录入和鲁班页面的录入(方便后续每周定时检测)。
-
鲁班性能数据的录入:和在鲁班生成页面时提供一个检测按钮,调用百策性能评分接口,生成检测数据。 -
鲁班页面的录入:在鲁班的新页面上线的时候,会自动调用百策录入接口,新增的页面会被录入到百策系统中。
结尾
如果你也想搭建一个属于自己的性能检测平台,并且恰巧看到了这篇文章,希望此文对你有所帮助。
本文最主要讲的是如何搭建一个性能平台。当你已经能够搭建性能平台之后,不妨可以思考下业务页面的检测模型。

·END·
汇聚精彩的免费实战教程
喜欢本文,点个“在看”告诉我
