最大熵的定以及概念 | 推荐系统

文 | 七月在线
编 | 小七
解析:
1、预备知识为了更好的理解本文,需要了解的概率必备知识有:
①大写字母X表示随机变量,小写字母x表示随机变量X的某个具体的取值;②P(X)表示随机变量X的概率分布,P(X,Y)表示随机变量X、Y的联合概率分布,P(Y|X)表示已知随机变量X的情况下随机变量Y的条件概率分布;③p(X = x)表示随机变量X取某个具体值的概率,简记为p(x);④p(X = x, Y = y) 表示联合概率,简记为p(x,y),p(Y = y|X = x)表示条件概率,简记为p(y|x),且有:p(x,y) = p(x) * p(y|x)。
需要了解的有关函数求导、求极值的知识点有:1) 如果函数y=f(x)在[a, b]上连续,且其在(a,b)上可导,如果其导数f’(x) >0,则代表函数f(x)在[a,b]上单调递增,否则单调递减;如果函数的二阶导f''(x) > 0,则函数在[a,b]上是凹的,反之,如果二阶导f''(x) < 0,则函数在[a,b]上是凸的。
2) 设函数f(x)在x0处可导,且在x处取得极值,则函数的导数F’(x0) = 0。3) 以二元函数z = f(x,y)为例,固定其中的y,把x看做唯一的自变量,此时,函数对x的导数称为二元函数z=f(x,y)对x的偏导数。4) 为了把原带约束的极值问题转换为无约束的极值问题,一般引入拉格朗日乘子,建立拉格朗日函数,然后对拉格朗日函数求导,令求导结果等于0,得到极值。更多请查看《高等数学上下册》、《概率论与数理统计》等教科书,或参考本博客中的:数据挖掘中所需的概率论与数理统计知识。
2、何为熵从名字上来看,熵给人一种很玄乎,不知道是啥的感觉。其实,熵的定义很简单,即用来表示随机变量的不确定性。之所以给人玄乎的感觉,大概是因为为何要取这样的名字,以及怎么用。熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。在信息论里面,熵是对不确定性的测量。
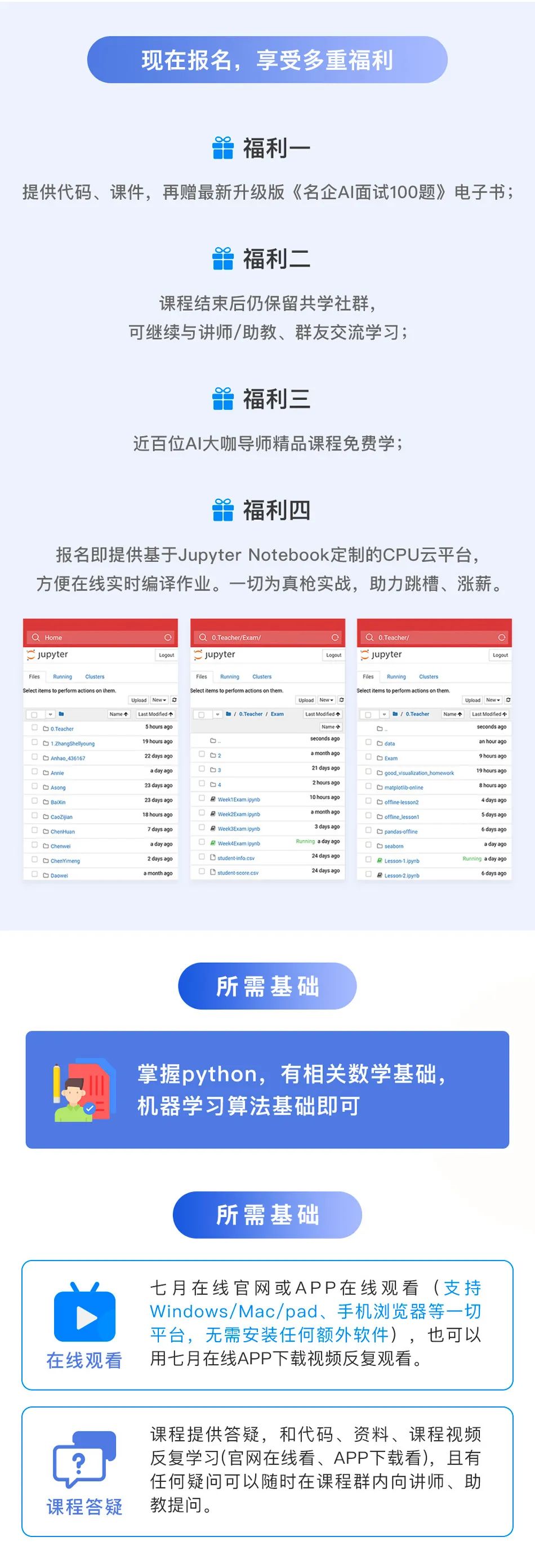
2.1 熵的引入事实上,熵的英文原文为entropy,最初由德国物理学家鲁道夫·克劳修斯提出,其表达式为: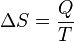
它表示一个系系统在不受外部干扰时,其内部最稳定的状态。后来一中国学者翻译entropy时,考虑到entropy是能量Q跟温度T的商,且跟火有关,便把entropy形象的翻译成“熵”。
我们知道,任何粒子的常态都是随机运动,也就是"无序运动",如果让粒子呈现"有序化",必须耗费能量。所以,温度(热能)可以被看作"有序化"的一种度量,而"熵"可以看作是"无序化"的度量。
如果没有外部能量输入,封闭系统趋向越来越混乱(熵越来越大)。比如,如果房间无人打扫,不可能越来越干净(有序化),只可能越来越乱(无序化)。而要让一个系统变得更有序,必须有外部能量的输入。
1948年,香农Claude E. Shannon引入信息(熵),将其定义为离散随机事件的出现概率。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。所以说,信息熵可以被认为是系统有序化程度的一个度量。
若无特别指出,下文中所有提到的熵均为信息熵。
2.2 熵的定义下面分别给出熵、联合熵、条件熵、相对熵、互信息的定义。熵:如果一个随机变量X的可能取值为X = {x1, x2,…, xk},其概率分布为P(X = xi) = pi(i = 1,2, ..., n),则随机变量X的熵定义为:
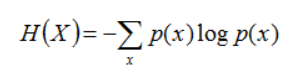
把最前面的负号放到最后,便成了: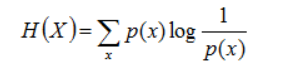
上面两个熵的公式,无论用哪个都行,而且两者等价,一个意思(这两个公式在下文中都会用到)。联合熵:两个随机变量X,Y的联合分布,可以形成联合熵Joint Entropy,用H(X,Y)表示。
条件熵:在随机变量X发生的前提下,随机变量Y发生所新带来的熵定义为Y的条件熵,用H(Y|X)表示,用来衡量在已知随机变量X的条件下随机变量Y的不确定性。且有此式子成立:H(Y|X) = H(X,Y) – H(X),整个式子表示(X,Y)发生所包含的熵减去X单独发生包含的熵。至于怎么得来的请看推导:
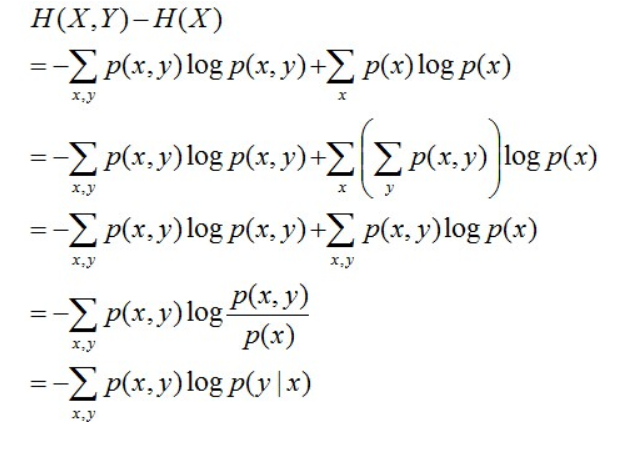 简单解释下上面的推导过程。整个式子共6行,
简单解释下上面的推导过程。整个式子共6行,
其中第二行推到第三行的依据是边缘分布p(x)等于联合分布p(x,y)的和;
第三行推到第四行的依据是把公因子logp(x)乘进去,然后把x,y写在一起;
第四行推到第五行的依据是:因为两个sigma都有p(x,y),故提取公因子p(x,y)放到外边,然后把里边的-(log p(x,y) - log p(x))写成- log (p(x,y)/p(x) ) ;
第五行推到第六行的依据是:p(x,y) = p(x) * p(y|x),故p(x,y) / p(x) = p(y|x)。
相对熵:又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:
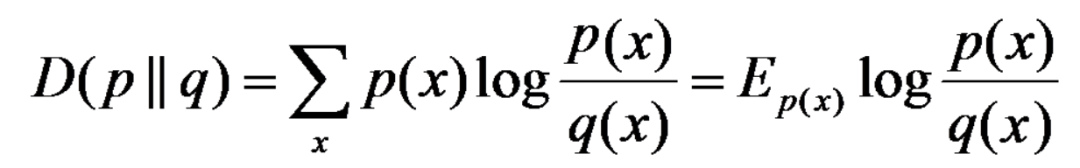
在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。
互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:
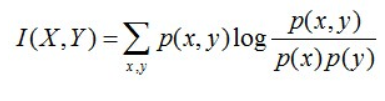
且有I(X,Y)=D(P(X,Y) || P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:
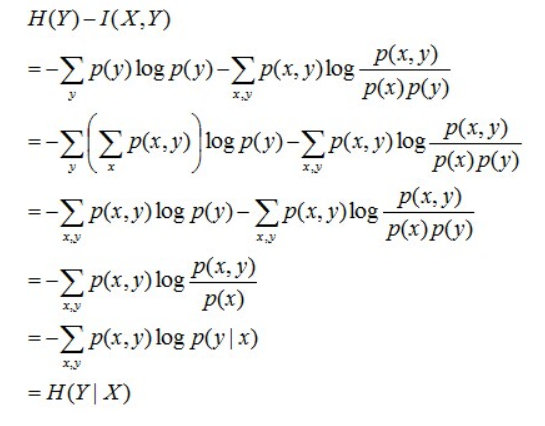
通过上面的计算过程,我们发现竟然有H(Y)-I(X,Y) = H(Y|X)。故通过条件熵的定义,有:H(Y|X) = H(X,Y) - H(X),而根据互信息定义展开得到H(Y|X) = H(Y) - I(X,Y),把前者跟后者结合起来,便有I(X,Y)= H(X) + H(Y) - H(X,Y),此结论被多数文献作为互信息的定义。
3、最大熵
熵是随机变量不确定性的度量,不确定性越大,熵值越大;若随机变量退化成定值,熵为0。如果没有外界干扰,随机变量总是趋向于无序,在经过足够时间的稳定演化,它应该能够达到的最大程度的熵。
为了准确的估计随机变量的状态,我们一般习惯性最大化熵,认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。换言之,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,其原则是承认已知事物(知识),且对未知事物不做任何假设,没有任何偏见。
例如,投掷一个骰子,如果问"每个面朝上的概率分别是多少",你会说是等概率,即各点出现的概率均为1/6。因为对这个"一无所知"的色子,什么都不确定,而假定它每一个朝上概率均等则是最合理的做法。从投资的角度来看,这是风险最小的做法,而从信息论的角度讲,就是保留了最大的不确定性,也就是说让熵达到最大。
3.1 无偏原则
下面再举个大多数有关最大熵模型的文章中都喜欢举的一个例子。
例如,一篇文章中出现了“学习”这个词,那这个词是主语、谓语、还是宾语呢?换言之,已知“学习”可能是动词,也可能是名词,故“学习”可以被标为主语、谓语、宾语、定语等等。
令x1表示“学习”被标为名词, x2表示“学习”被标为动词。
令y1表示“学习”被标为主语, y2表示被标为谓语, y3表示宾语, y4表示定语。
且这些概率值加起来的和必为1,即 ,
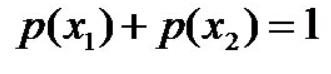
则根据无偏原则,认为这个分布中取各个值的概率是相等的,故得到:
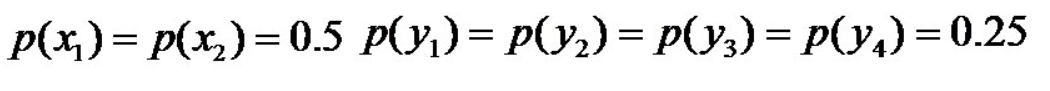
因为没有任何的先验知识,所以这种判断是合理的。如果有了一定的先验知识呢?
即进一步,若已知:“学习”被标为定语的可能性很小,只有0.05,即,
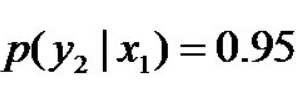
剩下的依然根据无偏原则,可得: 再进一步,当“学习”被标作名词x1的时候,它被标作谓语y2的概率为0.95,即,此时仍然需要坚持无偏见原则,使得概率分布尽量平均。但怎么样才能得到尽量无偏见的分布?
实践经验和理论计算都告诉我们,在完全无约束状态下,均匀分布等价于熵最大(有约束的情况下,不一定是概率相等的均匀分布。比如,给定均值和方差,熵最大的分布就变成了正态分布 )。
于是,问题便转化为了:计算X和Y的分布,使得H(Y|X)达到最大值,并且满足下述条件:
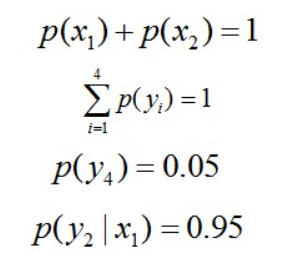
因此,也就引出了最大熵模型的本质,它要解决的问题就是已知X,计算Y的概率,且尽可能让Y的概率最大(实践中,X可能是某单词的上下文信息,Y是该单词翻译成me,I,us、we的各自概率),从而根据已有信息,尽可能最准确的推测未知信息,这就是最大熵模型所要解决的问题。
相当于已知X,计算Y的最大可能的概率,转换成公式,便是要最大化下述式子H(Y|X):
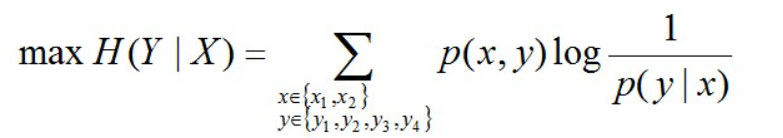
且满足以下4个约束条件:
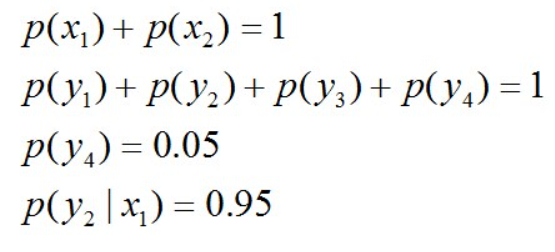
本文素材来源于七月在线面试题,关注公号,获取更多面试资料。本期特训课程
仅需1元限时秒,名额仅剩200个
扫下方二维码即可报名
▲ 学习多种优化方法,掌握比赛上分利器
仅需1元限时秒,名额仅剩200个
扫下方二维码/点击阅读原文即可报名
点击这里阅读原文