
NLP大火的prompt能用到其他领域吗?清华孙茂松组的 CPT 了解一下
Python高校
共 3411字,需浏览 7分钟
·
2021-11-28 13:58
点击“凹凸域”,马上关注
更多内容、请置顶或星标
机器之心报道
编辑:张倩
从 GPT-3 开始,一种新的范式开始引起大家的关注:prompt。这段时间,我们可以看到大量有关 prompt 的论文出现,但多数还是以 NLP 为主。那么,除了 NLP,prompt 还能用到其他领域吗?对此,清华大学计算机系副教授刘知远给出的答案是:当然可以。


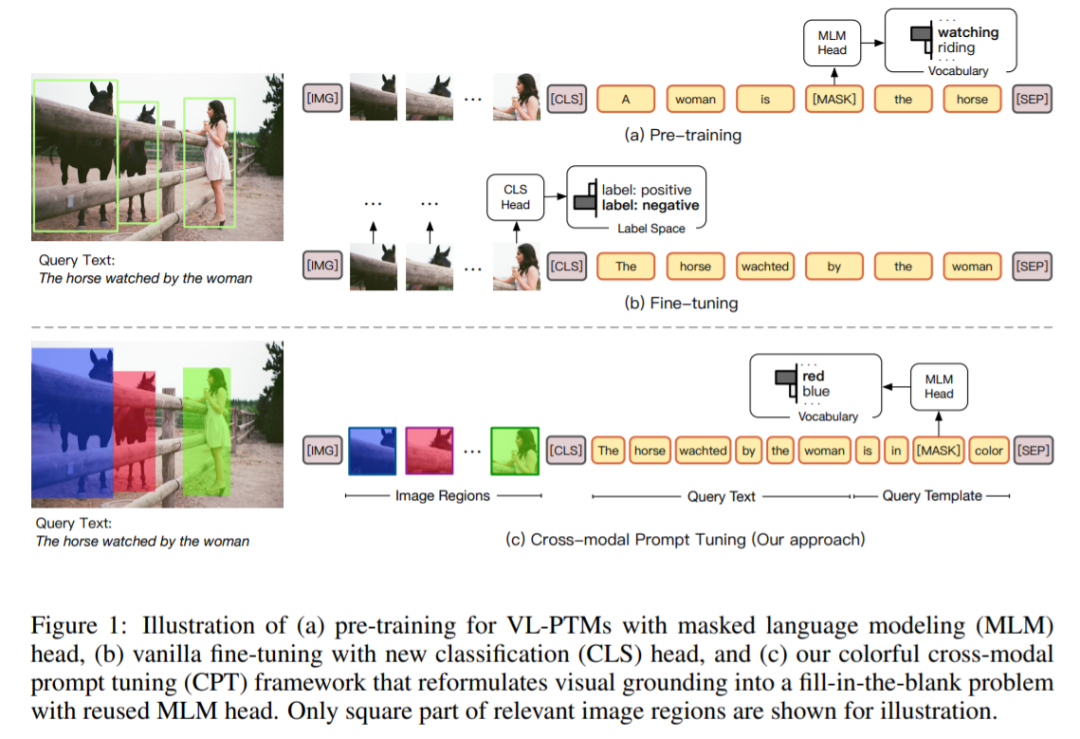
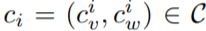 是由它的视觉外观
是由它的视觉外观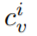 (如 RGB (255, 0, 0))和颜色文本
(如 RGB (255, 0, 0))和颜色文本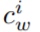 (如:red)来定义的。然后他们用一种独特的颜色
(如:red)来定义的。然后他们用一种独特的颜色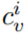 标记图像中的每个区域候选 v_i,以此来定位,这会产生一组彩色图像候选Ψ(R; C),其中 Ψ(·) 表示视觉 sub-prompt。
标记图像中的每个区域候选 v_i,以此来定位,这会产生一组彩色图像候选Ψ(R; C),其中 Ψ(·) 表示视觉 sub-prompt。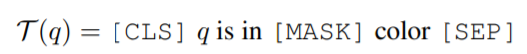

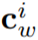 是
是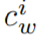 在预训练 MLM head 中的嵌入。需要注意的是,这个过程并没有引入任何新的参数,而且还缩小了预训练和微调之间的差距,因此提高了 VL-PTM 微调的数据效率。
在预训练 MLM head 中的嵌入。需要注意的是,这个过程并没有引入任何新的参数,而且还缩小了预训练和微调之间的差距,因此提高了 VL-PTM 微调的数据效率。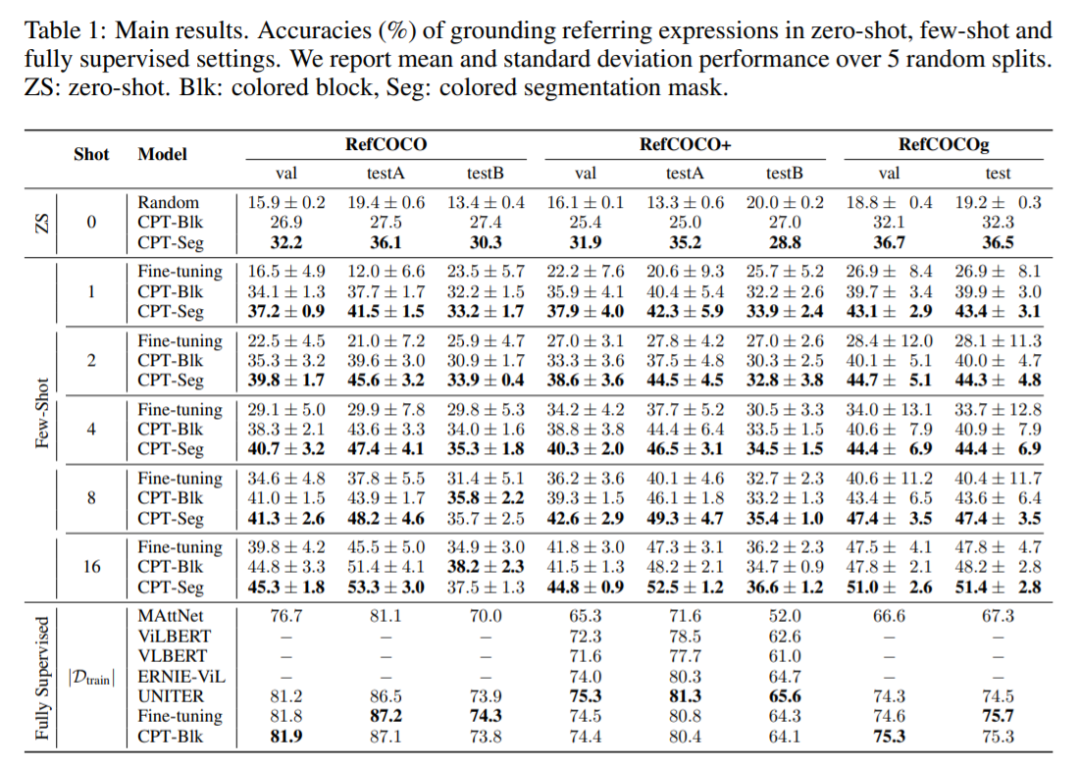
— END —
想要了解更多AI资讯
点这里👇关注我,记得标星呀~
请点击上方卡片,专注计算机人工智能方向的研究
评论