
终于有人把数据湖讲明白了


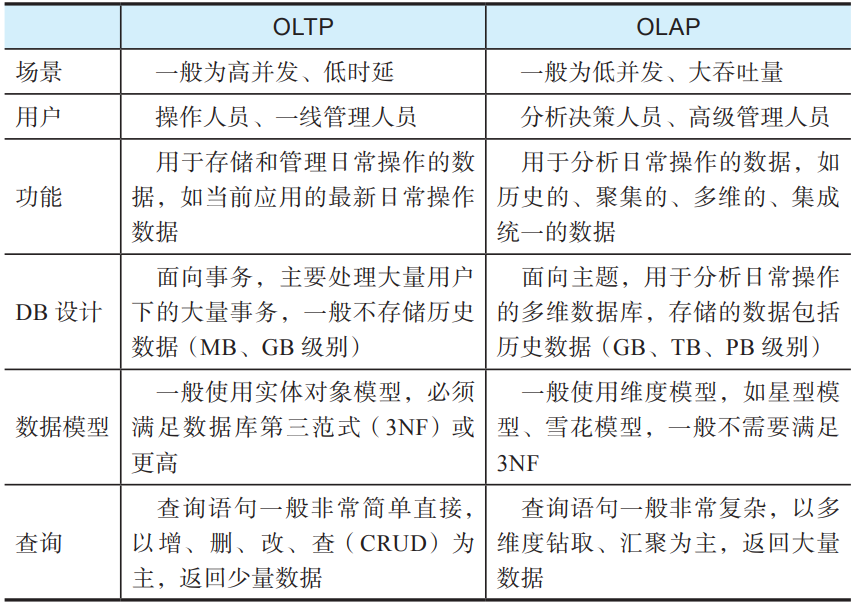
数据仓库的架构设计是事先定好的,很难做到全面覆盖,因此基于数据仓库的分析是受到事先定义的分析目标及数据库Schema限制的; 从OLTP的实时状态到OLAP的分析数据的转换中会有不少信息损失,例如某个账户在某个具体时间点的余额,在OLTP系统里一般只存储最新的值,在OLAP系统里只会存储对账户操作的交易,一般不会专门存储历史余额,这就使得进行基于历史余额的分析非常困难。

高效采集和存储尽可能多的数据。将尽可能多的有用数据存放在数据湖中,为后续的数据分析和业务迭代做准备。一般来说,这里的“有用数据”就是指能够提高业务还原度的数据。 对数据仓库的支持。数据湖可以看作数据仓库的主要数据来源。业务用户需要高性能的数据湖来对PB级数据运行复杂的SQL查询,以返回复杂的分析输出。 数据探索、发现和共享。允许高效、自由、基于数据湖的数据探索、发现和共享。在很多情况下,数据工程师和数据分析师需要运行SQL查询来分析海量数据湖数据。诸如Hive、Presto、Impala之类的工具使用数据目录来构建友好的SQL逻辑架构,以查询存储在选定格式文件中的基础数据。这允许直接在数据文件中查询结构化和非结构化数据。 机器学习。数据科学家通常需要对庞大的数据集运行机器学习算法以进行预测。数据湖提供对企业范围数据的访问,以便于用户通过探索和挖掘数据来获取业务洞见。
数据源的全面性:数据湖应该能够从任何来源高速、高效地收集数据,帮助执行完整而深入的数据分析。 数据可访问性:以安全授权的方式支持组织/部门范围内的数据访问,包括数据专业人员和企业等的访问,而不受IT部门的束缚。 数据及时性和正确性:数据很重要,但前提是及时接收正确的数据。所有用户都有一个有效的时间窗口,在此期间正确的信息会影响他们的决策。 工具的多样性:借助组织范围的数据,数据湖应使用户能够使用所需的工具集构建其报告和模型。

传统数据库数据采集:数据库采集是通过Sqoop或DataX等采集工具,将数据库中的数据上传到Hadoop的分布式文件系统中,并创建对应的Hive表的过程。数据库采集分为全量采集和增量采集,全量采集是一次性将某个源表中的数据全部采集过来,增量采集是定时从源表中采集新数据。 Kafka实时数据采集:Web服务的数据常常会写入Kafka,通过Kafka快速高效地传输到Hadoop中。由Confluent开源的Kafka Connect架构能很方便地支持将Kafka中的数据传输到Hive表中。 日志文件采集:对于日志文件,通常会采用Flume或Logstash来采集。 爬虫程序采集:很多网页数据需要编写爬虫程序模拟登录并进行页面分析来获取。 Web Service数据采集:有的数据提供商会提供基于HTTP的数据接口,用户需要编写程序来访问这些接口以持续获取数据。
HDFS:一般用来存储日志数据和作为通用文件系统。 Hive:一般用来存储ODS和导入的关系型数据。 键-值存储(Key-value Store):例如Cassandra、HBase、ClickHouse等,适合对性能和可扩展性有要求的加载和查询场景,如物联网、用户推荐和个性化引擎等。 文档数据库(Document Store):例如MongoDB、Couchbase等,适合对数据存储有扩展性要求的场景,如处理游戏账号、票务及实时天气警报等。 图数据库(Graph Store):例如Neo4j、JanusGraph等,用于在处理大型数据集时建立数据关系并提供快速查询,如进行相关商品的推荐和促销,建立社交图谱以增强内容个性化等。 对象存储(Object Store):例如Ceph、Amazon S3等,适合更新变动较少的对象文件数据、没有目录结构的文件和不能直接打开或修改的文件,如图片存储、视频存储等。


关于作者:彭锋,智领云科技联合创始人兼CEO。武汉大学计算机系本科及硕士,美国马里兰大学计算机专业博士,主要研究方向是流式半结构化数据的高性能查询引擎,在数据库顶级会议和期刊SIGMOD、ICDE、TODS上发表多篇开创性论文。2011年加入Twitter,任大数据平台主任工程师、公司架构师委员会大数据负责人,负责公司大数据平台及流水线的建设和管理。
宋文欣,智领云科技联合创始人兼CTO。武汉大学计算机系本科及硕士,美国纽约州立大学石溪分校计算机专业博士。曾先后就职于Ask.com和EA(电子艺界)。2016年回国联合创立智领云科技有限公司,组建智领云技术团队,开发了BDOS大数据平台操作系统。
孙浩峰,智领云科技市场总监。前CSDN内容运营副总编,关注云计算、大数据、人工智能、区块链等技术领域,对云计算、网络技术、网络存储有深刻认识。拥有丰富的媒体从业经验和专业的网络安全技术功底,具有超过15年的企业级IT市场传播、推广、宣传和写作经验,撰写过多篇在业界具有一定影响力的文章。
本文摘编自《云原生数据中台:架构、方法论与实践》,经出版方授权发布。


评论