
大模型推理再提速!英伟达推出TensorRT-LLM,专为提升大模型推理速度优化的全新框架
本文来自DataLearner官方博客:
https://www.datalearner.com/blog/1051694310279358
随着大型语言模型(LLM)如 GPT-3 和 BERT 在 AI 领域的崛起,如何在实际应用中高效地进行模型推断成为了一个关键问题。为此,英伟达推出了全新的大模型推理提速框架TensorRT-LM,可以将现有的大模型在H100推理速度提升4倍!2016年,英伟达已经推出了TensorRT,此次发布的TensorRT-LM是在TensorRT基础上针对大模型进一步优化的加速推理库。
TensorRT简介
TensorRT-LLM简介
TensorRT-LLM的加速结果测试
TensorRT简介
TensorRT是英伟达的一个深度学习模型优化器和运行时库,它可以将深度学习模型转换为优化的格式,从而在英伟达GPU上实现更快的推断速度。TensorRT的第一个版本是在2016年11月发布的,当时叫做GPU Inference Engine (GIE)。后来在2017年3月,英伟达将其改名为TensorRT,并发布了TensorRT 2.0版本。从那以后,英伟达一直不断更新和改进TensorRT。
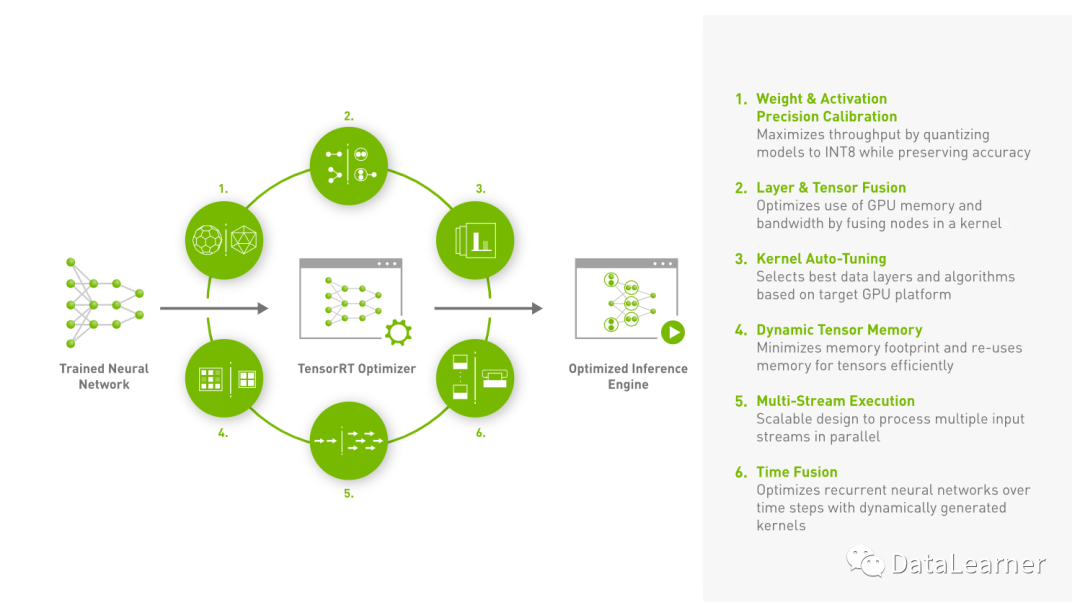
上图是英伟达官方针对TensorRT的示意图,可以看到,TensorRT定位的是将训练结束的模型优化达到加速目的,因此与你使用的训练框架和训练过程不强相关。TensorRT通过自动识别可以合并的连续层,并将它们融合成一个操作。这减少了在 GPU 上的操作数量,从而提高了执行速度。
TensorRT-LLM简介
TensorRT 是 NVIDIA 的一个深度学习模型优化器和运行时库,旨在为深度学习模型在 NVIDIA GPU 上提供快速、高效的推断。而 TensorRT-LLM 则是其针对大型语言模型的扩展,提供了一系列专门的优化和功能。
随着 LLM 的模型参数数量不断增加,传统的推断方法在性能和成本上都面临挑战。TensorRT-LLM 提供了一种方法,可以在保持模型准确性的同时,大大提高推断速度并降低成本。
TensorRT-LLM 首先解析模型结构,然后应用一系列优化技术,如层融合、精度校准和内核选择。它还利用了并行化技术,如张量并行性,以在多个 GPU 之间分配模型的不同部分。
根据官方的说明,TensorRT-LLM的主要特点:
专为 LLM 设计:与标准的 TensorRT 不同,TensorRT-LLM 针对大型语言模型的特定需求和挑战进行了优化。
集成优化:NVIDIA 与多家领先公司合作,将这些优化集成到了 TensorRT-LLM 中,以确保 LLM 在 NVIDIA GPU 上的最佳性能。
模块化 Python API:TensorRT-LLM 提供了一个开源的模块化 Python API,使开发者能够轻松定义、优化和执行新的 LLM 架构和增强功能。
飞行批处理(In-flight batching):这是一种优化的调度技术,可以更有效地处理动态负载。它允许 TensorRT-LLM 在其他请求仍在进行时开始执行新请求,从而提高 GPU 利用率。
支持新的 FP8 数据格式:在 H100 GPU 上,TensorRT-LLM 支持新的 FP8 数据格式,这可以大大减少内存消耗,同时保持模型的准确性。
广泛的模型支持:TensorRT-LLM 包括了许多在今天生产中广泛使用的 LLM 的完全优化、即用版本,如 Meta Llama 2、OpenAI GPT-2 和 GPT-3 等。
并行化和分布式推断:TensorRT-LLM 利用张量并行性进行模型并行化,这使得模型可以在多个 GPU 之间并行运行,从而实现大型模型的高效推断。
优化的内核和操作:TensorRT-LLM 包括了针对 LLM 的优化内核和操作,如 FlashAttention 和遮蔽多头注意力等。
简化的开发流程:TensorRT-LLM 旨在简化 LLM 的开发和部署过程,使开发者无需深入了解底层的技术细节。
TensorRT-LLM的加速结果测试
官方给出了GPT-J 6B在TensorRT-LLM加持下的模型推理速度提升结果,如下图所示:
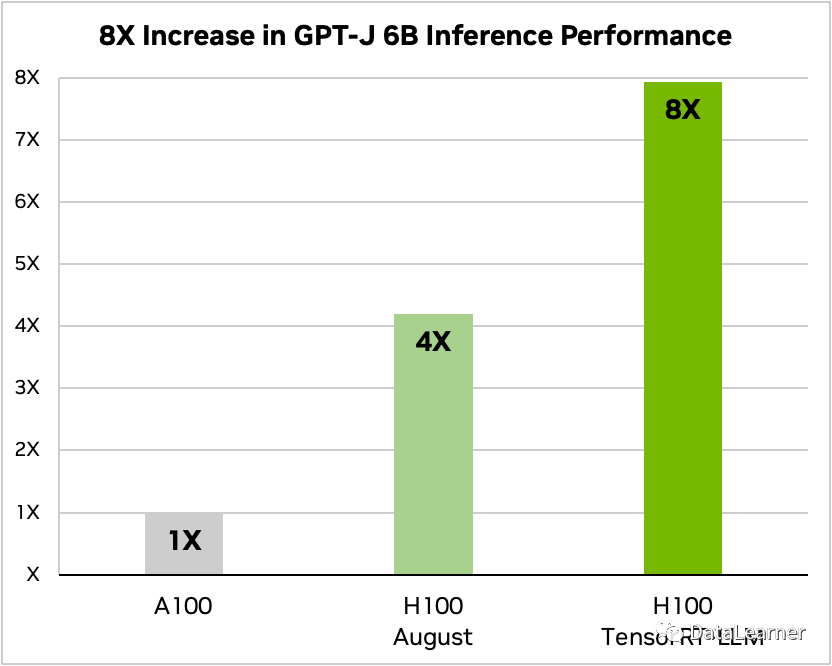
GPT-J 6B是一个由EleutherAI研究小组创建的开源自回归语言模型。它是OpenAI的GPT-3的最先进替代品之一,在各种自然语言任务(如聊天、摘要和问答等)方面表现良好。
上图使用A100作为GPT-J 6B的推理速度基准,H100的推理速度是A100的4倍,而使用了TensorRT-LLM之后的H100推理速度是A100的8倍!提升速度惊人!
而LLaMA2也有很高的速度提升,如下图所示:
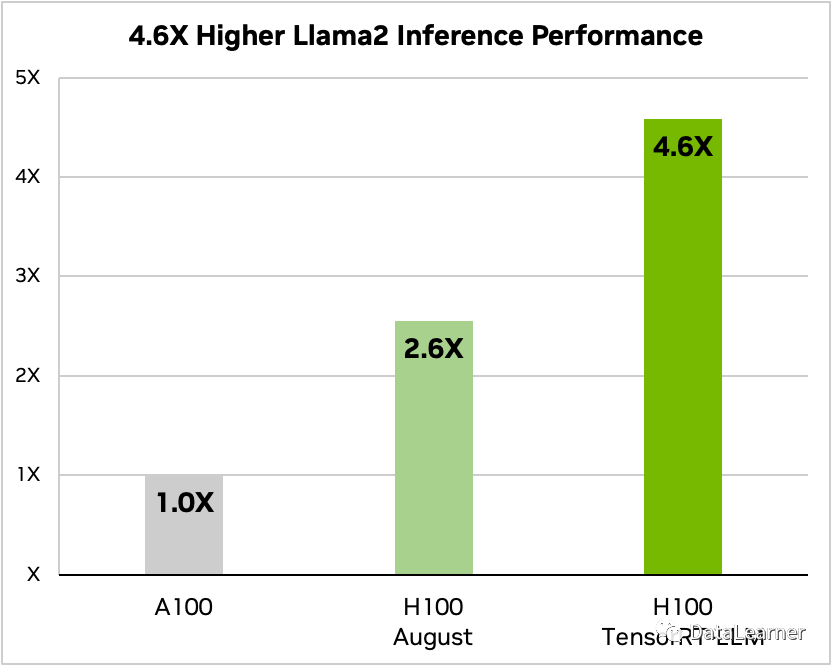
使用A100作为LLaMA2 7B的推理速度(文本摘要)基准,H100的推理速度是A100的2.6倍,而使用了TensorRT-LLM之后的H100推理速度是A100的4.6倍!提升速度也是非常惊人!
目前TensorRT-LLM属于早期预览,只要注册成为NVIDIA开发者即可申请使用~
号外!