
手写中文文本识别:一种无需切分标注的方法

一、背景
二、方法
2.1 算法框架
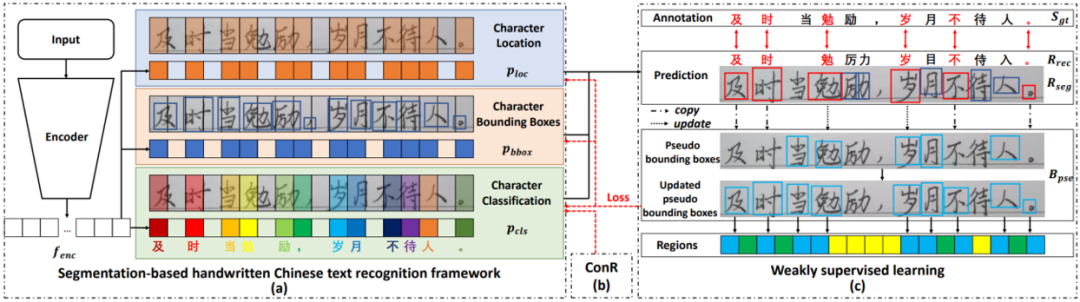 图1 方法的整体结构图
图1 方法的整体结构图该方法的整体框架如图1所示。输入的文本图片(或联机数据的脱机表示形式)经过编码器后分为三个分支,分别预测字符定位、字符边界框和字符类别。因为上述网络通过全卷积的方式实现,所以无法建模上下文语义信息。因此,训练过程中,通过语义正则化(ConR)引导网络在提取的特征中建模上下文信息。最后,文章提出的弱监督学习方法通过合成数据和巧妙的伪标注更新以及模型优化方式,做到无需人工标注真实数据的字符边界框即可训练模型预测文本的单字切分和识别结果,极大地降低了模型实际落地的成本。
2.2 基于切分的手写中文文本识别网络
 图2 基于切分的手写中文文本识别网络结构图
图2 基于切分的手写中文文本识别网络结构图基于切分的手写中文文本识别网络的结构借鉴了参考文献[1]中提出的模型。模型输入首先经过多个残差模块提取特征,再分为三路分别得到字符边界框分支的特征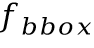 ,字符定位分支的特征
,字符定位分支的特征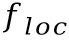 和字符分类分支的特征
和字符分类分支的特征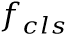 。这些特征的高度均为1,宽度均为
。这些特征的高度均为1,宽度均为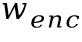 。基于每个分支的特征,再通过卷积层预测出字符边界框坐标
。基于每个分支的特征,再通过卷积层预测出字符边界框坐标 ,字符定位置信度
,字符定位置信度 和字符分类概率
和字符分类概率 。结合这些预测结果,通过设置置信度阈值和NMS操作,即可得到每个字符的边界框和类别,进而得到整个文本行的识别结果。
。结合这些预测结果,通过设置置信度阈值和NMS操作,即可得到每个字符的边界框和类别,进而得到整个文本行的识别结果。
2.3 语义正则化

如上节中的图2所示,识别模型采用全卷积网络的形式实现,缺少CTC/Attention方法中常采用的BLSTM层,因而无法获取上下文的关联信息。因此,如图3所示,文章提出了语义正则化方法。
在训练过程中,该方法于字符分类特征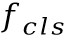 之上添加额外的两层BLSTM层和字符分类层,新的字符分类结果同样计算交叉熵损失
之上添加额外的两层BLSTM层和字符分类层,新的字符分类结果同样计算交叉熵损失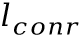 ,增加在原网络的总损失上。因为BLSTM可以建模全局的上下文关联,所以通过梯度回传,可以引导字符分类特征
,增加在原网络的总损失上。因为BLSTM可以建模全局的上下文关联,所以通过梯度回传,可以引导字符分类特征 嵌入上下文信息。
嵌入上下文信息。
在推理过程中,删除额外的BLSTM层和字符分类层,采用原有的直接基于字符分类特征的分类结果。因为BLSTM层无法并行运算,前向效率较低,所以这样的推理方式保持了原有的全卷积结构的高推理速度。实验证明,采用BLSTM前后的分类结果的识别指标差距极小,进一步印证了字符分类特征可以学习到类似BLSTM建模后的上下文信息。
2.4 弱监督学习
弱监督学习的流程如图1(c)所示。模型首先采用简单的合成数据进行预训练,使得模型具有一定的定位和识别字符的能力,然后再采用仅有文本标注的真实数据进行训练,流程如下:
(1)对于真实数据,模型预测出多个字符的边界框和识别结果。文章中观察到,识别正确的字符通常预测的边界框也较为准确。因此通过计算识别结果和标注文本的编辑距离,得出两者中字符的对应关系,进一步得到识别正确的字符(红色的字符)。
(2)采用正确识别的字符的边界框(红色的边界框)对伪边界框标注进行更新。如果现有的伪边界框标注中已经存在该字符的伪标注,则将伪边界框标注更新为现有的伪边界框和新预测的边界框的加权和(权重基于二者的置信度计算),反之则将新预测的边界框直接复制为伪边界框。
三、实验
3.1 数据集
实验采用的真实数据集包括脱机手写中文数据集CASIA-HWDB、联机手写中文数据集CASIA-OLHWDB、ICDAR2013比赛测试集(包含脱机和联机数据)、复杂场景手写中文数据集SCUT-HCCDoc和场景中文数据集ReCTS。
实验采用的合成数据使用简单的将单字数据拼接在白色背景上的方法,无需复杂的数据合成和渲染算法,如图4所示。对于CASIA-HWDB和CASIA-OLHWDB,采用独立于文本行数据的同分布单字数据进行合成。对于SCUT-HCCDoc和ReCTS,采用字体文件和白色背景进行简单地合成。

3.2 ICDAR2013脱机比赛测试集。
该方法在ICDAR2013脱机比赛测试集上的实验结果如表1所示,可视化结果如图5所示。
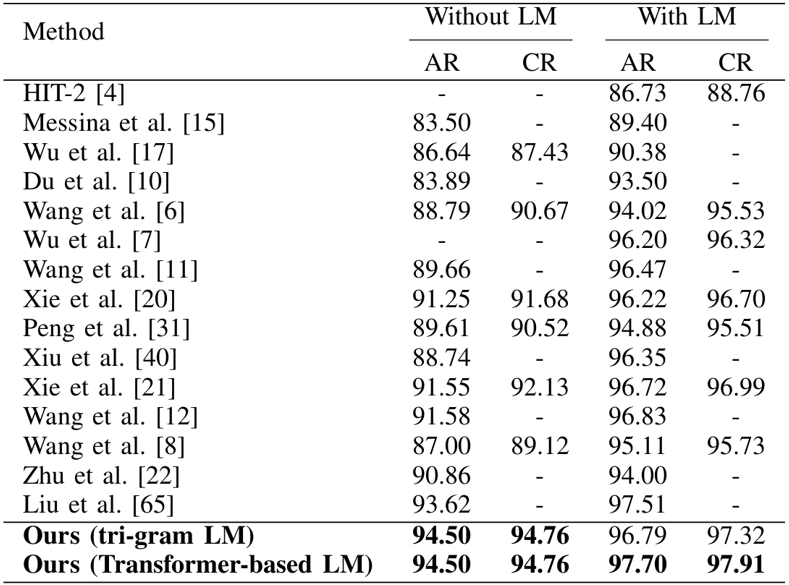
 图5 ICDAR2013脱机比赛测试集可视化结果
图5 ICDAR2013脱机比赛测试集可视化结果3.3 ICDAR2013联机比赛测试集
该方法在ICDAR2013联机比赛测试集上的实验结果如表2所示,可视化结果如图6所示。
表2 ICDAR2013联机比赛测试集实验结果
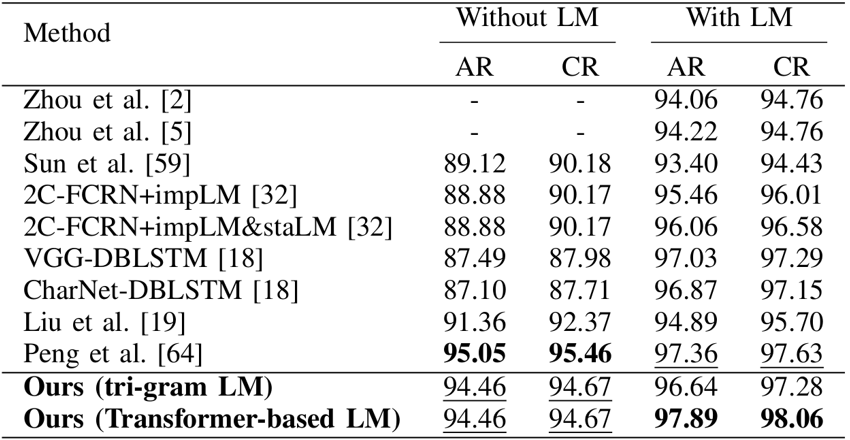
 图6 ICDAR2013联机比赛测试集可视化结果
图6 ICDAR2013联机比赛测试集可视化结果3.4 SCUT-HCCDoc数据集
该方法在SCUT-HCCDoc数据集上的实验结果如表3所示,可视化结果如图7所示。
表3 SCUT-HCCDoc数据集实验结果

 图7 SCUT-HCCDoc数据集可视化结果
图7 SCUT-HCCDoc数据集可视化结果3.5 ReCTS数据集
该方法在ReCTS数据集上的实验结果如表4所示,可视化结果如图8所示
表4 ReCTS数据集实验结果


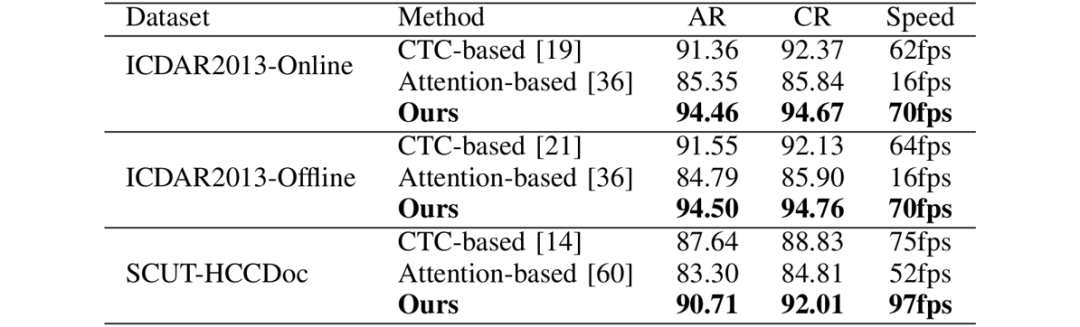
3.6 与CTC/Attention方法的比较
该方法与CTC/Attention方法在精度和速度上的比较如表5所示。可以看出,该方法在精度和速度上均由于目前流行的CTC/Attention方法。
表5 与CTC/Attention方法的在精度和速度上的比较
四、总结及讨论
五、相关资源
论文地址:https://ieeexplore.ieee.org/document/9695187
参考文献
[1]Dezhi Peng, et al. “A fast and accurate fully convolutional network for end-to-end handwritten Chinese text segmentation and recognition.” Proceedings of International Conference on Document Analysis and Recognition. 2019.
撰稿:彭德智
编排:高 学
审校:殷 飞
发布:金连文
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2022 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
