
【ICLR2021】CoCon:一种自监督的可控文本生成方法
ICLR2021的论文《CoCon:A Self-Supervised Approachfor Controlled Text Generation》,提出一种用文本去指导文本生成的无监督方法,是follow了CTRL和PPLM的后续工作。作者设计了一个叫做CoCon的模块,插入transformer中,CoCon结构和正常的transformer encoder一样。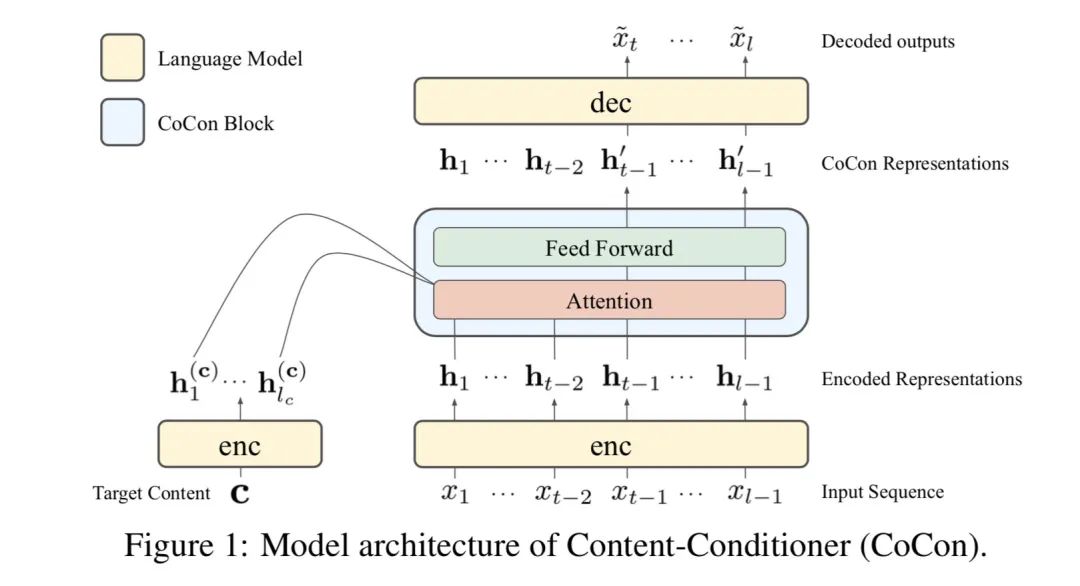
在生成文本时,假设是我们想要的内容,即control部分,c的长度为,句子长度为,被划分为和两个部分,我们使用和去预测部分。具体做法如下:
首先用一个transformer encoder分别编码和,得到了各自的特征和,然后将他们送入CoCon模块通过self-attention融合,将的Key和Value concat到的Key和Value前面,Query不变,依旧来自于
经过feed-forward layer后得到了我们要的包含c的信息的隐变量,普通的transformer就是得到了,然后就当作memory输入decoder去指导文本生成了,CoCon这一步就是把和 concat起来再经过一个transformer encoder,得到了我们要的
decoder的生成过程作者写的让我稍微有些困惑,生成的时候并不是使用,而是把和 concat起来去生成,不知道为什么不直接用去生成。
当我们有多个想要的内容时,也就是有多个c,可以把它们一起concat起来,即
训练的过程作者使用了4个loss,首先把长度为的句子分为两个部分,,,
第一个是重构loss,让,然后让模型condition on 和去生成
第二个是叫做Null Content Loss,,模型只condition on ,让模型学会生成流畅的句子
第三个Cycle loss我觉得是本文最大亮点,不过这个cycle思想应该在以前的很多工作中都有了,作者选出两个句子和,, ,先让模型根据和去生成句子
然后让模型根据和去生成句子,loss cycle的目的是要使其接近
这块理解起来还是有点绕的,首先的生成过程,那么我们是希望的内容能包含的信息,同时要和的衔接保持流畅,接着使用和生成,那么我们希望既能包含的信息,又要和衔接流畅,而又因为包含的信息,因此应该既包含的信息,又能和衔接流畅,那它不就应该是生成了吗?!因此就是计算和相差多大。作者在这里的intuition是:在现实中给出提示文本,可能的衔接文本是非常多的,因此我们希望通过给模型一个,去生成包含的信息且能和衔接流畅的。
最后一个loss是adversarial loss,因为这在其他工作中经常被用,希望模型生成的文本尽可能与真实文本接近
的参数为
最后整个模型的训练是
用来控制每个loss的权重。
作者的实验基于GPT-2,数据选用了openai提供的用GPT-2生成的句子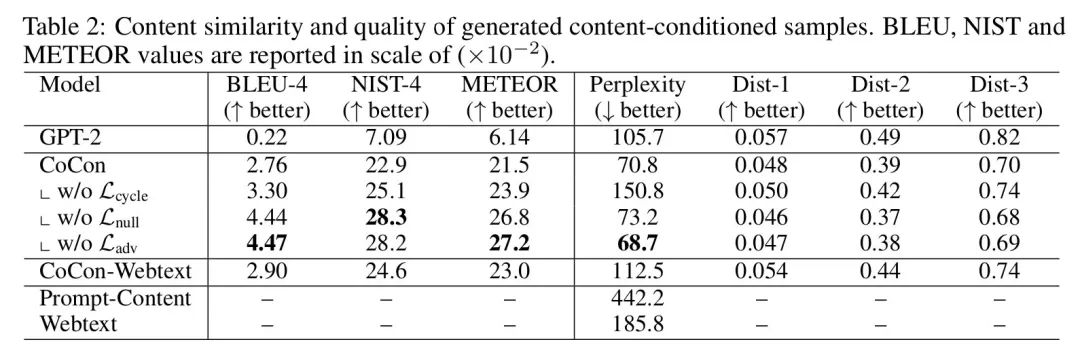
sentiment和topic classifier用了一个在kaggle数据集上训练得到的分类器,发现CoCon生成的句子能更好地控制topic和sentiment
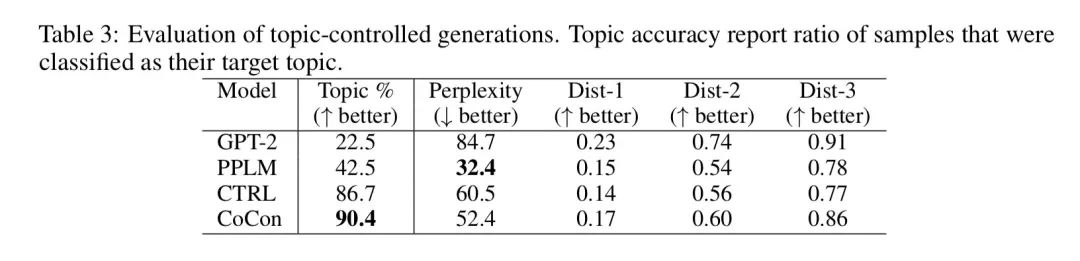
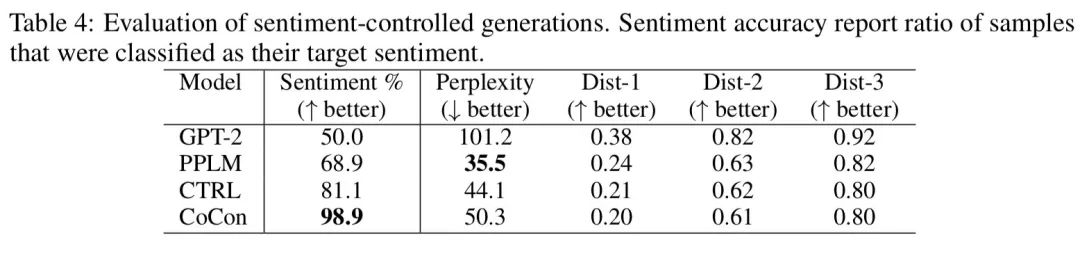
稍微有些遗憾的是作者还没有开源代码,不过ICLR2021才放榜不久,也许后续作者们会补上代码吧。
如果你有什么疑问或想法,欢迎留言交流~
点击阅读原文可查看原论文