
网站被河蟹了,就真的没办法访问了吗?
共 1166字,需浏览 3分钟
·
2021-04-10 12:28

那么就真的没办法获取到之前的文章内容吗?大家是否还记得一句话:互联网都是有记忆的!既然如此那么我们是否可以让互联网回忆起之前的内容呢?当然是可以的,接下来就教大家两招方法轻松应对这个问题。
A
网页快照
首先我们可以思考一下我们是如何找到我们想要的文章的?基本上就是直接通过搜索引擎关键字搜索获取的吧,搜索引擎抓取网站内容后是会定期做一个快照,如果我们网页内容更新后,搜索引擎也会定期去抓取网页内容进行更新。所以我们能够通过关键字搜索到网页内容,那么对应的快照里面可能是有对应内容的。

我们通过搜索引擎找到目标内容后,不要直接点击内容进行跳转,在网页标题的右下角有一个倒三角的图表,点击后就可以选择查看网页快照了,一般情况下是可以找到被和谐之前的内容。
B
互联网档案馆
如果通过上面的方法还找不到你需要的内容,那么就只能寄出我们的杀手锏了 — 互联网档案馆。这个工具可就牛🐂了,可以找到你网站几乎任何时候的快照信息。
比如我在大学刚毕业的时候注册了一个域名 cnych.com 用来写了几篇博客,后来上班过后就没怎么搭理了,导致后来域名也没有续费,这个域名也被售卖了很多次了,这个时候如果我想找回 N 多年前写的博客内容的话,就可以使用这个工具来实现。
在浏览器中打开网站 archive.org,只需要输入我们要查找的网站域名,即可找到该域名的一些历史档案信息,查询后会以日历的形式呈现给我们,日历上带黑条的部分就是有历史档案的时间,只需要选择日期即可找到对应时间点该域名的快照内容了。
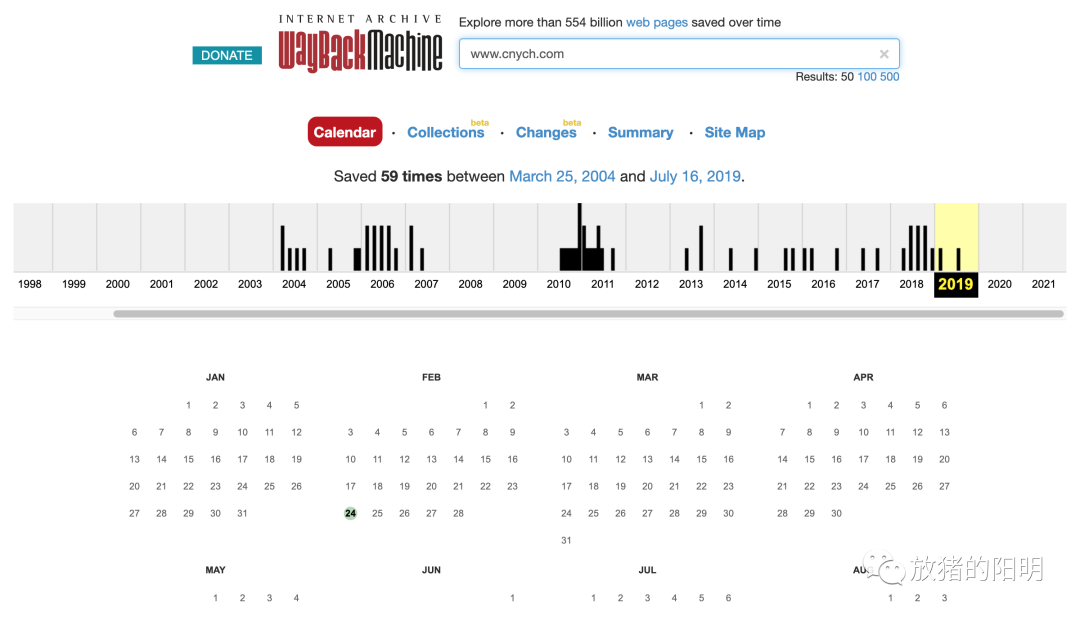
比如我这里选择2010到2011年左右的档案信息,很快就找到了(居然图片这些都还可以访问),当时这个博客访问量其实还可以,域名也比较精简,真可惜没有坚持更新下来,还记得那个时候 36kr 才刚刚起步,大部分是直接把 techcrunch 的文章翻译过来,后来去到北京以后,也天天在车库咖啡看着他们的编辑找项目的场景,现在都已经是上市公司了,服气~~~
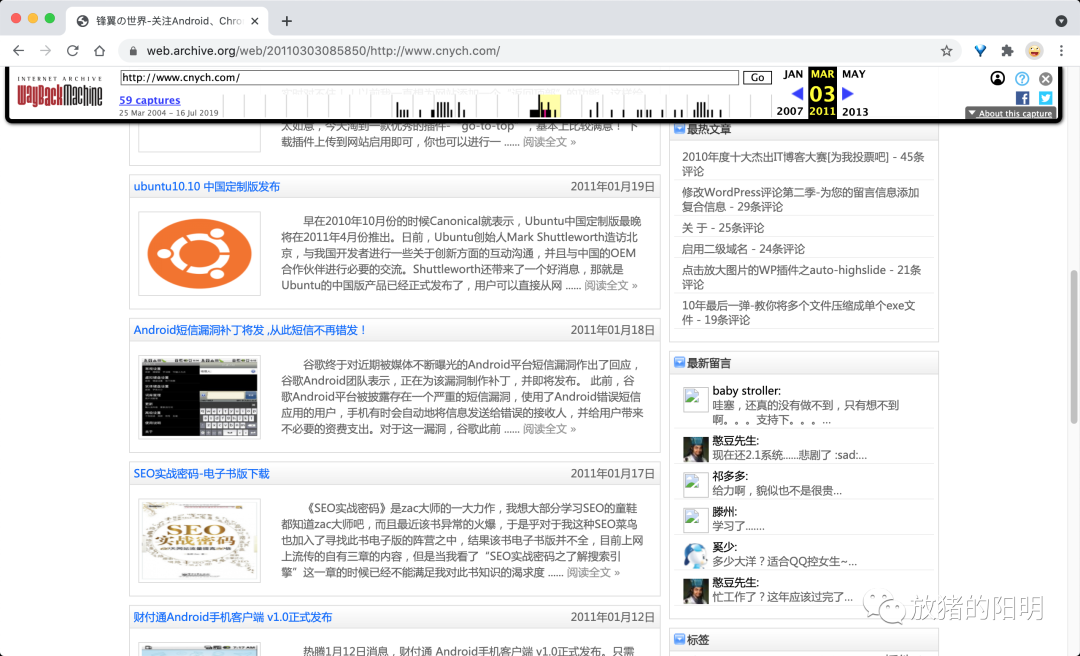
所以最后再送大家一句话,不要在互联网上做坏事,不要心存侥幸,因为互联网并非法外之地,互联网是真的有记忆的~

关于我
一个有点产品思维的程序员
野生自媒体人,还没有拿得出手的作品
坚持写代码,虽然写得很烂
离财务自由还差一个亿小目标
我的小孩很乖
优点知识独立运营者
点击下方卡片关注我吧~