
(附论文)综述 | Transformer模型的多种变体
点击左上方蓝字关注我们

转载自 | 机器之心

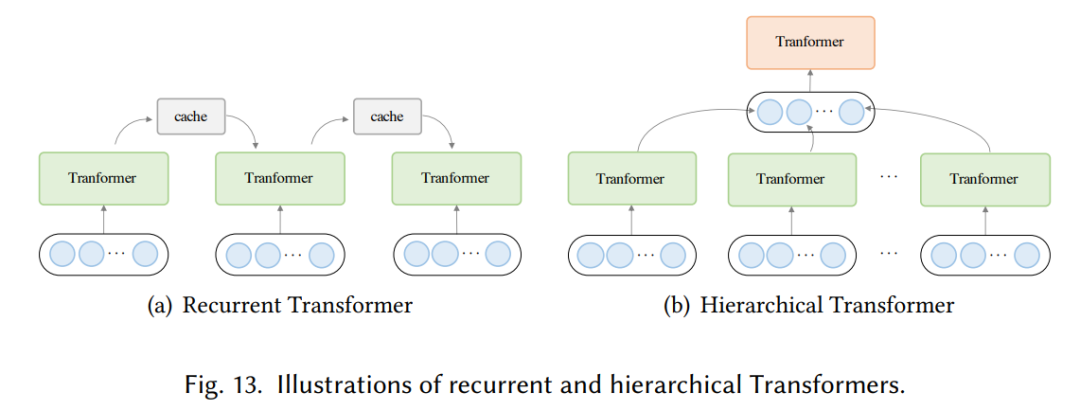
模型效率。应用 Transformer 的一个关键挑战是其处理长序列时的效率低下,这主要是由于自注意力(self-attention)模块的计算和内存复杂度。改进的方法包括轻量级 attention(例如稀疏 attention 变体)和分而治之的方法(例如循环和分层机制);
模型泛化。由于 Transformer 是一种灵活的架构,并且对输入数据的结构偏差几乎没有假设,因此很难在小规模数据上进行训练。改进方法包括引入结构偏差或正则化,对大规模未标记数据进行预训练等;
模型适配。这一系列工作旨在使 Transformer 适应特定的下游任务和应用程序。
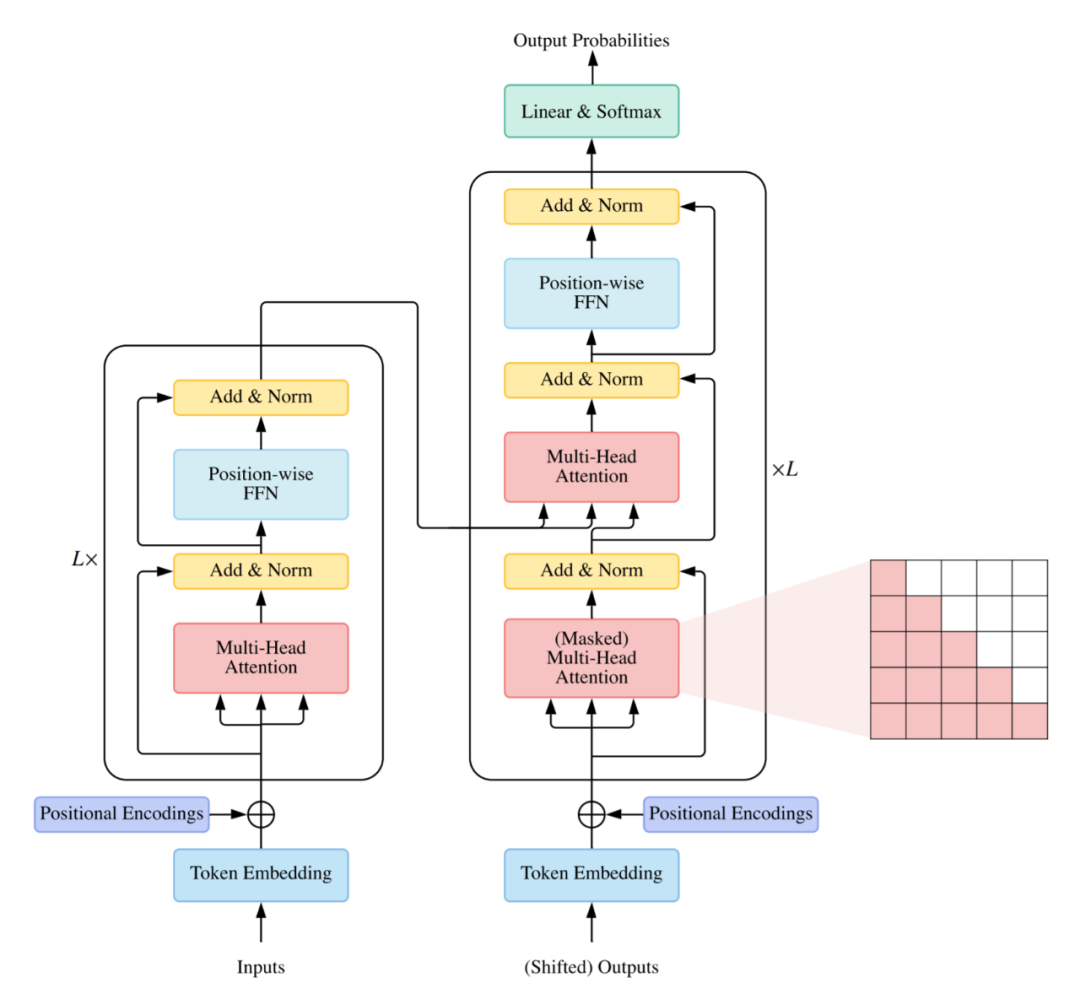
使用编码器 - 解码器,通常用于序列到序列建模,例如神经机器翻译;
仅使用编码器,编码器的输出用作输入序列的表示,通常用于分类或序列标记问题;
仅使用解码器,其中也移除了编码器 - 解码器 cross-attention 模块,通常用于序列生成,例如语言建模。
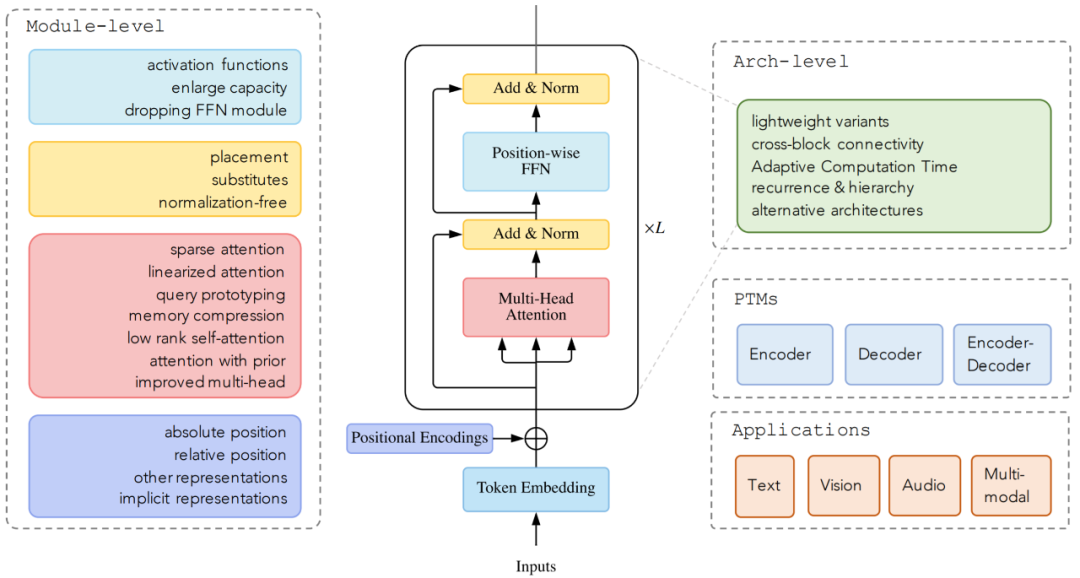

复杂度。self-attention 的复杂度为 O(T^2·D)。因此,attention 模块在处理长序列时会遇到瓶颈;
结构先验。Self-attention 对输入没有假设任何结构性偏差,甚至指令信息也需要从训练数据中学习。因此,无预训练的 Transformer 通常容易在中小型数据集上过拟合。
稀疏 attention。将稀疏偏差引入 attention 机制可以降低了复杂性;
线性化 attention。解开 attention 矩阵与内核特征图,然后以相反的顺序计算 attention 以实现线性复杂度;
原型和内存压缩。这类方法减少了查询或键值记忆对的数量,以减少注意力矩阵的大小;
低阶 self-Attention。这一系列工作捕获了 self-Attention 的低阶属性;
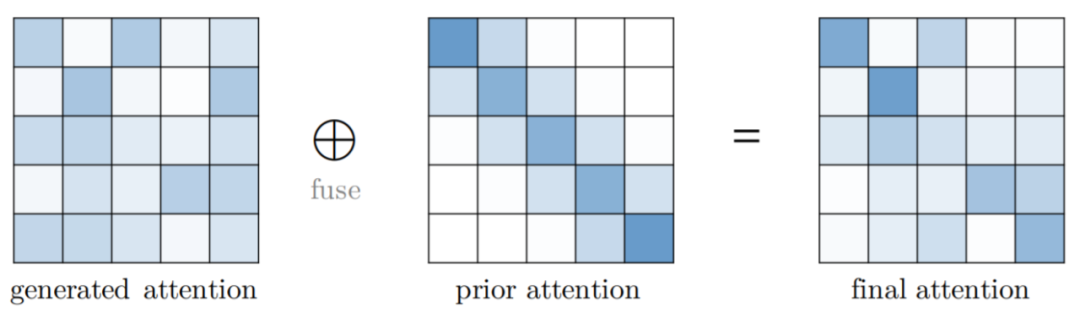
Attention 与先验。该研究探索了用先验 attention 分布来补充或替代标准 attention;
改进多头机制。该系列研究探索了不同的替代多头机制。
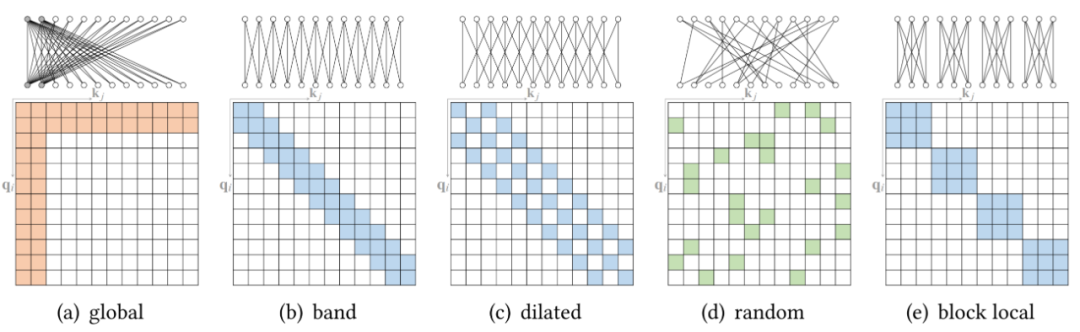

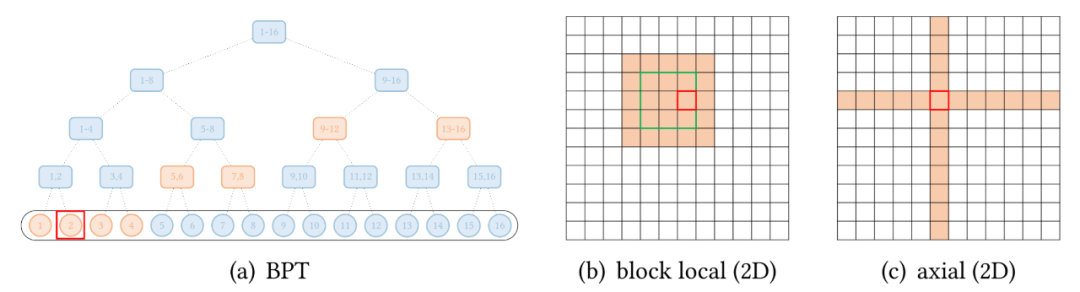
按光栅扫描顺序展平图像像素,然后应用块局部稀疏 attention; 2D 块局部 attention,其中查询块和内存块直接排列在 2D 板中,如上图 (b) 所示。




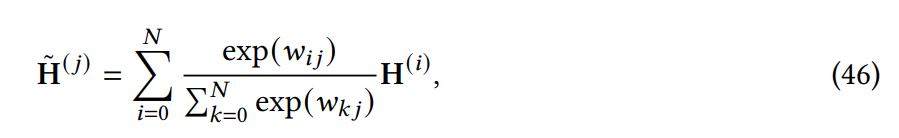

END
整理不易,点赞三连↓