
【Python】利用 Python 分析了一波月饼,我得出的结论是?
作者:Cherich_sun
来源:https://blog.csdn.net/w_yuqing/article/details/119888532
本文为读者投稿
马上八月十五了,又迎来了一年一度的中秋节。中秋节起源于古代对月的崇拜,至今已历史悠久。
中秋节到了,各地都有自己的习俗。但中秋节的习俗共同之处不外乎:祭月、赏月、观花灯、吃月饼。月饼在我印象中,记忆最深的还是"五仁"口味,是家里长辈们的最爱。还记得小时候最讨厌吃到"五仁"里面的"红丝丝绿丝丝"。
后来也吃到有一些非常好吃的月饼,今天特意上网搜了一下,见到好多没吃过的口味,看的眼花缭乱,所以我要忍着口水用 Python 给大家分析看看什么口味最好吃,帮助还没买月饼的小伙伴做个选购参考。
实现方式:Python + Pandas(数据处理) + Matplotlib(可视化) + boken(可视化联动)
一、分析目的
1)哪个种类的月饼销量最高?
2)月饼的价格区间怎么样?
3)TOP 15 口碑较好的品牌?
4)TOP 10 好吃的月饼口味?
5)TOP 10 月饼销量最高店铺?
6)热门品牌月饼价格对比
7)不同口味的月饼品牌推荐(自动)
二、获取数据
数据来源: 京东搜索关键字【月饼】,使用自动采集软件,采集 2000+的数据, 包含月饼标题、店铺名、品牌、价格、销量、类别、产地
# 导入相关库,读取数据
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
import numpy as np
sns.set(font='SimHei',style='darkgrid')
data = pd.read_excel('C:/Users/Cherich/Desktop/月饼数据.xlsx')
data.info()

店铺名、品牌、月饼类别、产地都有缺失值。前两个缺失值较少,可直接删除空值;月饼类别很重要,所以要考虑填充;最后产地,可以基于现有的产地直接分析,对最后的结果,不会有太大影响。
三、数据清洗
1、填充类别
填充的方式通常有两种:一种基于机器学习的相关算法做预测;第二种找规律,比如在大多数标题里包含了月饼类别,所以采取字符串判断,就可以填充了。
data.head()

categorys = data.groupby('category')
category_list = [i[0][:2] for i in categorys]
category_list[-5] = '卡券'
print(category_list)
# ['京式', '其它', '冰淇', '冰淇', '冰皮', '卡券', '台式', '卡券', '港式', '滇式', '潮式', '苏式']
datas = data[data['category'].isnull()==True]
def add_category(df):
name = '其它'
for j in category_list:
if j in str(df):
name = str(j)
return name
datas['category'] = datas['title'].apply(add_category)
datas1 = data[data['category'].isnull()==False]
datas2 = pd.concat([datas1,datas])
datas2
2、填充口味
口味同样也出现在标题里,和上面同样的方法,进行填充。因为口味没有单独的字段,所以要填充口味关键词,不得不说,月饼口味还真是多!
tastes = ["冰皮","冰淇","蛋黄莲蓉","豆沙","黑芝麻","火腿","椒盐","榴莲","玫瑰","流心","奶酪","牛肉","水果","酥皮","五仁","椰蓉","枣蓉","桃仁"]
def add_taste(df):
name =''
for j in tastes:
if j in str(df):
name = str(j)
break
else:
name = '混合口味'
return name
datas2['taste'] = datas2['title'].apply(add_taste)
datas2.head()
3、删除店铺名为空的数据
datas2.dropna(subset=['shop'],inplace=True)
datas2.info()

4、标记价格区间
def price(df):
lable = ''
if 0<df<=50:
lable= '0~50元'
elif 50<df<=100:
lable ='50~100元'
elif 100 < df <=150:
lable = '100~150元'
elif 150 <df <= 200:
lable = '150~200元'
else:
lable = '200元以上'
return lable
datas2['price_lable'] = datas2['price'].apply(price)
datas2.head()
四、数据可视化
1、月饼的价格区间情况
las = datas2.groupby(datas2['price_lable']).size()
las.sort_values(ascending=True,inplace=True)
plt.figure(figsize=(8,6),dpi=80)
plt.title(label='月饼价格区间分布',fontsize=20)
size = 0.3
patches, l_text, p_text = plt.pie(las.values,labels = las.index, shadow=True,
colors=plt.cm.coolwarm_r(np.linspace(0,1,len(las.index))),wedgeprops=dict(width=size, edgecolor='w'),autopct='%.2f%%',startangle=300)
plt.show()
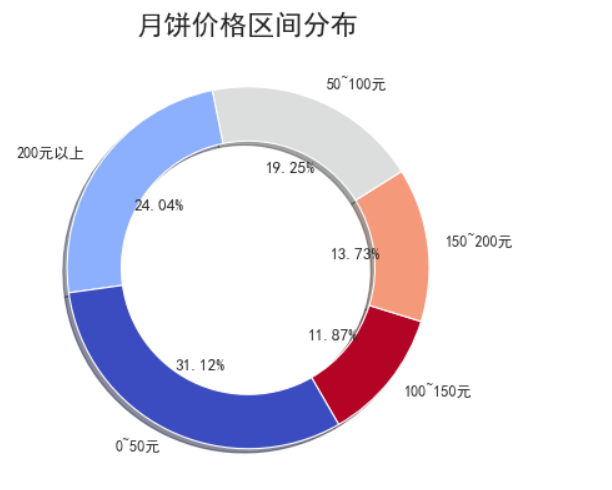
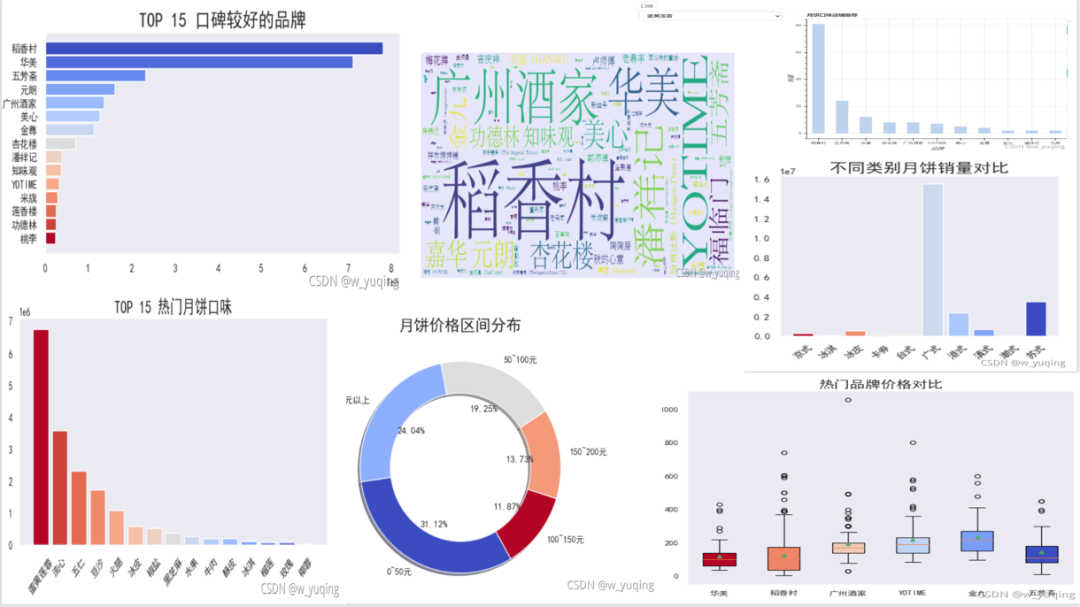
其中31%的月饼在50元以下,看来大多数的月饼还是比较实惠的;居然有24%的月饼在200元以上,月饼这么贵了嘛?
2、月饼种类的销量对比
big_category = datas2[datas2['category']!='其它'].groupby(datas2['category'])
category = [i for i,j in big_category]
numbers = [j['sales'].sum() for i,j in big_category]
plt.figure(figsize = (5,4),dpi=80)
plt.title(label='不同类别月饼销量对比',fontsize=18)
plt.bar(category,numbers, color=plt.cm.coolwarm_r(np.linspace(0,1,len(numbers))))
plt.xticks(rotation=45)
plt.grid()
plt.show()
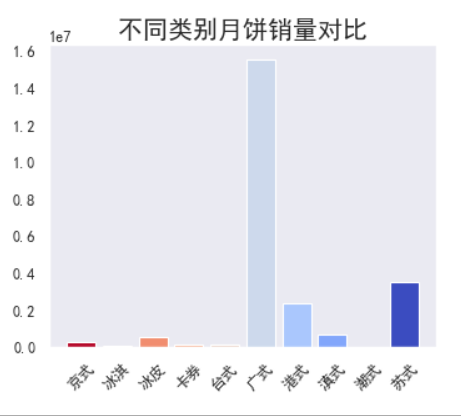
看来挤进前三名的月饼类别是广式、苏式、港式月饼,好奇心驱使,特意查了这些月饼,究竟哪里好吃!

广式月饼:广式的皮薄,皮馅比一般在1:4,馅料多以椰丝、莲蓉、蛋黄、豆沙为主,油多,吃起来口感酥软。

港式月饼和广式比较接近,因为地理上就比较接近,但是港式在广式的基础上进行了改良,低脂、低油是港式的特点。赶紧给女神安排上!

苏式月饼江浙沪一带的特色,最大的特色就是酥皮,外酥内软,很有层次感,越咀嚼越香。

3、TOP 15 口碑较好的品牌
shop = datas2.groupby(datas2['brand'])
shop_dic = {i:j['sales'].sum() for i,j in shop}
shop_dic = sorted(shop_dic.items(), key = lambda kv:(kv[1], kv[0]),reverse=True)
ins = []
val = []
for i, j in shop_dic[:15]:
ins.append(i.split()[0])
val.append(j)
# print(ins)
vals = [round(datas2[datas2['brand']== z]['price'].mean()) for z in ins]
# print(vals)
plt.figure(figsize = (8,4),dpi=80)
plt.title(label='TOP 15 口碑较好的品牌',fontsize=20)
s = plt.barh(ins[::-1],val[::-1],height=0.9, color=plt.cm.coolwarm_r(np.linspace(0,1,len(ins))))
i = 0
plt.grid()
plt.show()
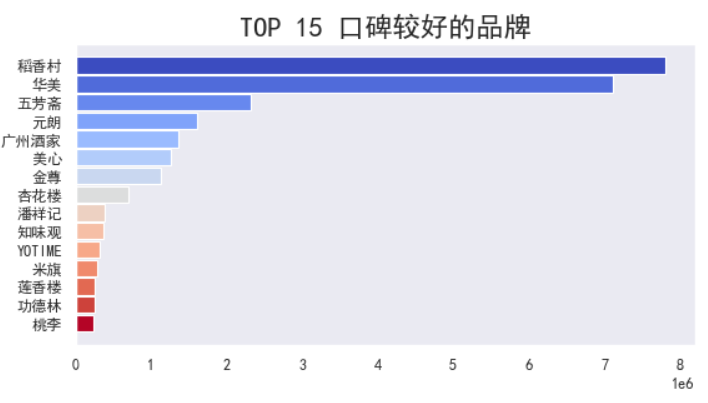
北京的稻香村在所有品牌中的销量位居第一,其次华美、五芳斋、元朗……
4、TOP 10 好吃的月饼口味
shop = datas2[datas2['taste']!='混合口味'].groupby(datas2['taste'])
shop_dic = {i:j['sales'].sum() for i,j in shop}
shop_dic = sorted(shop_dic.items(), key = lambda kv:(kv[1], kv[0]),reverse=True)
ins = []
val = []
for i, j in shop_dic[:15]:
ins.append(i.split()[0])
val.append(j)
plt.figure(figsize = (8,4),dpi=80)
plt.title(label='TOP 15 热门月饼口味',fontsize=18)
plt.bar(ins,val, color=plt.cm.coolwarm_r(np.linspace(0,1,len(ins))))
plt.xticks(rotation=45)
plt.grid()
plt.show()
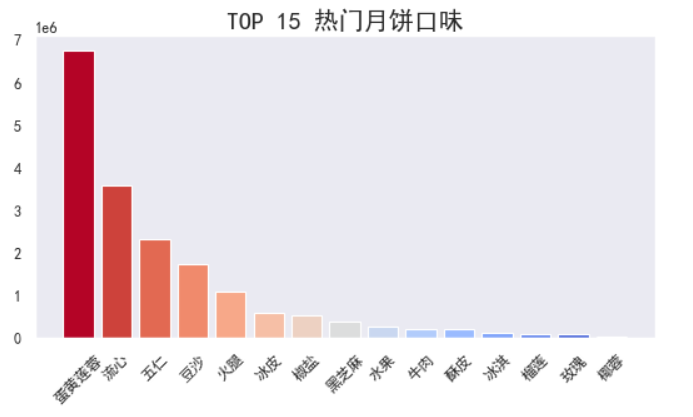
据口味的销量对比,热门口味是莲蓉蛋黄、流心、五仁、豆沙、火腿……
5、TOP 10 月饼销量最高店铺
shop = datas2.groupby(datas2['shop'])
shop_dic = {i:j['sales'].sum() for i,j in shop}
shop_dic = sorted(shop_dic.items(), key = lambda kv:(kv[1], kv[0]),reverse=True)
ins = []
val = []
for i, j in shop_dic[:10]:
ins.append(i.split()[0])
val.append(j)
plt.figure(figsize = (8,4),dpi=80)
plt.title(label='TOP 10 销量最高的店铺',fontsize=18)
plt.barh(ins[::-1],val[::-1],height=0.9, color=plt.cm.coolwarm_r(np.linspace(0,1,len(ins))))
plt.grid()
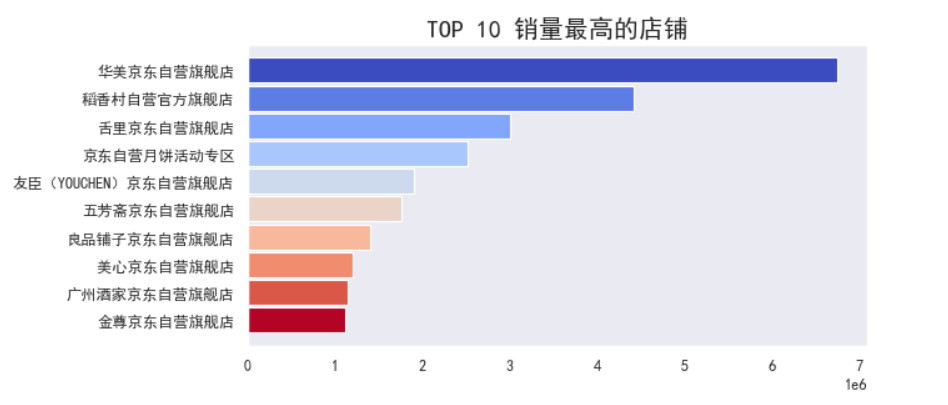
看来稻香村品牌虽然销量第一,但是在店铺销量上,华美旗舰店位居第一
6、品牌销量词云图
from wordcloud import WordCloud
from PIL import Image
li = [each for each in datas2['brand'].values]
def func_pd(words):
count_result = pd.Series(words).value_counts()
return count_result.to_dict()
frequencies = func_pd(li)
plt.figure(figsize = (10,8),dpi=80)
wordcloud = WordCloud(font_path="STSONG.TTF",background_color='#E6E6FA', width=700,height=350).fit_words(frequencies)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()

7、热门品牌月饼价格对比
brand = ['华美', '稻香村', '五芳斋', '美心', '杏花楼', '广州酒家', '元朗荣华', '金尊', '元朗', '哈根达斯', '潘祥记', 'YOTIME', '金九', '中大惠农', '功德林']
datas = datas2[datas2['brand'].isin(brand)]
groups = datas2['price'].groupby(datas2['brand'])
plt.figure(figsize = (8,4),dpi=80)
plt.title('热门品牌价格对比',fontsize=18)
box_1, box_2, box_3, box_4,box_5, box_6 = groups.get_group('华美'),groups.get_group('稻香村'),groups.get_group('广州酒家'),groups.get_group('YOTIME'),groups.get_group('金九'),groups.get_group('五芳斋')
labels = '华美', '稻香村', '广州酒家', 'YOTIME', '金九', '五芳斋'
bplot = plt.boxplot([box_1, box_2, box_3, box_4,box_5,box_6],patch_artist = True,showmeans=True,labels=labels)
colors= plt.cm.coolwarm_r(np.linspace(0,1,len(labels)))
for patch, color in zip(bplot['boxes'], colors):
patch.set_facecolor(color)
plt.grid(False)
plt.show()
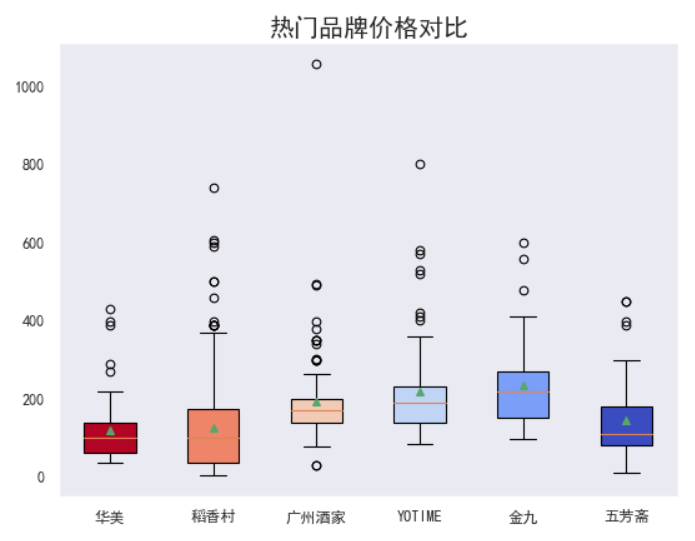
选了几个热门品牌,能看出在价格上:
每个品牌都存在一定的较高异常值,属于对购买能力较高的用户,定制礼盒;
均价最低的是华美和稻香村、五芳斋,看来销量高一部分因素是因为价格。
8、不同口味的月饼品牌推荐(自动)
想实现通过选择自己喜欢的口味,自动推荐销量较好的品牌。选用Boken做联动,bokeh 是一个交互式的可视化库,为浏览器而生。它可以快速的做出可交互的图、仪表板以及数据应用。
import pandas as pd
from bokeh.models.widgets import Panel
from bokeh.models.widgets import Tabs
import warnings
warnings.filterwarnings('ignore')
from bokeh.io import curdoc
from bokeh.plotting import figure
from bokeh.models import ColumnDataSource, Select
from bokeh.layouts import row
import matplotlib as mpl
mpl.rcParams['font.family'] = 'SimHei'
data = pd.read_excel('C:/Users/cherich/Desktop/月饼数据.xlsx')
brand = ['华美', '稻香村', '五芳斋', '美心', '杏花楼', '广州酒家利口福', '元朗荣华', '金尊', '元朗', '哈根达斯', '潘祥记', 'YOTIME', '金九', '中大惠农', '功德林']
data = data[data['brand'].isin(brand)]
# ------------------------------------------------------------------
# 创建下拉小部件: select
types = list(data['taste'].unique())
select1 = Select(options=types, value='莲蓉')
data_qudao = data[data.taste == '莲蓉']
data_qudao_a = data_qudao.groupby('brand').size().sort_values(ascending=False).head(15)
print(data_qudao_a)
data_qudao_b = pd.DataFrame(data=data_qudao_a, columns=['num'])
data_qudao_b['ind'] = data_qudao_b.index
# 创建数据源: source
source1 = ColumnDataSource(data={
'x': data_qudao_b['ind'],
'y': data_qudao_b['num']
})
TOOLTIPS = [
("口味", "@x"),
("销量", " @y")
]
p1 = figure(title='月饼口味店铺推荐', x_range=data_qudao_a.index.to_list(), plot_width=620, plot_height=500,
x_axis_label='品牌', y_axis_label='销量', tooltips=TOOLTIPS)
p1.vbar('x', width=0.5, bottom=0, top='y', source=source1, color='#BCD2EE')
def update_plot1(attr, old, new):
yr = select1.value
data_qudao = data[data.taste == yr]
data_qudao_a = data_qudao.groupby('brand').size().sort_values(ascending=False).head(15)
data_qudao_b = pd.DataFrame(data=data_qudao_a, columns=['num'])
data_qudao_b['ind'] = data_qudao_b.index
source1.data = {
'x': data_qudao_b['ind'],
'y': data_qudao_b['num']
}
p1.title.text = '%s类型统计图' % yr
select1.on_change('value', update_plot1)
layout2 = row(select1, p1)
tab1 = Panel(child=layout2, title='口味')
layout = Tabs(tabs=[tab1])
curdoc().add_root(layout)
启动bokeh服务:
bokeh serve --show aa.py
选择喜欢的口味,图表自动展示销量最高的品牌。一个简单的分析动态图!
五、结论
1、大部分月饼的价格在50元以下,还是非常实惠的;
2、广式月饼最受欢迎,其次是港式月饼,苏式月饼;
3、口碑较好的品牌是:华美、稻香村、五芳斋、美心;
4、热门口味是:蛋黄莲蓉、流心、五仁、豆沙、火腿、冰皮;
往期精彩回顾 本站qq群851320808,加入微信群请扫码: