
【总结】1772- AIGC 如何影响下一代文档搜索方案?
共 9890字,需浏览 20分钟
·
2023-08-16 21:54
对于一个文档站点来说,搜索是一个很重要的功能,它可以帮助用户在繁杂的文档中快速找到自己想要的内容。而随着 AIGC(人工智能生成内容)技术的发展,文档搜索领域也正在悄然发生变化。借助 AI 强大的自然语言处理能力和上下文理解能力,我们可以把文档搜索做得更加智能化,相比传统的搜索方式,可以得到更加符合需求的搜索结果,提升搜索的体验。
传统的搜索思路
在目前的全文检索领域,已经有了一些比较经典的代表方案,比如以轻量和高性能著称的 MeiliSearch、基于 Lucene 的分布式搜索引擎 Elasticsearch,用 JS 实现的文档搜索引擎 FlexSearch 等等。
这些传统的搜索引擎的工作原理都比较类似,主要包括索引和查询两大过程。
首先是索引阶段,搜索引擎会做如下的一些事情:
-
分词:将文档中的内容进行分词,得到一个个的词条,常用的分词器有 IK Analyzer、jieba等。 -
文档分析:对于分词后的词条,会进行一些文档分析,比如去除停用词、同义词替换、大小写转换等。 -
建立倒排索引(Inverted Index):将分词后的词条和文档的关系建立起来,比如对于如下的文档:
MeiliSearch:https://www.meilisearch.com/
Elasticsearch:https://www.elastic.co/cn/elasticsearch/
FlexSearch:https://github.com/nextapps-de/flexsearch
| 文档 ID | 文档内容 |
|---|---|
| 1 | 今天天气不错 |
| 2 | 明天天气也不错 |
| 3 | 昨天天气不好 |
我们可以得到如下的倒排索引信息:
| 词条 | 文档 ID |
|---|---|
| 今天 | 1 |
| 明天 | 2 |
| 昨天 | 3 |
| 天气 | 1, 2, 3 |
倒排索引指根据词条来查找文档的索引,相对于正排索引,正排索引是根据文档来查找词条的索引。
这样,当用户输入 天气 进行搜索时,就可以快速找到包含 天气 的文档。
然后是查询阶段,当用户输入关键词进行搜索时,搜索引擎会做如下的一些事情:
-
分词和分析:将用户输入的关键词进行分词,得到一个个的词条,并进行文档分析,同样也会去除停用词、同义词替换、大小写转换等。 -
文档召回:根据用户输入的关键词,从倒排索引中找到包含关键词的文档。 -
文档排序:对于召回的文档,根据相关性算法进行排序,得到最终的搜索结果。常见的相关性算法有基于词频和文档长度的 BM25、基于词频和文档出现频率的TF-IDF等,细节就不展开了。 -
结果返回:将排序后的结果返回给请求端。
AIGC 如何影响搜索方案?
在传统的搜索方案中,索引和查询阶段都是基于词条来进行的,而一旦出现出现语义相同而词条不同的情况时,就会导致搜索结果不准确。比如下面的这三句话:
- 如何改善搜索结果的相关性?
- 如何提高搜索的准确性?
- 如何解决搜索过程中不相关的结果经常出现的问题?
这三句话的语义是非常相似的,但是由于词条不同,传统的搜索方案就无法将这三句话关联起来,从而会丢失一些相关的搜索结果。
而 AIGC 技术可以很好的解决这个问题,这是因为 AI 大语言模型在经过大量的训练之后,涌现出了语义理解的能力,甚至能根据上下文的语义来进行推理。
在 DeepLearning.AI 的 Prompt Engineering 课程里面,特意提到 Prompt 设计的一个重要原则,即给模型足够的时间思考,这样我们可以得到更加准确的例子,并且给出了一个例子:
让 ChatGPT 给学生阅卷,首先输入问题的描述,然后接着输入学生的解答。在第一次尝试后,ChatGPT 会给出一个错误的答案,但是如果我们将输入问题描述后,告诉 ChatGPT 让它自己先做一遍,然后再判断学生的答案是否正确,这样 ChatGPT 有了足够的思考的余地,再次尝试就得到了正确的答案。
Prompt Engineering :https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/
可见目前的 AI 大语言模型已经能够具备很好的语义理解能力,这也为我们设计更加智能化的搜索方案提供了可能。
基于 AI 的文档搜索架构
那么,我们如何来利用 AI 来进行文档搜索呢?
拿 Modern.js 框架文档来说,如果我们一次性将所有的文档作为上下文输入到 AI 模型中,那么所面临的最大的问题就是计算量太大,对于每次数十万个 token 的输入,会带来巨大的算力消耗,并且无论是 GPT 3.5/GPT 4 都有输入长度限制,无法在单次对话中承载这么多的内容。
另外,通过 Open AI 官方的 Open API 无法做到真正意义上完整的上下文保存,之所以在目前的一些第三方 ChatGPT 聊天软件中我们能感觉到 ChatGPT 记忆了之前的问答内容,是因为在每次提问的时候,前端会将之前的部分问答内容作为请求体的一部分传给 GPT 模型,但也仅仅只能传递一部分,因为单次问答的总 token 数还是有限制的(GPT 3.5 为 4096 个 token)。
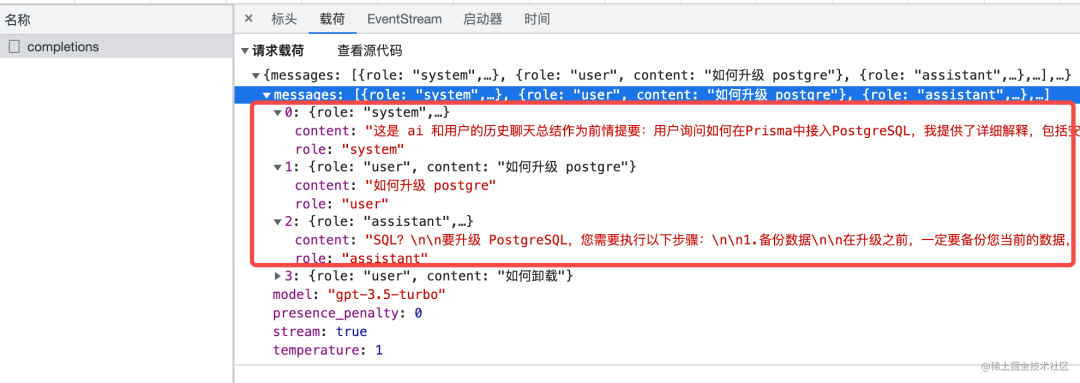
当然,OpenAI 官方也提供的“微调”(Fine-tune)接口,相当于在原来的基础上训练一个新模型出来,但这样做性价比极低,一方面需要输入的训练数据量过大,尤其是对于模型中语料太少的领域,另一方面也不一定达到预期的效果,之前有人"斥巨资",调用 800 万 Tokens,结果还是不能用。
详情:https://www.zhihu.com/question/591066880/answer/2961747033
所以,我们需要一种更加高效且低成本的方式来实现 AI 搜索,目前来看,最优的方案是基于 Embedding + Prompt Tuning 来实现。
Embedding 指的是通过基于神经网络的模型将文本转换为低维向量的过程,我们可以将文档的内容分块,每块内容都转换为一个向量表示,然后以一个 Float 数组的形式进行存储,存储的方式可以是内存、文件、向量数据库(一般选 PostgreSQL 配合 pgvector 插件)。这样在搜索阶段我们就可以直接通过向量的相似度来进行过滤出相关的文档,大大减少了后续的计算量。
Open AI 官方也提供了获取 Embedding 的接口: https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
Prompt Tuning 是一种模型微调的模式,它和之前提到的 Fine-tuning 最大的不同在于,它不需要大量的训练集数据,将微调的重点放到了 Prompt 的内容上,通过提供相对完善且准确的 Prompt,来达到更好的输出效果。回到文档搜索的场景中,在利用 Embedding 过滤出相关的文档后,我们可以将这些文档的内容作为 Prompt 的输入,然后通过 Prompt Tuning 的方式来得到最终的搜索结果。
以上是对于 AIGC 实现搜索而言最重要的两个技术点,下面我们来看如果要实现,整体的架构应该是怎样的:
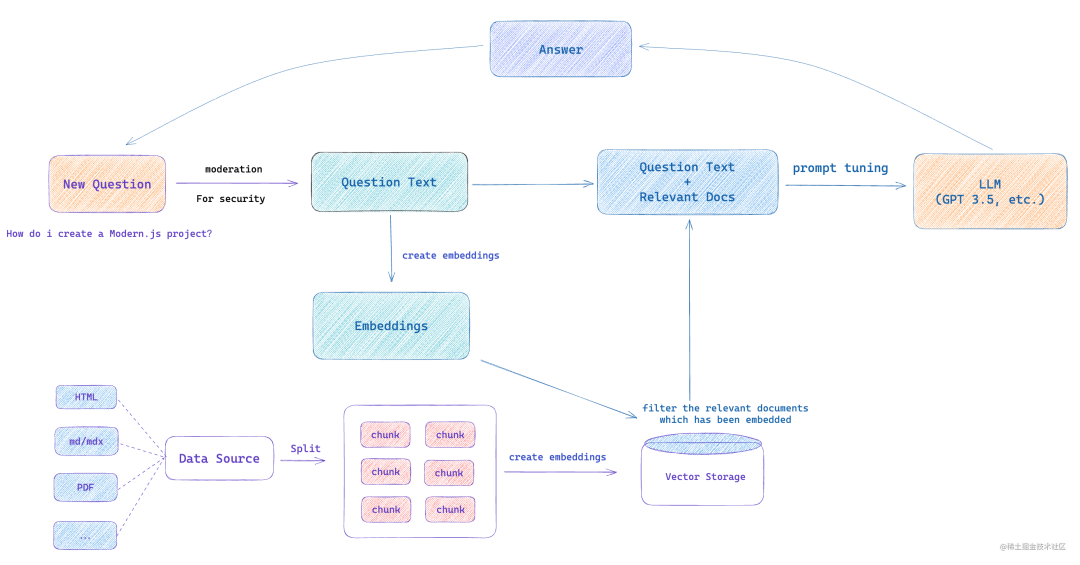
和传统的搜索一样,分为两个阶段: 索引和查询。
在索引阶段,我们需要处理不同类型的数据源,比如 Markdown、HTML、PDF 等,将数据源拆分为一个个内容块(chunk),然后将每个内容块转换为 Embedding,存储到向量数据库中。
用户在输入问题后,我们首先对问题的安全性进行验证,对一些包含敏感词的问题进行拦截,然后将问题的内容进行 Embedding,得到一个向量表示,然后通过向量数据库进行相似度搜索,得到相关的文档,然后将这些文档的内容联合用户问题的内容作为 Prompt 的输入,通过 Prompt Tuning 的方式得到最终的搜索结果。
领域分析
AIGC 领域现在发展非常迅速,在文档搜索领域,或者是专业知识库问答领域,业界已经有了一些雏形产品或者基础设施,虽然目前都还不够完善,但是已经可以看到 AIGC 技术在搜索领域的应用前景,以及其中我们可以借鉴和探索的地方。
基础设施
Supabase
https://supabase.com/
Supabase 是一个开源的后端服务,它提供了一系列的后端服务,包括数据库、身份认证等,官方给的定位是 Firebase alternative,数据库的核心是基于 PostgreSQL 的,同时它也提供了一些 PostgreSQL 的插件,比如 pgvector,这个插件可以支持向量存储,并且提供了向量相似度搜索的功能,这样我们就可以在 PostgreSQL 中存储 Embedding,然后通过 SQL 语句来搜索出相似的文档。
Supabase 整体完成度比较高,官方文档也做得很友好,同时官网的搜索页面也接入了 AI 问答和AI 生成 SQL 的功能:
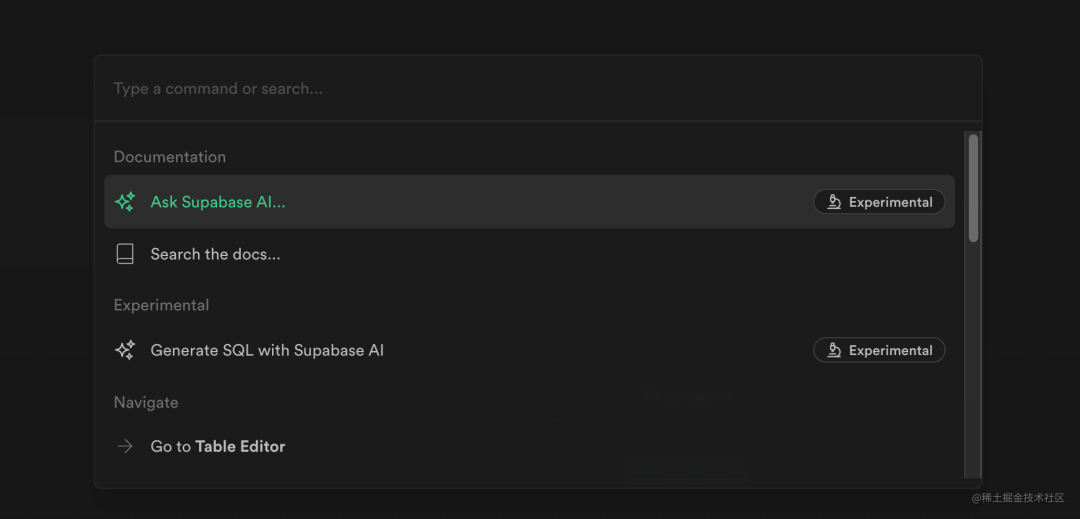
Supabase 给 AIGC 应用提供了基础服务,官网 AI 问答模块的实现也给后来者提供了参考(社区中有人抽出了通用模板代码 ) ,未来我们可以看到越来越多基于 Supabase 的 AI 应用出现。
通用模板代码:https://github.com/supabase-community/nextjs-openai-doc-search 最近比较火的 AI 法律助手(https://github.com/lvwzhen/law-cn-ai) 就是基于上述的 Supabase 通用模板代码实现的。
langchain
首先说说为什么会出现 langchain。
我们不妨梳理一下直接使用 Open AI 官方 API 的一些问题:
-
无法保存上下文,每次请求都是独立的,无法实现真正的上下文对话。 -
无法联网,不能搜索网络上的文档。 -
无法对不同格式的文档进行处理,比如对 Markdown、HTML、PDF 的内容进行拆分,得到一个个 chunk,用于进行 Embedding。......
所以,除了 AI 模型本身的能力之外,我们还需要一些额外的功能来解决如上的诸多工程应用上的问题,这也是 langchain 诞生的原因。
如果说 Open AI 本身提供的 openai 是 AI 的底层框架,那么 langchain 就是 AI 的 元框架(meta framework),解决的是 AI 工程化的问题。
这就好比 React 作为一个前端的底层框架,本身只提供渲染层的能力,至于如何进行路由管理、如果集成原子化 CSS、如何和社区的状态管理库结合、如何做 SSR/SSG,这些工程问题可以由 Modern.js、Next.js 这样的上层元框架来解决。
而 langchain 作为一个高度抽象化的框架,提供了一系列的工具和组件。在知识库问答领域,它最核心的两个概念是Index 和 Chain,分别对应如何建立索引 和 如何进行 Prompt Tuning 两个过程。
在建立文档索引的阶段 langchain 提供了如下的一些组件:
-
Document Loader。Loader 的作用帮助我们从不同的数据源中加载文档,比如从 JSON、Docx、PDF 等文件中加载文档。
-
JSON Loader 示例代码:https://js.langchain.com/docs/modules/indexes/document_loaders/examples/file_loaders/json
-
Text Splitter。langchain 里面有多种 Text Splitter,本质上是帮助我们将文档拆分为一个个的 chunk,比如 MarkdownTextSplitter 将 Markdown 文档拆分为一个个的标题和段落。
-
MarkdownTextSplitter 示例代码:https://js.langchain.com/docs/modules/indexes/text_splitters/examples/markdown
-
Vector Stores。帮助我们将 Embedding 进行存储,比如存放到内存、Supabase 等等位置。
-
Supabase 存储示例代码:https://js.langchain.com/docs/modules/indexes/vector_stores/integrations/supabase
-
Retrievers。帮助我们从不同的 Vector Stores 中检索出相似的文档。
-
Supabase 检索示例代码:https://js.langchain.com/docs/modules/indexes/retrievers/supabase-hybrid
在搜索阶段,langchain 提供了诸多的 LLM Chain 的封装,帮助我们更方便地进行 Prompt Tuning,比如:
-
RetrievalQAChain: 首先从 Vector Stores 中检索出相关的文档,然后将这些文档的内容结合问题作为 Prompt 的输入,进行 Prompt Tuning,得到最终的搜索结果,跟我们之前提到的架构一致,只是使用方式上更加简单。 -
ConversationalRetrievalQAChain: 在 RetrievalQAChain 的基础上,增加了对话的功能,实现上下文对话的能力。
langchain 中涉及的概念比较多,上手门槛并不低,但是它提供了一套完整的工程化方案,可以帮助我们快速搭建一个 AI 知识库问答应用,是未来 AIGC 应用的一个重要基础设施。
上层 AI 应用
目前已经出现了不少关于 AI 搜索的应用,本质上无一例外,都是基于 Embedding + Prompt Tuning 的方式来实现的。接下来我们来看看当前比较典型的几个产品。
Markprompt
-
仓库地址: https://github.com/motifland/markprompt -
官网地址: https://markprompt.com/
基于 Supabase 的 AI 搜索应用,目前还很早期,但核心功能已经达到可用水平:
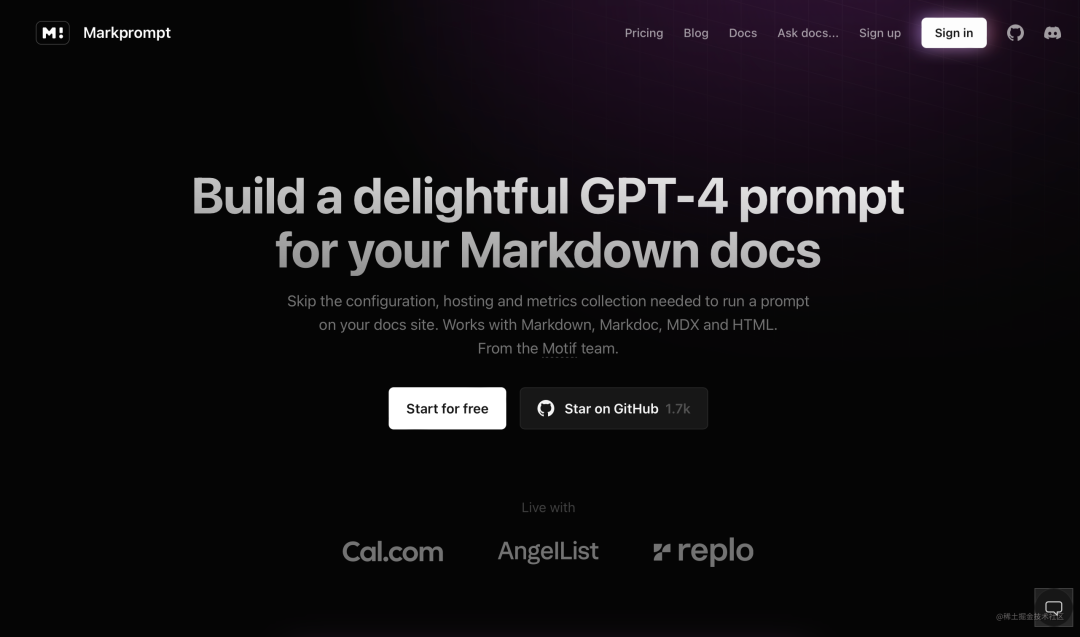
你可以在这个应用里面通过 Github 登录,然后注册一个项目名,进入到项目管理页面上传文档内容,就可以在 Playground 里面试用 AI 问答的功能。同时,它也提供 React 组件接入的方式,传入相应 key 就能一键接入:
import { Markprompt } from "markprompt";
function MyPrompt() {
return <Markprompt projectKey="<projectKey>" />;
}
效果如下:
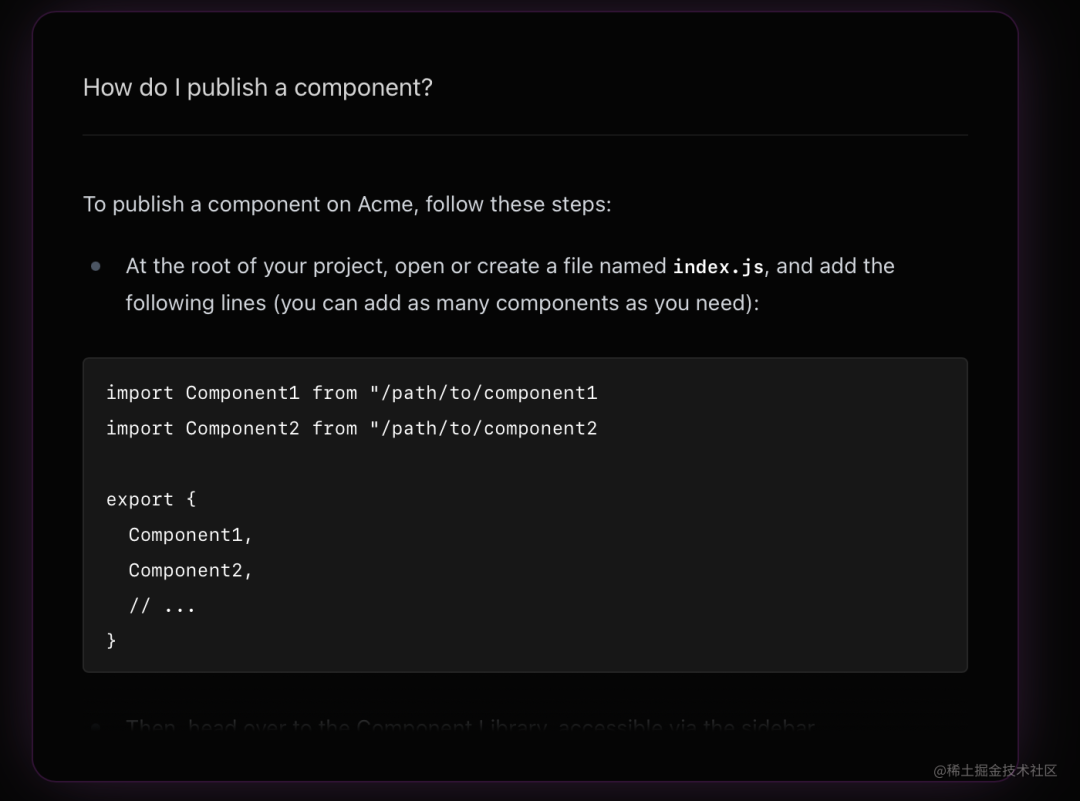
Markprompt 将 AI 搜索的功能做成了一个 SaaS 服务,亮点在于它提供了一套完整的解决方案,涵盖了用户登录、项目管理、文档上传、AI 问答效果预览、前端组件接入的整个流程,对于一些不想自己搭建后端服务的用户来说,可以直接使用这个 SaaS 服务,非常方便。
CopilotHub
官网地址: https://app.copilothub.ai/home
基于知识库的 AI 问答应用,支持自定义知识库数据:
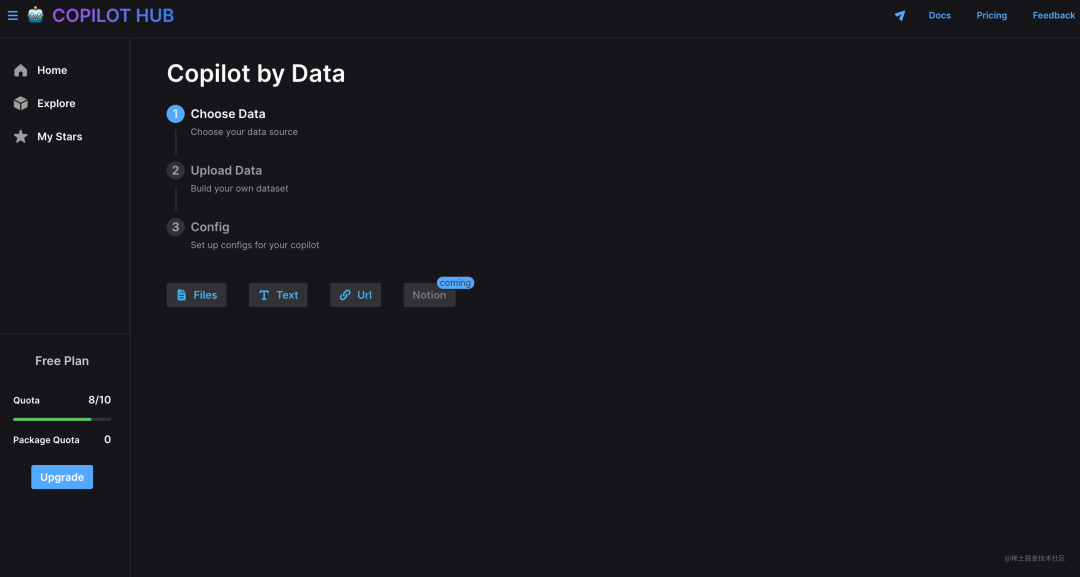
目前完成度不高,产品还非常早期,主要体现在以下的方面:
-
上传文件类型仅支持 pdf 和 epub 类型,不够灵活。 -
仅能在平台内使用,没有提供前端组件接入的方式,无法在第三方网站使用。 -
增加了 Gallery 的概念,大家可以共享一些特定的知识库应用,但 Gallery 里面的知识库应用水平参差不齐,问答效果不够理想。
Mendable
官网地址: https://mendable.ai/
定位和 Markprompt 类似,旨在提供一套完整的 AI 问答解决方案,但是目前还在 Alpha 阶段,功能还不稳定,之前测试连上传一个 Markdown 文件都还做不到,官网文档也不够完善。目前你可以通过 langchain 的官网来体验它的 AI 问答组件,效果如下:
langchain 官网:https://js.langchain.com/docs/
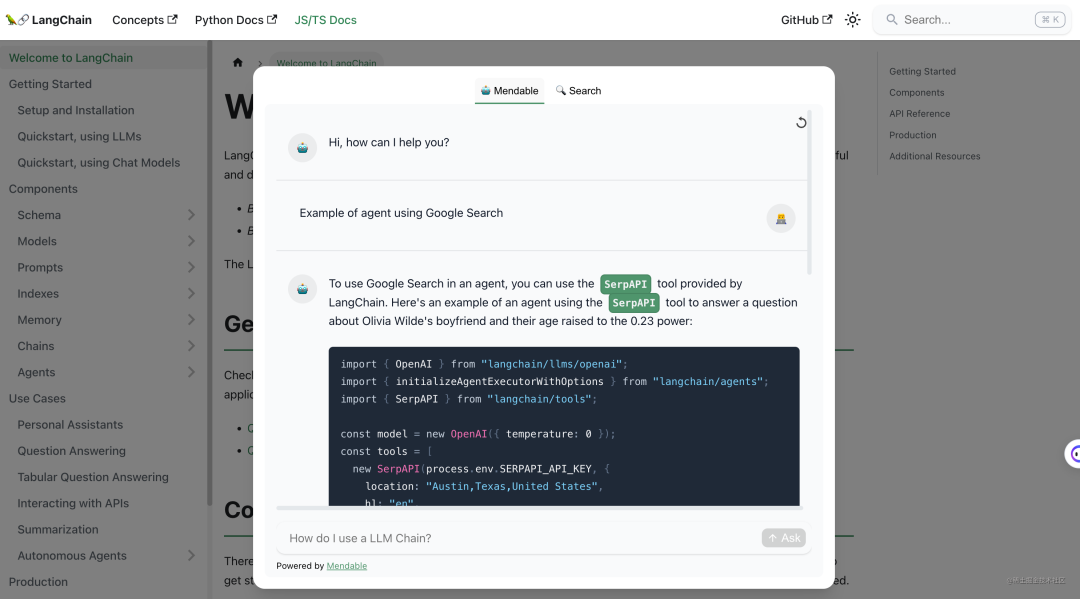
作为一个 AI 知识库问答平台,它的亮点在于支持了一系列的数据源:

包括 Github、Markdown、PDF、Txt,甚至是 Docusaurus 框架文档、YouTube 视频等,这样可以满足不同用户的需求。目前代码没有开源,但是是一个值得期待的产品。
未来搜索形态
客观来讲,基于 AIGC 的搜索并不是银弹,相比于传统的搜索,它也有一些局限的地方,比如:
-
计算量大。需要将文档内容转换为 Embedding,进行向量相似度搜索,然后交给 LLM 模型进行计算,整个过程需要消耗大量的计算资源,随之带来比较高的算力成本。 -
等待时间比较久。传统的 Elasticsearch/MeiliSearch 能达到毫秒级的响应速度,而基于 AIGC 的搜索需要等待数秒才能得到完整的结果。 -
关键词搜索场景。对于某些只需要简单的关键词搜索的场景,基于 AIGC 的搜索就显得大材小用了,毕竟它的成本比传统的搜索高很多,这时候传统的搜索方案更加合适。
这些局限的地方也是传统搜索方案的优势所在。所以,基于 AIGC 的搜索也并不能完全取代传统的搜索方案,将来的搜索形态应该是传统搜索 + AIGC 搜索的结合。
这就好比移动互联网时代,PC 机也没有被完全取代,在很多办公场景下,使用 PC 机的效率还是比移动设备更高。同样的,未来的搜索形态也应该是传统搜索和 AIGC 搜索的结合,根据用户的资深程度、搜索内容需求的不同,选择的搜索方案也有所不同。
小结
基于 AIGC 的文档搜索服务在未来是一个非常有前景的领域,目前已经有了一些雏形产品,但是整体还处于早期阶段,未来还有很多工作值得我们去投入,我们也期待未来能有更加成熟的产品,给文档/知识库搜索的体验带来质的提升。
回复“加群”,一起学习进步