
老黄深夜炸场,AIGC进入iPhone时刻!Hugging Face接入最强超算,神秘显卡胜过A100

新智元报道
新智元报道
【新智元导读】昨天深夜,重返SIGGRAPH舞台的老黄,再次给全世界带来了「亿点点」震撼。
生成式AI的时代已经来临,属于它的iPhone时刻到了!
就在8月8日,英伟达CEO黄仁勋,再次登上了世界顶级计算机图形学会议SIGGRAPH的舞台。

英伟达最强AI超算再升级


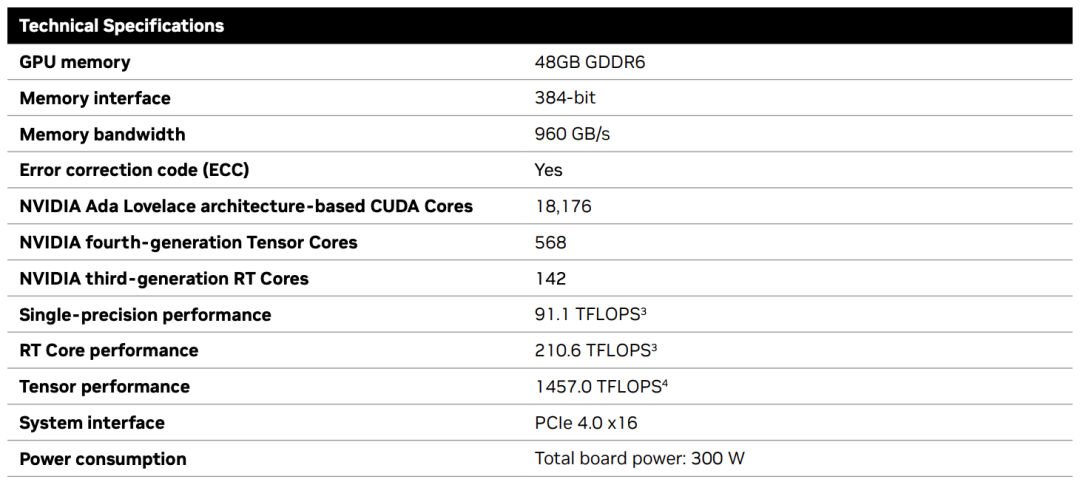
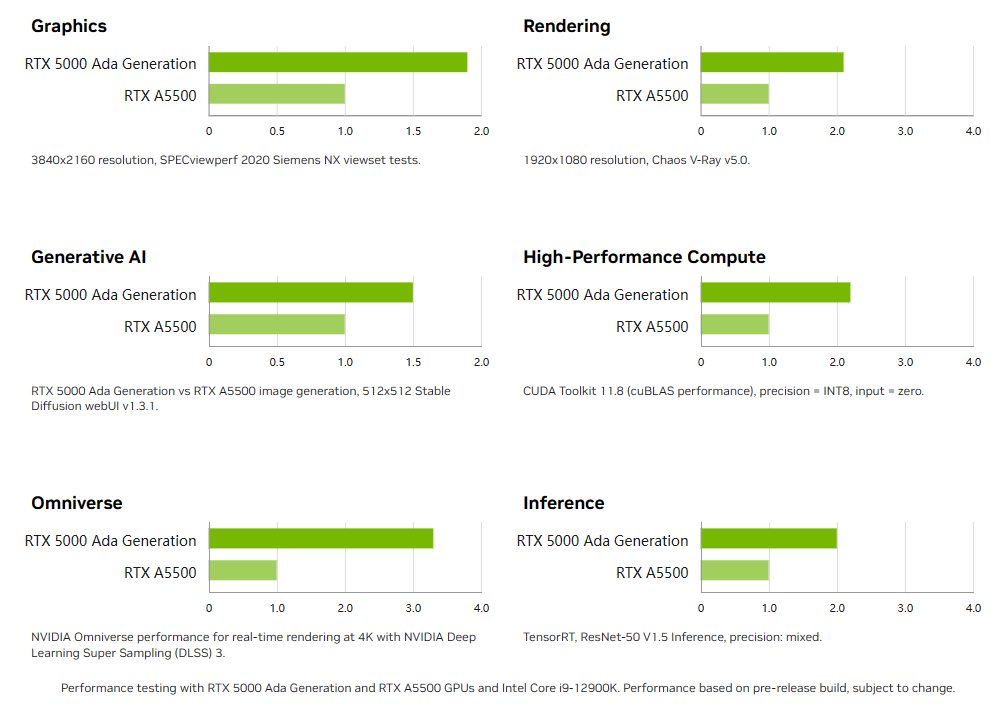
RTX工作站:绝佳刀法,4款显卡齐上新





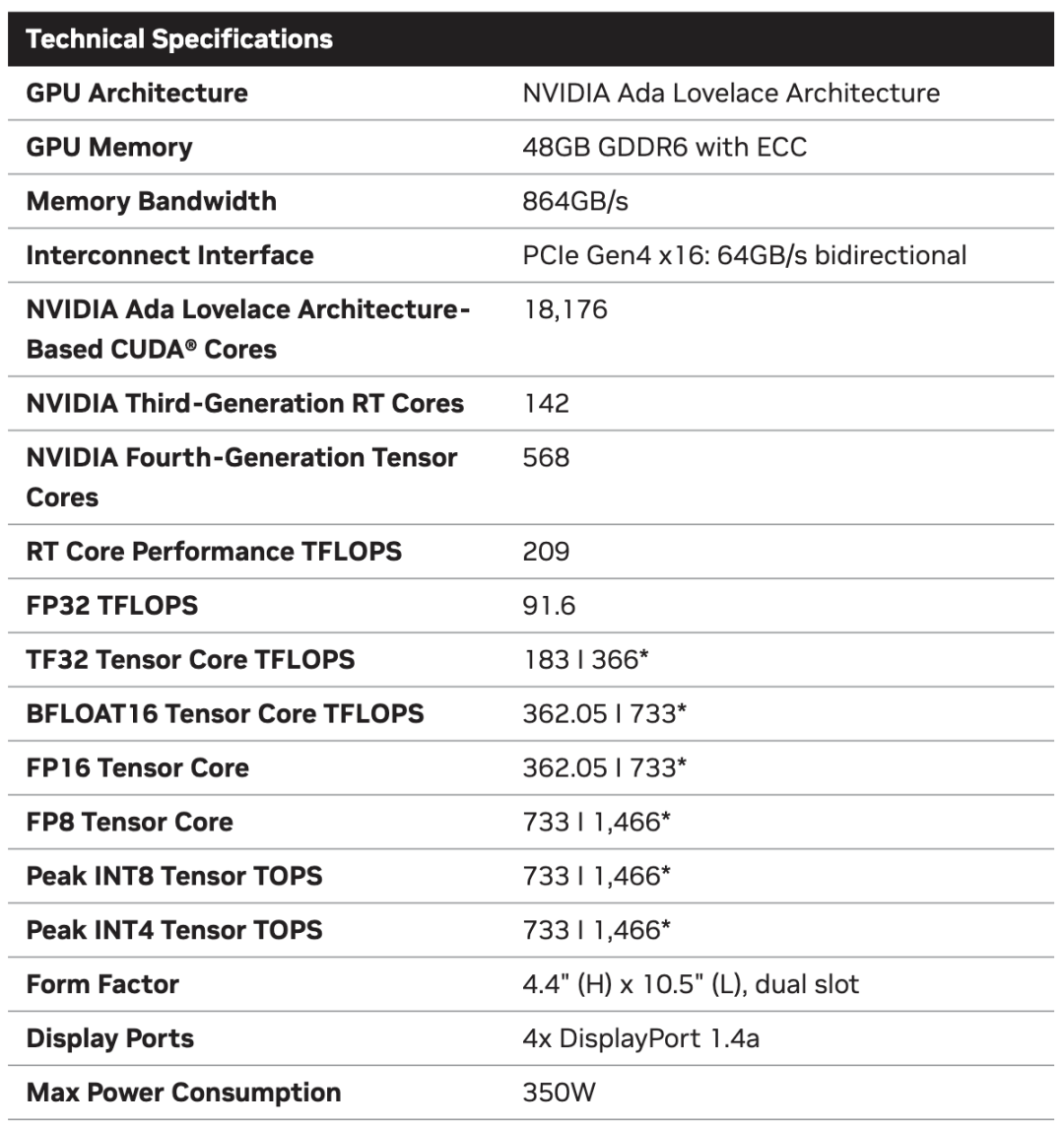
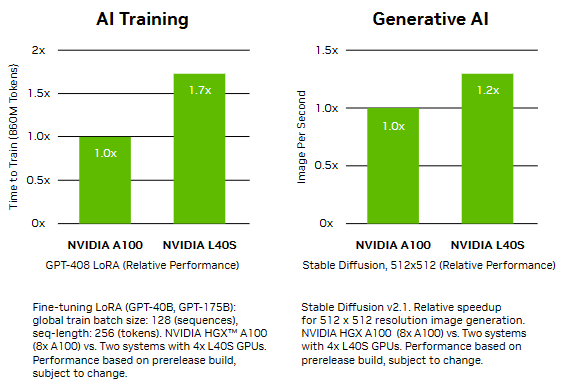
OVX服务器:搭载L40S,性能小胜A100



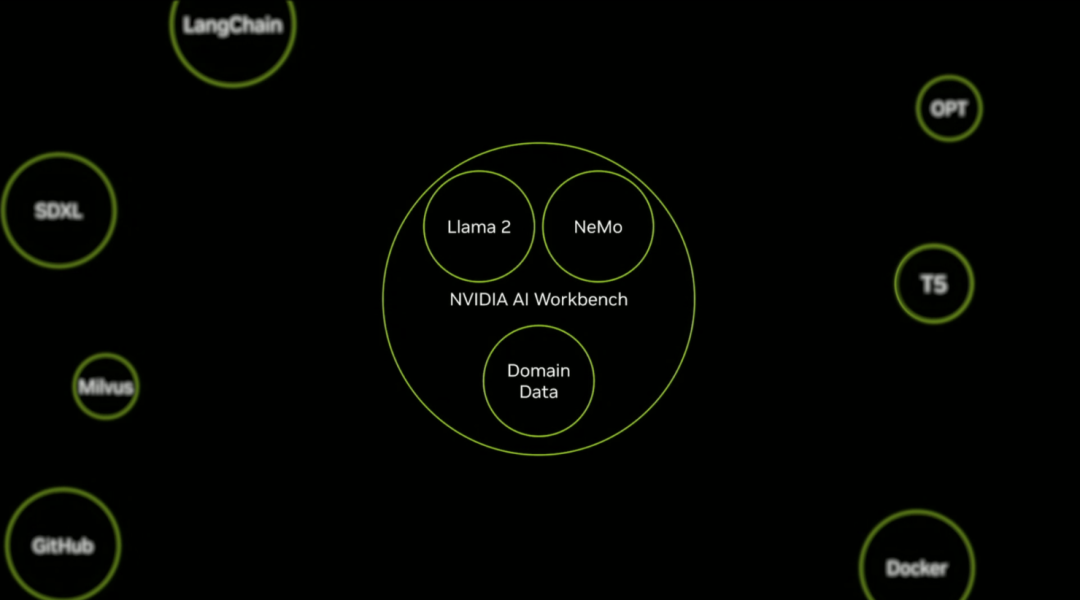
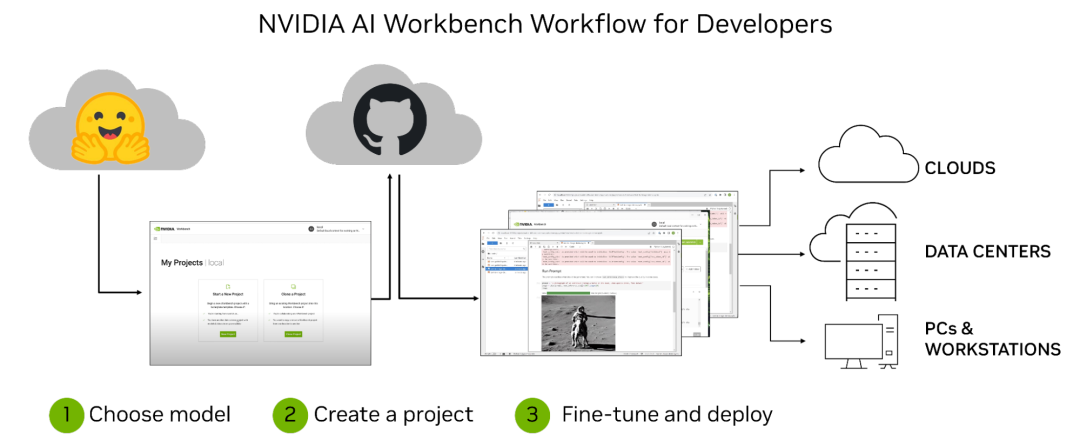
AI Workbench:加速定制生成式AI应用
除了各种强大的硬件之外,老黄还重磅发布了全新的NVIDIA AI Workbench,来帮助开发和部署生成式AI模型。
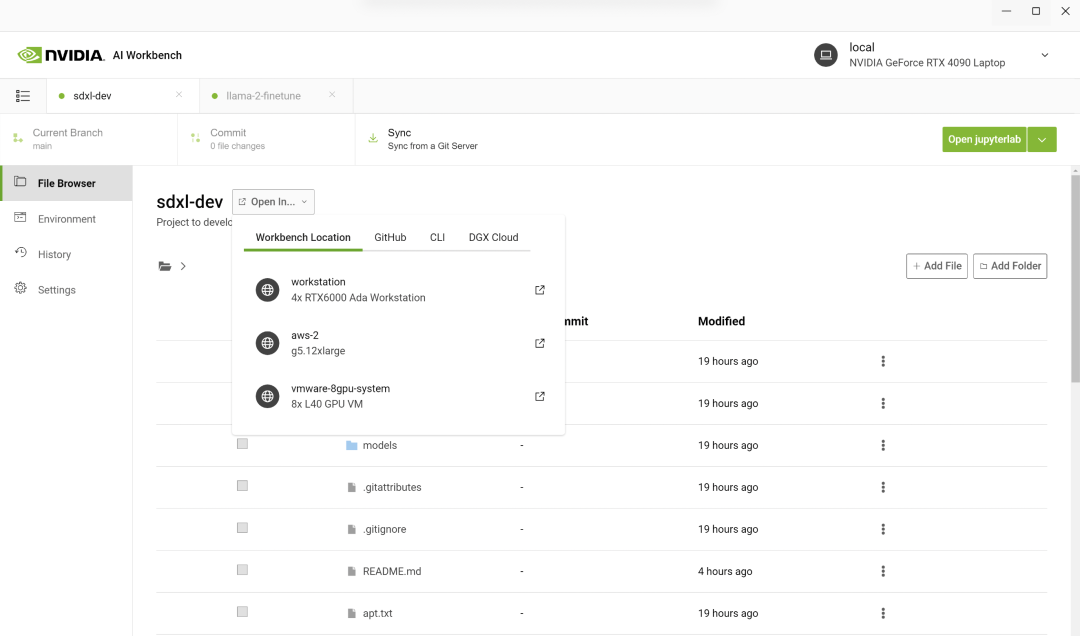
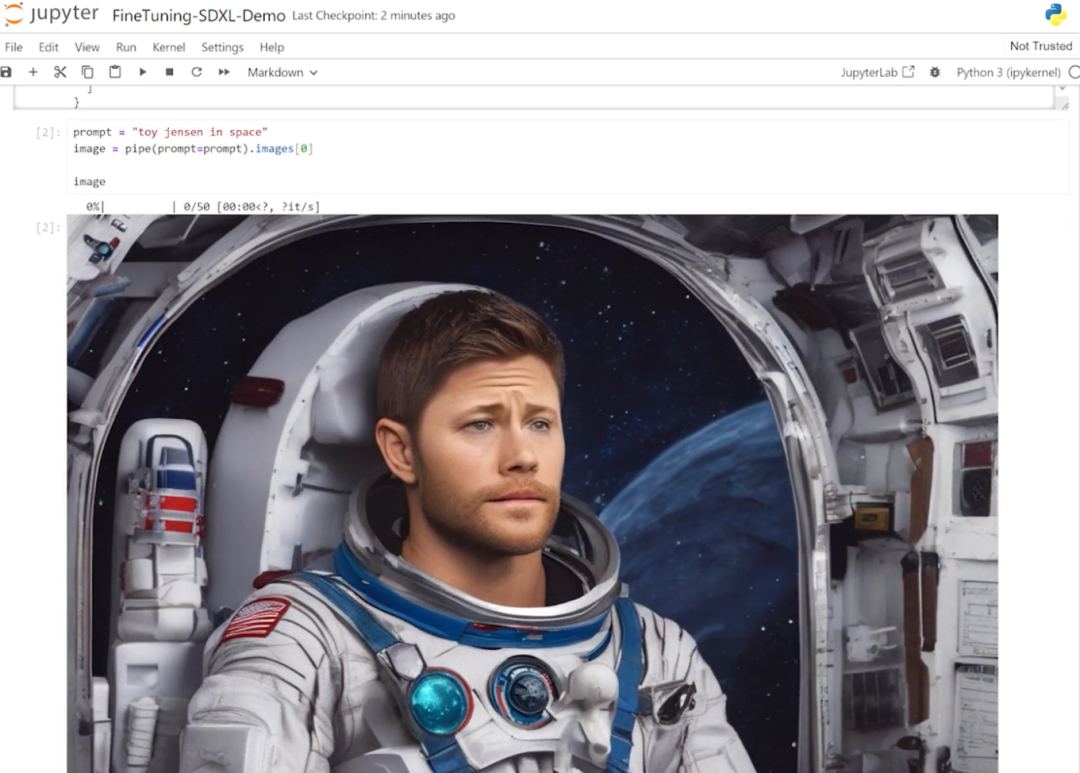
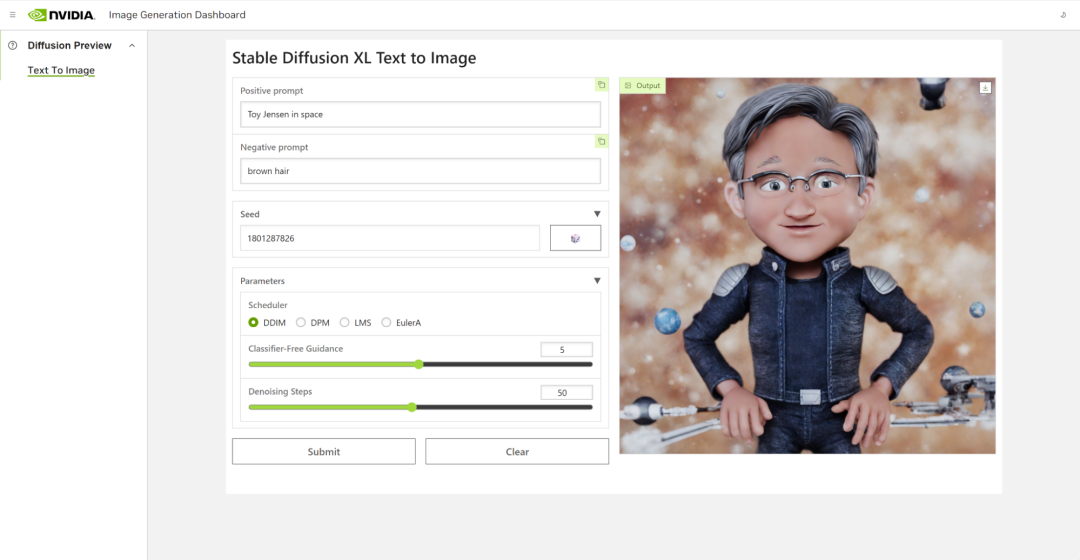
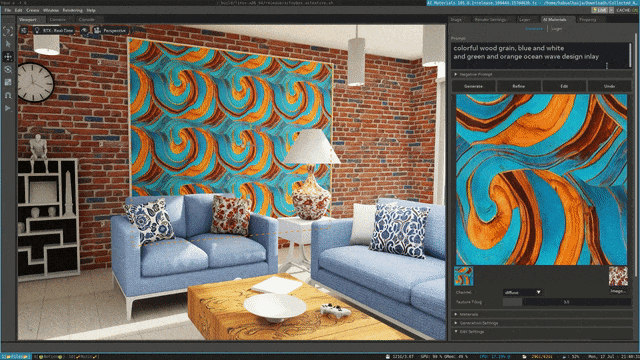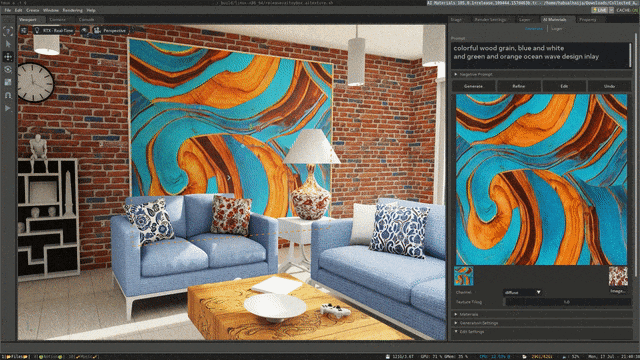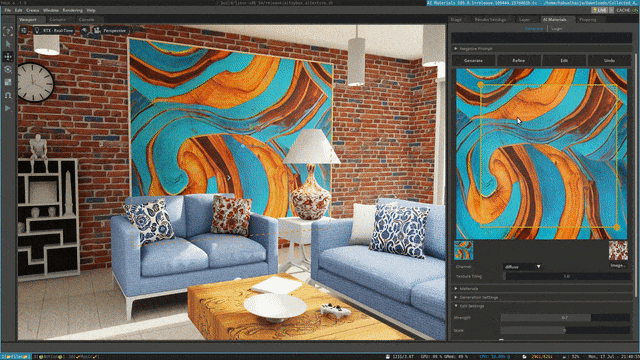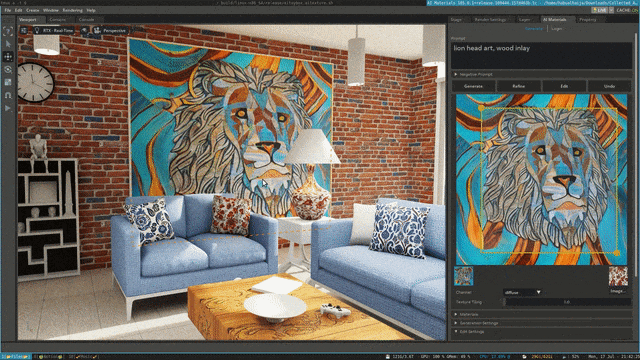
Stable Diffusion XL自定义图像生成
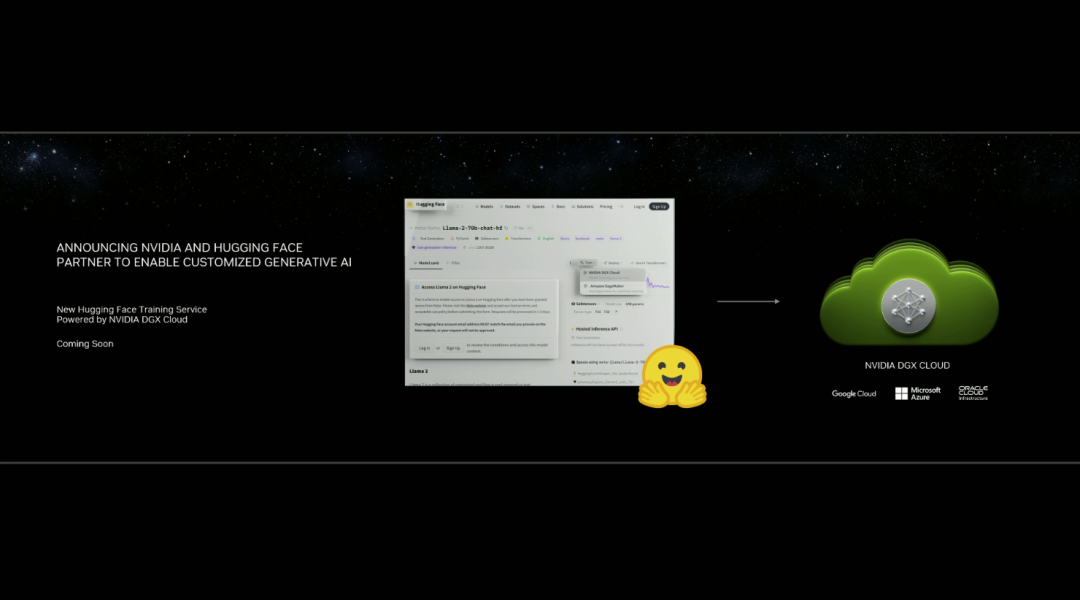
Hugging Face一键访问最强算力
AI Enterprise 4.0:定制企业级生成式AI
为了进一步加速生成式AI的应用,英伟达也将其企业级平台NVIDIA AI Enterprise升级到了4.0版本。
目前,AI Enterprise 4.0不仅可以为企业提供生成式AI所需的工具,同时还提供了生产部署所需的安全性和API稳定性。

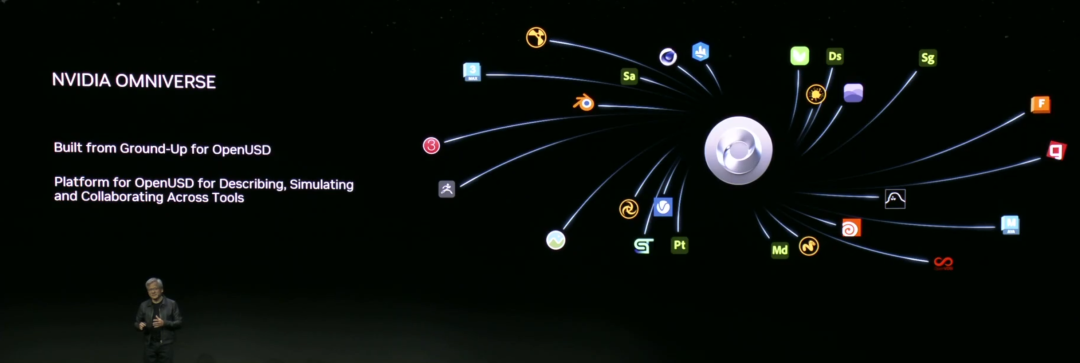
Omniverse:在元宇宙中加入大语言模型
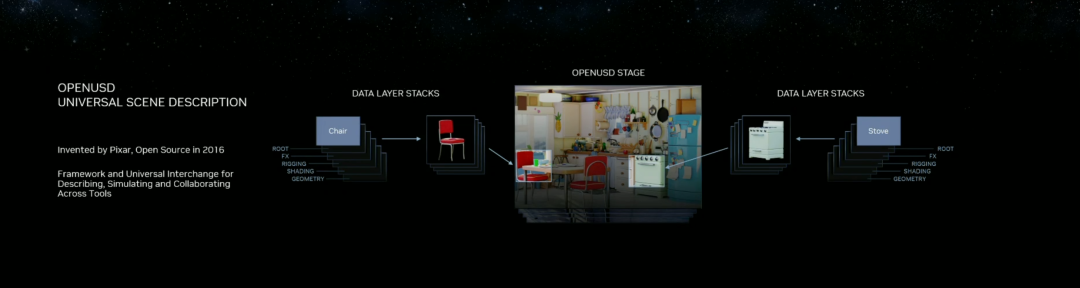
OpenUSD


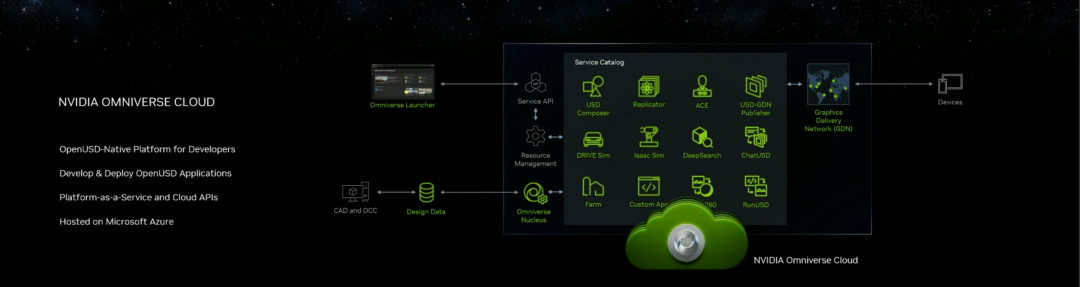
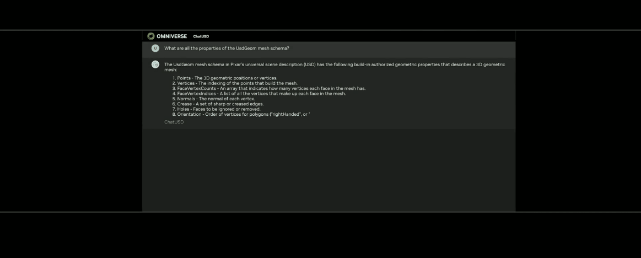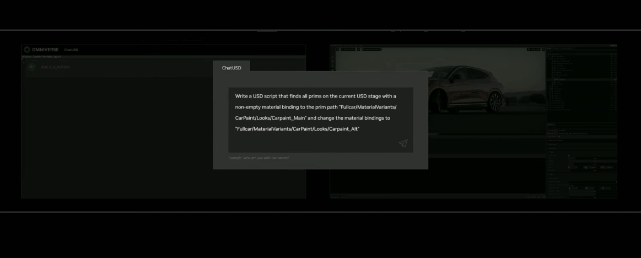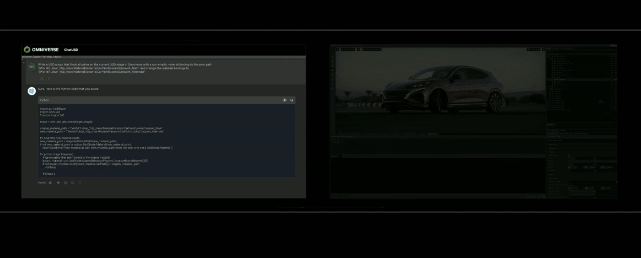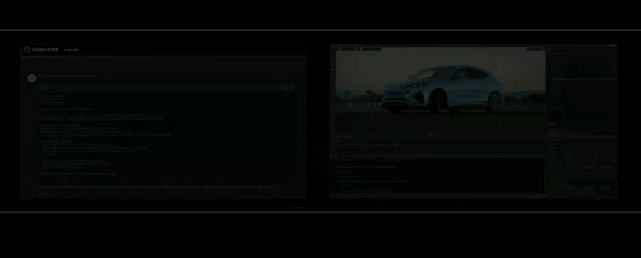
API,ChatUSD和其他更新


评论