
Serverless 工程实践 | Serverless 应用开发观念的转变

作者 | 刘宇(江昱)
Serverless 应用开发观念的转变
f = request.files['file']f.save('my_file_path')
一般情况下,一些云平台的API网关触发器会将二进制文件转换成字符串,不便直接获取和存储; 一般情况下,API 网关与 FaaS 平台之间传递的数据包有大小限制,很多平台限制数据包大小为 6MB 以内;
FaaS 平台大多是无状态的,即使存储到当前实例中,也会随着实例释放而使文件丢失。
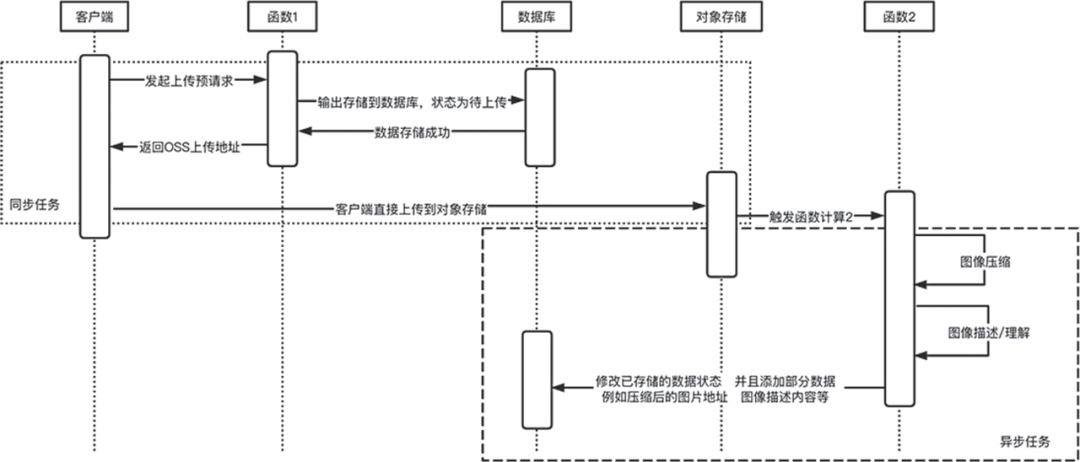
在 Serverless 架构下文件上传文件示例
AccessKey = {"id": '',"secret": ''}OSSConf = {'endPoint': 'oss-cn-hangzhou.aliyuncs.com','bucketName': 'bucketName','objectSignUrlTimeOut': 60}#获取/上传文件到OSS的临时地址auth = oss2.Auth(AccessKey['id'], AccessKey['secret'])bucket = oss2.Bucket(auth, OSSConf['endPoint'], OSSConf['bucketName'])#对象存储操作getUrl = lambda object, method: bucket.sign_url(method, object, OSSConf['objectSignUrlTimeOut'])getSignUrl = lambda object: getUrl(object, "GET")putSignUrl = lambda object: getUrl(object, "PUT")#获取随机字符串randomStr = lambda len: "".join(random.sample('abcdefghijklqrstuvwxyz123456789ABCDEFGZSA' * 100, len))
#文件上传# URI: /file/upload# Method: POST.route('/file/upload', "POST")def postFileUpload():try:pictureBase64 = bottle.request.GET.get('picture', '').split("base64,")[1]object = randomStr(100)with open('/tmp/%s' % object, 'wb') as f:f.write(base64.b64decode(pictureBase64))bucket.put_object_from_file(object, '/tmp/%s' % object)return response({"status": 'ok',})except Exception as e:print("Error: ", e)return response(ERROR['SystemError'], 'SystemError')
@bottle.route('/file/upload/url', "GET")def getFileUploadUrl():try:object = randomStr(100)return response({"upload": putSignUrl(object),"download": 'https://download.xshu.cn/%s' % (object)})except Exception as e:print("Error: ", e)return response(ERROR['SystemError'], 'SystemError')
<div style="width: 70%"><div style="text-align: center"><h3>Web端上传文件</h3></div><hr><div><p>方案1:上传到函数计算进行处理再转存到对象存储,这种方法比较直观,问题是 FaaS 平台与 API 网关处有数据包大小上限,而且对二进制文件处理并不好。</p><input type="file" name="file" id="fileFc"/><input type="button" onclick="UpladFileFC()" value="上传"/></div><hr><div><p>方案2:直接上传到对象存储。流程是先从函数计算获得临时地址并进行数据存储(例如将文件信息存到 Redis 等),然后再从客户端将文件上传到对象存储,之后通过对象存储触发器触发函数,从存储系统(例如已经存储到 Redis)读取到信息,再对图像进行处理。</p><input type="file" name="file" id="fileOss"/><input type="button" onclick="UpladFileOSS()" value="上传"/></div></div>
function UpladFileFC() {const oFReader = new FileReader();oFReader.readAsDataURL(document.getElementById("fileFc").files[0]);oFReader.onload = function (oFREvent) {const xmlhttp = window.XMLHttpRequest ? (new XMLHttpRequest()) : (newActiveXObject("Microsoft.XMLHTTP"))xmlhttp.onreadystatechange = function () {if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {alert(xmlhttp.responseText)}}const url = "https://domain.com/file/upload"xmlhttp.open("POST", url, true);xmlhttp.setRequestHeader("Content-type", "application/json");xmlhttp.send(JSON.stringify({picture: oFREvent.target.result}));}}
function doUpload(bodyUrl) {const xmlhttp = window.XMLHttpRequest ? (new XMLHttpRequest()) : (new ActiveXObject("Microsoft.XMLHTTP"));xmlhttp.open("PUT", bodyUrl, true);xmlhttp.onload = function () {alert(xmlhttp.responseText)};xmlhttp.send(document.getElementById("fileOss").files[0]);}function UpladFileOSS() {const xmlhttp = window.XMLHttpRequest ? (new XMLHttpRequest()) : (new ActiveXObject("Microsoft.XMLHTTP"))xmlhttp.onreadystatechange = function () {if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {const body = JSON.parse(xmlhttp.responseText)if (body['url']) {doUpload(body['url'])}}}const getUploadUrl = 'https://domain.com/file/upload/url'xmlhttp.open("POST", getUploadUrl, true);xmlhttp.setRequestHeader("Content-type", "application/json");xmlhttp.send();}


通过上表可以明确看出合理、适当地拆分业务会在一定程度上节约成本。上面例子的成本节约近 50%。
新书推荐

Serverless 工程实践系列
评论