Serverless特点及应用
Serverless可以看做是运行于无状态的容器中,由事件驱动,执行周期很短的服务,这部分描述和FaaS很像,所以在一部分人眼里Serverless = FaaS。
马丁大叔将Serverless与FaaS、BaaS做了一个结构整理:
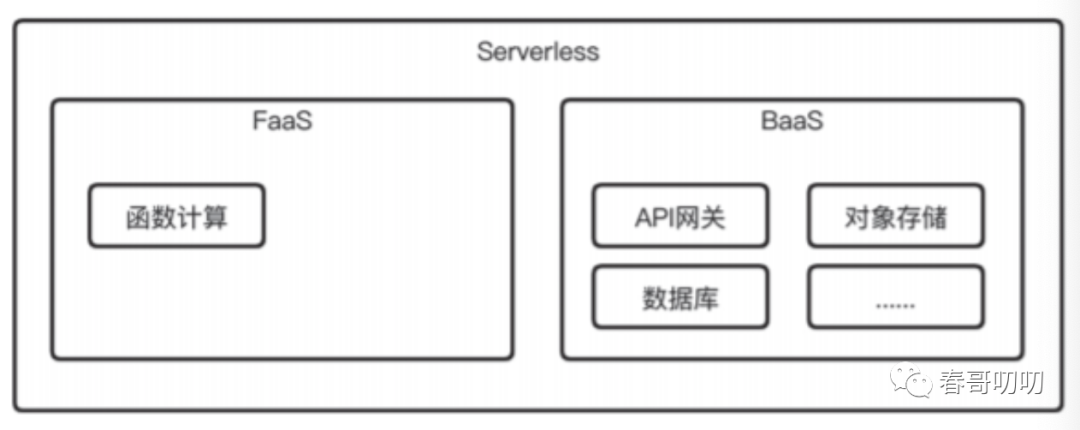
马丁大叔意思是:
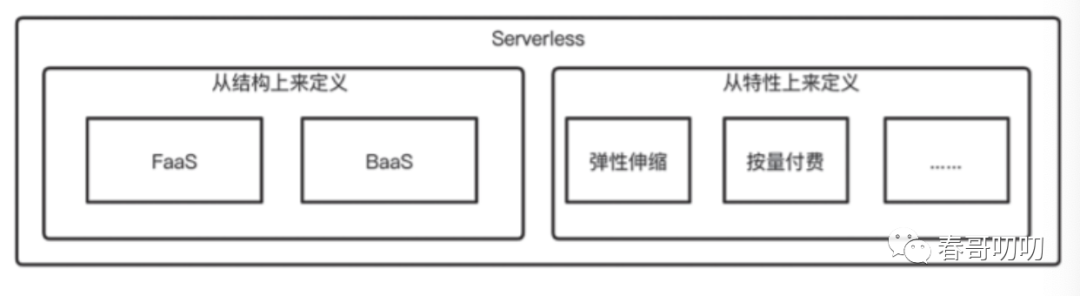
Serverless = FaaS + BaaSServerless特性包括:弹性伸缩、按需付费特点。
以谷歌开源的Serverless架构方案-Knative为例,聊聊FaaS的几个特点。
Knative是构建于K8S之上的提供基于事件驱动的Serverless架构的标准模式。
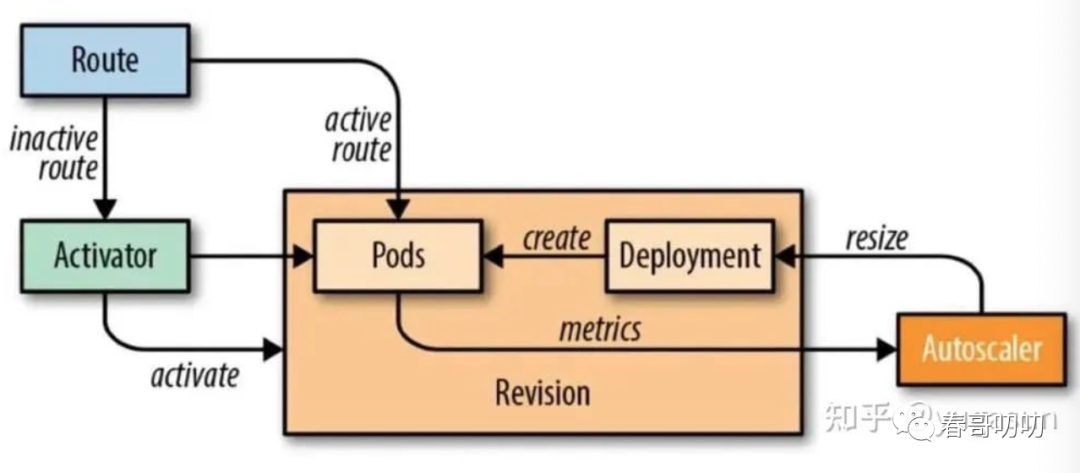
先看下Serverless如何实现弹性的。
系统根据当前监控到的流量,实现自动扩缩容,简单的公式如下:
目标实例数 = 当前并发数 / 单一实例支持的并发数如果每个实例支持10并发,那当100个并发来了,就需要10个实例。如果当前只有1个实例,其余9个实例需要扩容完成。
外部请求先缓存在Activator,直到扩容完其他9个实例,才会将请求转交给FaaS进行请求处理。实例扩容到准备好这个阶段,就叫做“冷启动”。
如何提高冷启动速度呢?
云厂商为减少冷启动时间,一般会做一些分配算法,比如:
实际扩容实例数 = 1.2 * 期望的实例数这样其实可以支撑120个并发,减少了一次扩容启动时间。
上面的实例扩容算法算是一种冷启动优化方式,我们看看是否还有其他冷启动优化的方式,实例启动过程大概是这样的:
下载代码 -> 启动实例 -> 代码初始化(依赖加载)-> 函数执行不需要扩容实例时,过程就只剩下了最后一步了,直接函数执行,相对应,我们叫做“热启动”。
一般“冷启动”时间需要上百毫秒,“热启动”只需要几毫秒。
所以优化冷启动,可以从优化冷启动时间和优化冷启动概率上解决。
减少冷启动概率方式有:实例复用、实例预热。
实例复用说的是,函数代码执行结束之后,不会立马回收实例,而是从活跃状态变成了等待状态,处于等待状态的实例可以存活30s,如果期间没有请求需要处理,实例才会被回收,这样达到了30s内实例复用的目的。
实例预热方式简单来说,就是提供预留实例不释放功能,在目标扩容实例基础上增加一定的预留buffer。
以上两种方式对应着实例成本,需要结合具体情况具体实现。
优化启动时间可以从两方面入手:优化代码体积、减少不必要的依赖。
代码体积越大,下载时间越长,所以可以考虑代码打包压缩,或者在代码模板中删除不需要的代码。
如何定义一个函数的粒度是另一个使用Serverless需要考虑的地方。
有的平台推荐将整个web服务部署在一个函数里面,有的是按代码体积做判断,有的还需要考虑函数执行时对于IO、CPU、内存消耗考虑函数粒度的拆分。
但以上几种方式都会增加研发成本上升,这也是我怀疑Serverless是否可以带来其所承诺的研发价值的地方。其有相当确定的使用场景,不能简单粗暴使用。
驱动函数类型的方式有很多,但大部分提倡的还是事件驱动。
触发FaaS运行方式都可以抽象成事件类型,比如API网关事件触发。
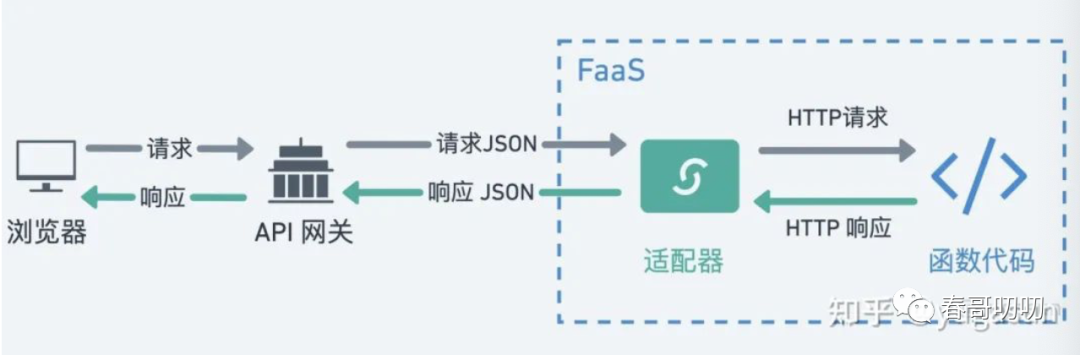
那如何使用一个FaaS服务呢?
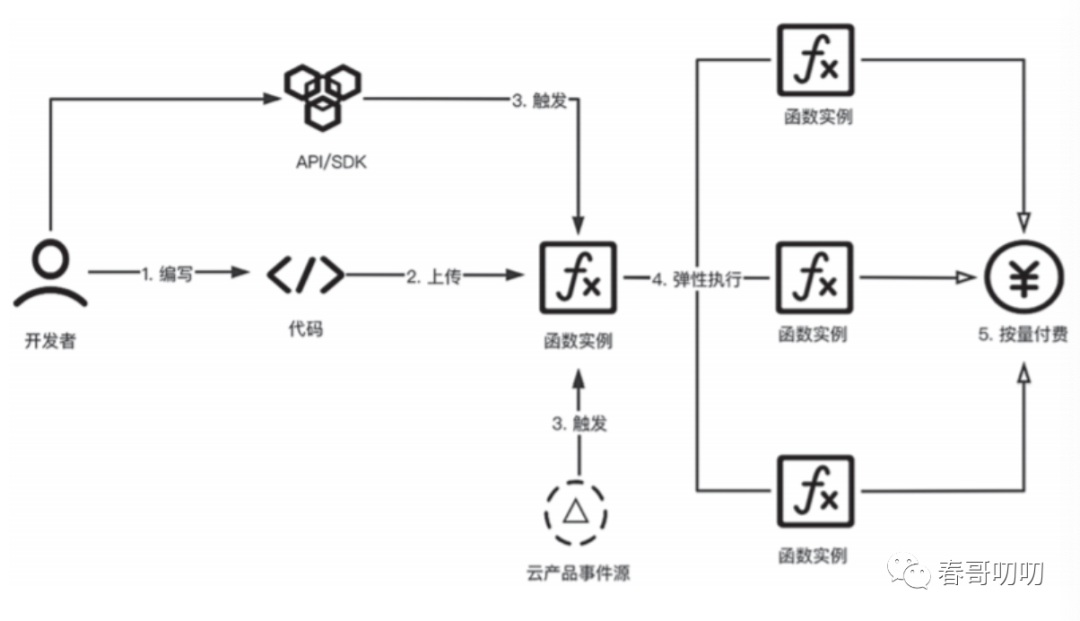
可以分成如下几步:
基于FaaS平台选择一个熟悉语言对应的Runtime平台,基于其完成:开发、测试过程。
代码完成之后,上传到FaaS平台。
代码上传之后,通过API/SDK或一些其他事件源触发函数。
FaaS平台接收到事件触发,基于配置并发度情况,弹性扩容并执行函数。
函数使用后,按资源使用情况进行计费。
为拉齐函数编写与函数执行环境的差异,FaaS平台一般会提供一些研发工具。有组件式命令行Devs工具,也有注重运维部署方面的Ops工具,提供平台观察函数生命周期。

通过工具,可以快速完成资源管理(代码编写、运行、下载、创建、上传)、快速部署、调试、工程模板、逻辑单元等工作。
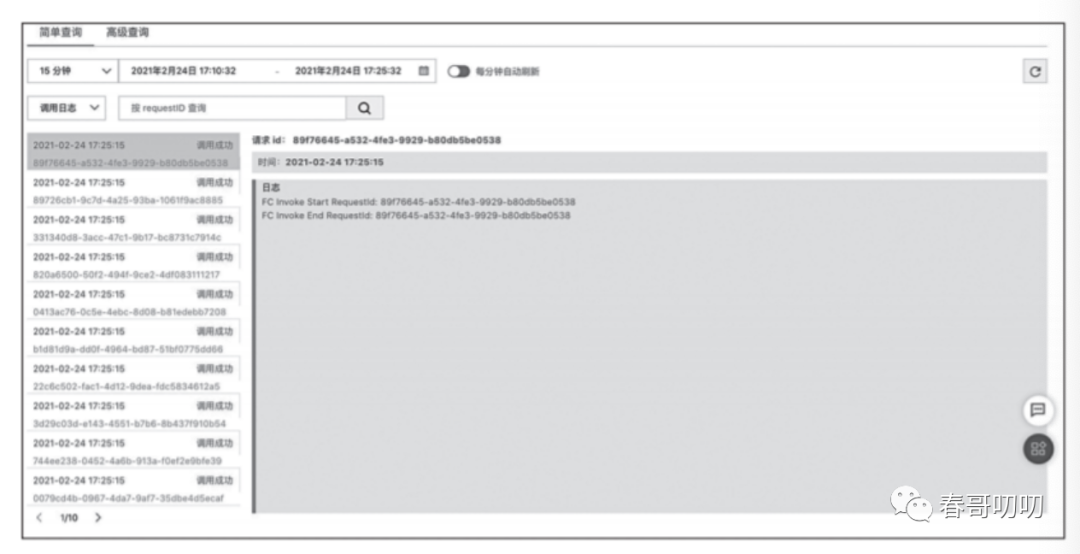
有了一个个上传到云端的函数了,就可以基于函数做工作流编排,实现想要的逻辑控制了。包括任务跟踪,状态转换,日志查看,监控调试等。
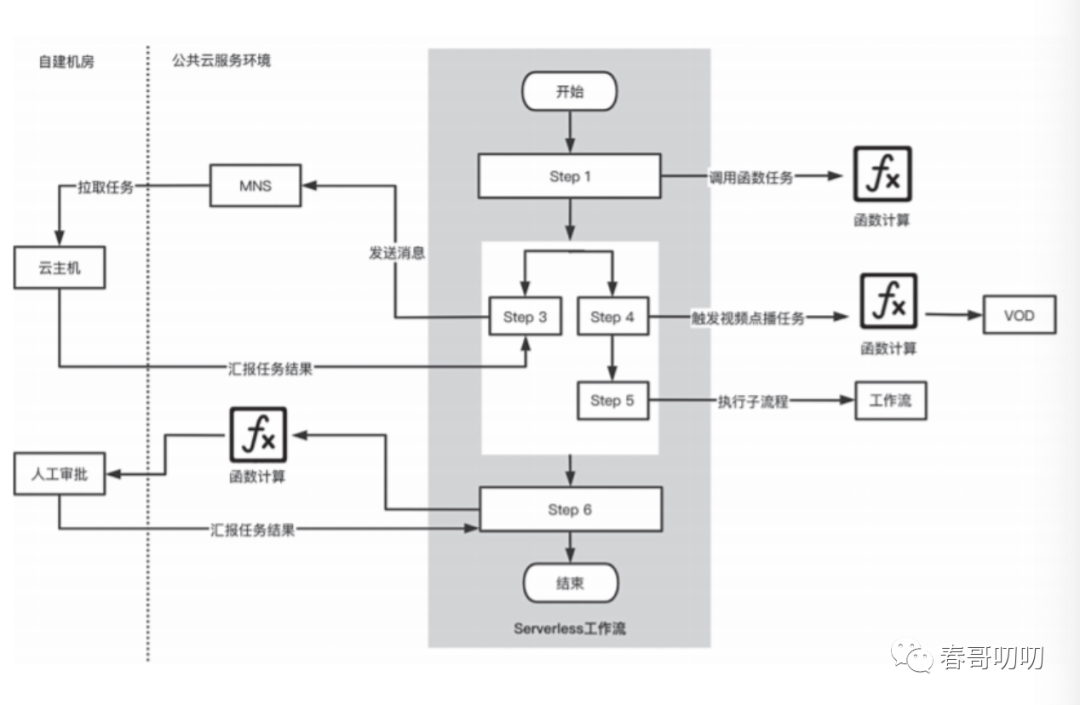
当然还有函数执行之后是可观测性(Logging、Metric、Tracing)实现函数的运维。
包含用于定位、排查、分析问题的工具,评估风险、配置并发度等工作。
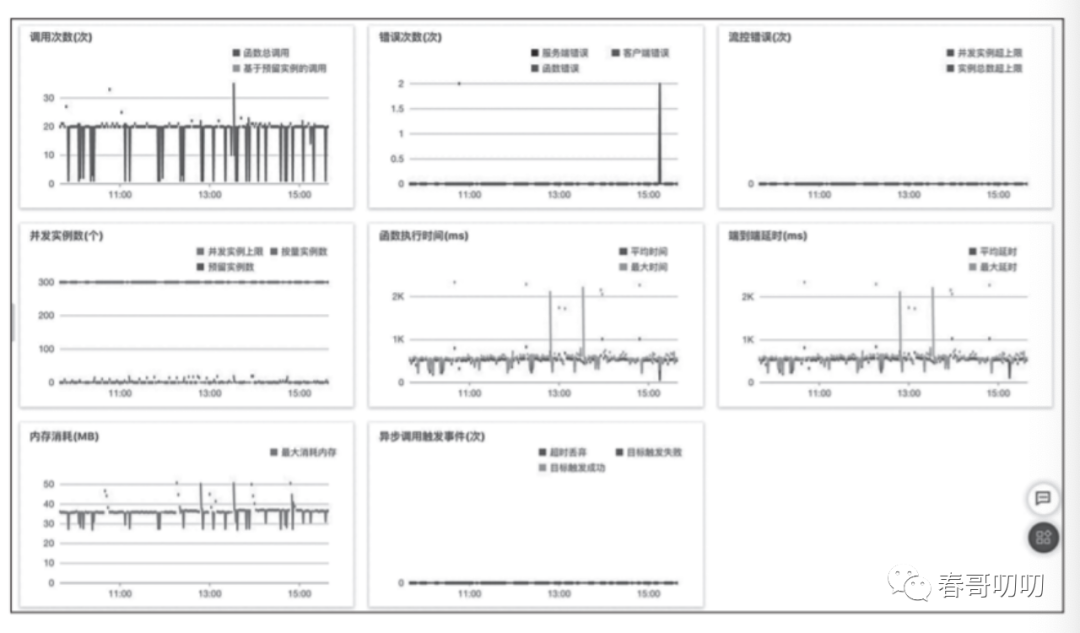
以及执行的详细日志: