
Apache Doris Compaction优化百科全书


Doris Compaction机制解析
1. 总体架构
1.1 “生产者-消费者”模式
Compaction机制要解决的第一个问题,就是如何选取合适的Tablet进行Compaction。Doris的compaction机制采用“生产者-消费者”(producer-consumer)模式,由producer线程持续生产compaction任务,并将生产出的compaction任务提交给compaction线程池进行消费执行,如图1所示。
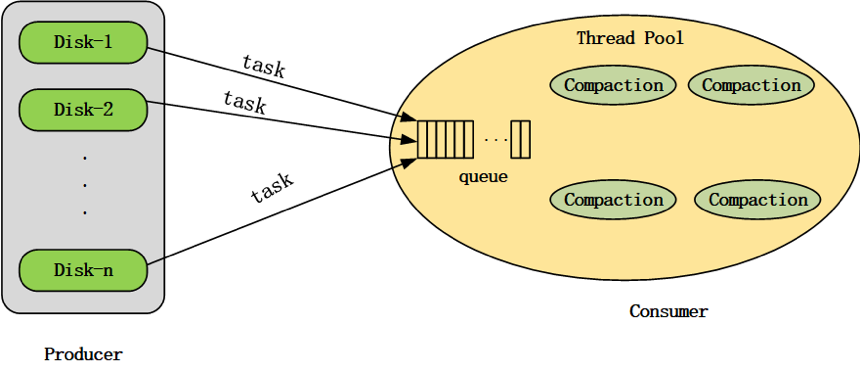
Doris BE启动时,会在后台启动一个compaction producer线程,同时会创建一个compaction线程池。producer线程持续地生产compaction任务。
在一轮任务生产过程中,会从每个磁盘各选择出一个tablet执行compaction任务。如果compaction线程池中某个磁盘的compaction任务数达到了上限(通过compaction_task_num_per_disk配置,默认值为2),则这一轮任务生产会跳过该磁盘。如果某一轮生产过程从所有磁盘均没有生产出compaction任务(即compaction线程池中每个磁盘的任务数都已达到上限),则producer线程会进入休眠状态,直到2秒超时唤醒,或线程池中某个compaction任务执行完成被唤醒。
在一轮compaction任务生产过程中,进行单个磁盘的任务生产时,需要遍历BE节点上所有的tablet,首先过滤掉不满足条件的tablet,比如:其他磁盘上的tablet、已经提交给compaction线程池的tablet、正在执行alter操作的tablet、初始化失败的tablet、上次compaction任务失败距离当前时刻的时间间隔小于设定阈值(通过min_compaction_failure_interval_sec配置,默认值为600秒)的tablet,然后从剩余的满足条件的tablet中选择tablet score最高的tablet执行compaction任务。
tablet score通过如下公式计算:
ablet_score = k1 * scan_frequency + k2 * compaction_score
其中,k1和k2分别可以通过参数compaction_tablet_scan_frequency_factor(默认值为0)和参数compaction_tablet_compaction_score_factor(默认值为1)动态配置。scan_frequency 表示tablet当前一段时间的scan频率。compaction score的计算方法会在本文的后面进行详细地介绍。
可以通过参数generate_compaction_tasks_min_interval_ms动态配置任务生产的频率,默认值为10ms,即每生产一轮compaction任务,producer线程会休眠10ms。
可以通过参数cumulative_compaction_rounds_for_each_base_compaction_round动态配置cumulative compaction和base compaction的生产周期,默认值为9,即每生产9轮cumulative compaction任务,然后会生产1轮base compaction任务。
可以通过参数disable_auto_compaction动态配置是否关闭compaction producer的任务生产,默认值为false,即不关闭producer的任务生产。
1.2 permission机制
producer生产出的compaction任务需要提交给compaction线程池执行。为了调节BE节点compaction的内存使用量,Doris增加了对compaction任务提交的permission机制,如图2所示。系统维持一定数量的compaction permits(通过参数total_permits_for_compaction_score配置),每一个compaction任务提交给线程池之前都需要向系统申请permits(permits request),只有获得系统分配的permits之后任务才能被提交给compaction线程池,compaction任务在线程池中执行结束之后需要将自己持有permits归还给系统(permits release)。如果系统当前剩余的可分配的compaction permits数量小于本次compaction任务需要的permits数量,则本次任务提交会被阻塞(compaction任务提交是串行执行的,其他需要提交的任务也会被阻塞),直到有其他compaction任务执行结束并释放permits,使得系统有足够数量的permits分配给当前compaction任务。如果某一个compaction任务需要的permits数量超过系统维持的permits总数,则允许当线程池中所有的任务都执行结束之后,将该compaction任务提交给线程池执行。
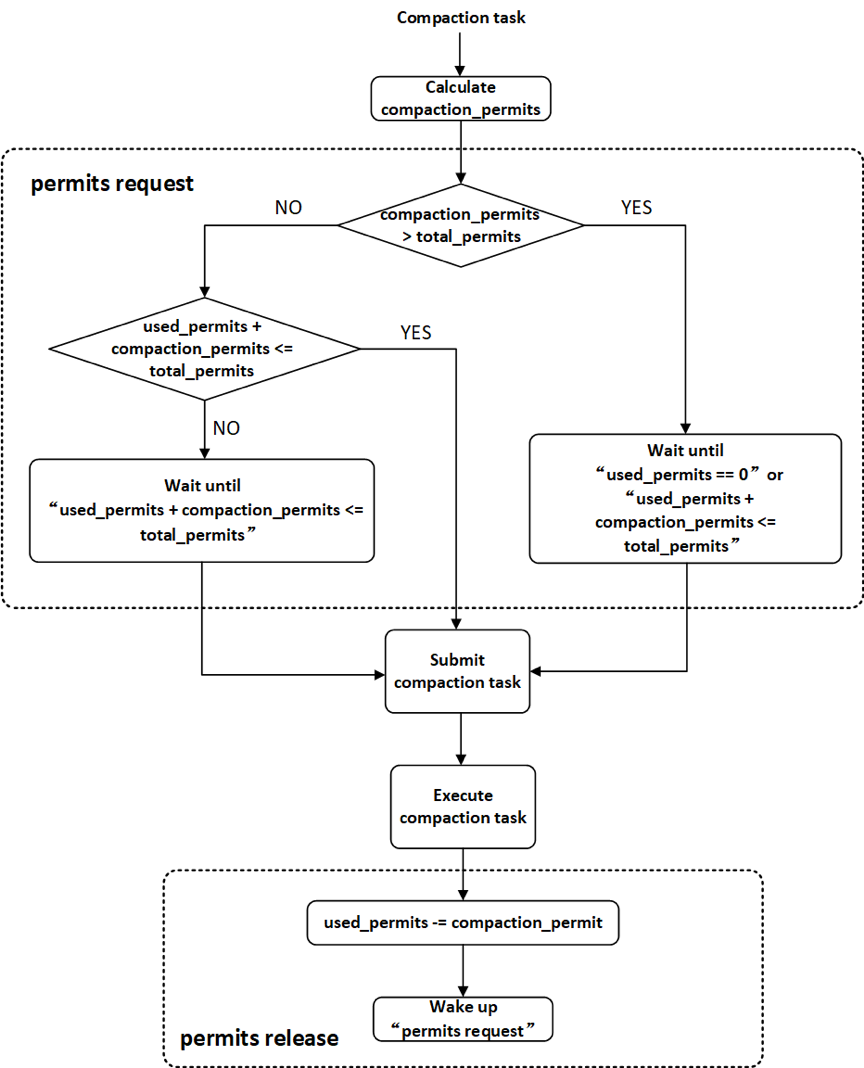
Doris中单个compaction任务执行过程中的内存使用量与本次compaction任务合并的segment文件数量有关。一个rowset会包含多个segment文件,而一个compaction任务可能包含多个rowset。因此,使用compaction任务中需要合并的segment文件数量作为compaction任务的permits。通过调整系统维持的compaction permits总量可以对BE节点compaction的内存使用量进行调节。
Compaction任务可以概括为两个阶段:compaction preparation和compaction execution,如图3所示。compaction preparation阶段主要是从tablet中选出需要进行版本合并的rowsets,compaction execution阶段主要进行rowsets的版本合并操作。
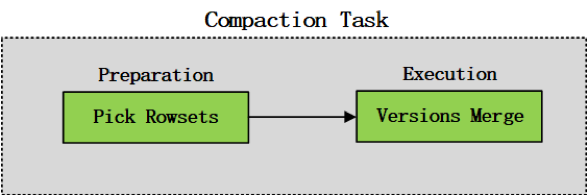
在Doris中,compaction任务的preparation阶段在permits request之前执行,从tablet中选出需要进行版本合并的rowsets,通过需要合并的segment文件数量计算compaction permits。compaction任务的execution阶段会真正在线程池中执行,进行版本的合并,如图4所示。
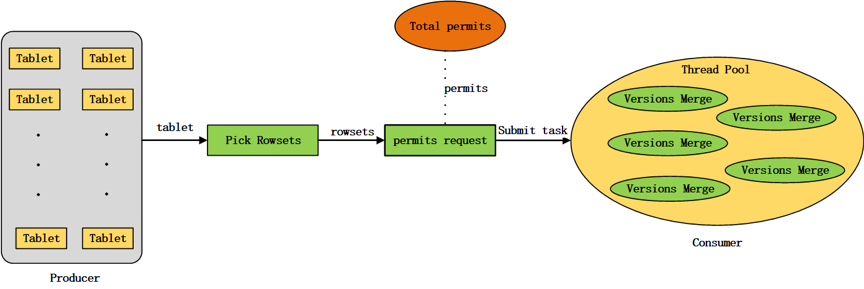
Compaction任务提交到线程池之后,可能会在线程池的等待队列中等待较长的时间都没有被调度,当前tablet在这期间可能发生过clone操作,导致compaction preparation阶段选出的需要进行版本合并的rowset发生了改变,因此,在compaction execution阶段一开始需要判断任务等待调度期间tablet是否发生过clone操作,如果发生过clone操作,则本次compaction任务退出,否则,正常执行rowsets的合并。
Doris也提供了http接口,支持手动触发单个tablet的cumulative compaction或base compaction。
2. Cumulative Compaction
Doris的cumulative compaction每次会在cumulative point之后选择相邻的数个rowset进行合并,主要包含5个步骤,分别是计算cumulative point、生成candidate rowsets、选择input rowsets、执行rowsets合并以及更新cumulative point,如图1。其中,前面三个步骤属于compaction preparation阶段,后面两个步骤属于compaction execution阶段。

目前可供选择的cumulative compaction策略有两种:num_based cumulative compaction和size_based cumulative compaction。cumulative compaction的策略选择可以通过参数cumulative_compaction_policy进行配置(默认为size_based)。num_based cumulative compaction是基于rowset的文件数量进行compaction的选择,该策略会在后面的版本中被丢弃。Size_based cumulative compaction策略通过计算每个rowset的大小来决定compaction的选择,可以显著地减少写放大的系数。
下面将详细地对size_based cumulative compaction策略进行介绍。
2.1 计算cumulative point
版本号比cumulative point小的rowset仅会执行base compaction,而版本号比cumulative point大的rowset仅会执行cumulutive compaction。将一个rowset从cumulative 侧移动到base侧(即增大cumulative point)的行为称为一次Promotion。
如果tablet当前的cumulative point值为-1(初始值),则本次计算的cumulative point值不变,仍为-1;否则,执行以下操作进行cumulative point的计算:
(1) 对tablet下所有的rowset按照版本先后进行排序;
(2) Doris会通过计算promotion size来决定是否要对一个rowset执行Promotion。根据base rowset(start version为0)的大小计算tablet当前的promotion_size:
promotion_size = base_rowset_size * ratio
其中,ratio值可以通过cumulative_size_based_promotion_ratio配置,默认值为0.05。promotion_size被限定在cumulative_size_based_promotion_size_mbytes(默认值为1024MB)与cumulative_size_based_promotion_min_size_mbytes(默认值为64MB)之间,promotion size的计算流程如图2所示。
(3)从base rowset开始,依次遍历每一个rowset,当遇到以下情况,则停止遍历,更新tablet的cumulative point:
a.当前rowset与前一个rowset之间出现版本缺失,则更新cumulative point为前一个rowset的end_version+1;
b.当前rowset不是数据删除版本,同时当前rowset没有发生过版本合并,或当前rowset中的segment文件之间存在overlapping,则更新cumulative point为当前rowset的start_version;
c.当前rowset不是数据删除版本,同时当前rowset的大小小于promotion_size,则更新cumulative point为当前rowset的start_version。
2.2 生成candidate rowsets
依次遍历tablet中按照版本先后排序好的每一个rowset,如果某一个rowset的版本位于cumulative point之后;并且该rowset的创建时间距离当前时刻超过设定的时间间隔(可以通过cumulative_compaction_skip_window_seconds配置,默认值为30秒),或者该rowset参与过版本合并(rowset的start_version与end_version不相等),则将该rowset作为一个候选rowset。将所有候选rowset依次保存在向量candidate rowsets中。
2.3 选择input rowsets
(1)寻找candidate rowsets中最大的连续版本序列。
遍历candidate rowsets中的每一个rowset,如果某两个相邻的rowset之间出现版本缺失,则将candidate rowsets中第一个缺失版本之前的所有rowset作为新的candidate rowsets;
(2)生成input rowsets。
遍历candidate rowsets中的每一个rowset,将访问完成的rowset保存在向量input rowsets中,当遇到以下情况,遍历结束:
a.某一个rowset为数据删除版本(并使用last_delete_version记录当前数据删除版本,last_delete_version初始值为-1),并且input rowsets中的rowset数量不为0(如果input rowsets中的rowset数量为0,则跳过当前rowset,继续访问下一个rowset);
b.input rowsets中的rowset score(表示rowset中的segment文件数目)之和达到上限阈值(通过max_cumulative_compaction_num_singleton_deltas配置,默认值为1000);
c.遍历过程正常完成,input rowsets中包含了candidate rowsets中所有的rowset。
(3)调整input rowsets。
a.如果input rowsets中所有的rowset大小之和达到promotion_size,则不需要调整input rowsets。
b.如果存在数据删除版本的记录(last_delete_version 不为-1,即生成input rowsets的遍历过程因为存在删除数据版本而结束),并且input rowsets中的rowset数量不为1,则不需要调整input rowsets;如果存在数据删除版本的记录,并且input rowsets中的rowset数量为1,同时该rowset中的segment文件之间存在overlapping,则不需要调整input rowsets;如果存在数据删除版本的记录,并且input rowsets中的rowset数量为1,同时该rowset中的segment文件之间不存在overlapping,则清空input rowsets。
c.如果不存在数据删除版本的记录(last_delete_version 为-1),则遍历input rowsets中的rowset。从第一个rowset开始,计算当前rowset的大小等级(current_level),同时计算input rowsets中除当前rowset之外的其他rowset大小之和的等级(remain_level),如果current_level > remain_level,则从input rowsets中删除当前rowset,否则,停止遍历。
【注】level等级划分由参数cumulative_size_based_promotion_size_mbytes (默认值为1024MB)和cumulative_size_based_compaction_lower_size_mbytes (默认值为64MB)确定。最高的level值为cumulative_size_based_promotion_size_mbytes / 2,下一级level值为上一级level值的1/2,直到level值小于cumulative_size_based_compaction_lower_size_mbytes,则设置该级level值为0,level等级划分流程如图3所示。
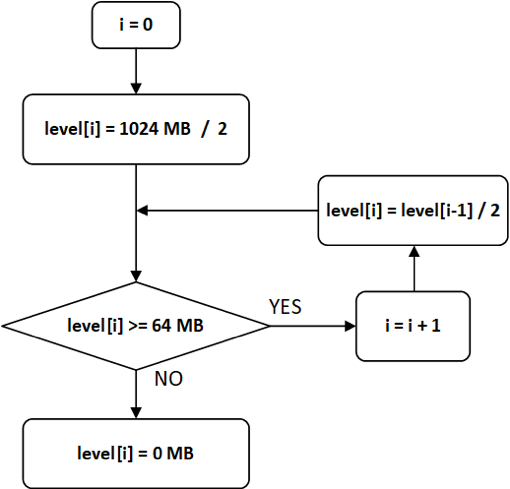
计算某一个rowset的level值时,如果level[n-1] > rowset_size >= level[n],则该rowset的level值为level[n]。
2.4 执行rowsets合并
将input rowsets中的所有rowset进行合并,生成一个output rowset。在执行rowsets合并时,会创建一个Reader和一个Rowset Writer,Rowset Writer与output rowset相对应。
在Reader底层逻辑中,input rowsets中的每一个rowset都会对应一个Rowset Reader。Reader按照key的排序规则逐行读出input rowsets中的数据,然后通过Rowset Writer写入output rowset。aggregation key数据模型和unique key数据模型中,key相同但分散在不同Rowset中的数据行会在rowsets合并后完成聚合。cumulative compaction不会将delete操作删除的数据行进行真正地删除,这部分工作会在base compaction中进行。
2.5 更新cumulative point
cumulative compaction执行结束之后,需要更新cumulative point。
(1)如果存在数据删除版本的记录(last_delete_version 不为-1,即生成input rowsets的遍历过程因为存在删除数据版本而结束),则更新cumulative point为output_rowset的end_version+1;
(2)如果不存在数据删除版本的记录(last_delete_version 为-1),判断output rowset的大小是否超过promotion_size,如果超过,则更新cumulative point为output_rowset的end_version+1,否则,不更新cumulative point。
【注】cumulative compaction执行之前需要计算一次cumulative point,因为上一次cumulative compaction之后可能发生过base compaction,base rowset发生了变化,因此,promotion size发生了变化,cumulative point也会变化。cumulative compaction执行之前计算cumulative point,是为了确定本次 cumulative compaction的边界;cumulative compaction执行之后更新cumulative point,是为了确定下一次可能发生的base compaction的边界。
2.6 计算cumulative compaction score
在compaction producer线程中,需要依据cumulative compaction score生产cumulative compaction任务。依次遍历tablet中的所有rowset,如果某一个rowset的版本位于cumulative point之后,则将该rowset添加到向量rowset_to_compact。
(1)如果rowset_to_compact中所有rowset的大小之和超过promotion_size,则rowset_to_compact中所有rowset的score之和为当前tablet的cumulative compaction score,即rowset_to_compact中所有rowset的segment文件数目之和。
(2)如果rowset_to_compact中所有rowset的大小之和小于promotion_size,则按照版本先后对rowset_to_compact中的rowset进行排序,然后遍历rowset_to_compact中的每一个rowset。计算当前rowset的大小等级(current_level),同时计算rowset_to_compact中除当前rowset之外的其他rowset大小之和的等级(remain_level),如果current_level > remain_level,则从向量rowset_to_compact中删除当前rowset,否则,停止遍历。rowset_to_compact中所有rowset的score之和为当前tablet的cumulative compaction score。
3. Base Compaction
Doris的base compaction会将cumulative point之前的所有rowset进行合并,主要包含3个步骤,分别是选择input rowsets、检查base compaction的执行条件以及执行rowsets合并,如图1所示。其中,前面两个步骤属于compaction preparation阶段,最后一个步骤属于compaction execution阶段。

3.1 选择input rowsets
(1)选择input rowsets。依次遍历tablet中的每一个rowset,获取所有版本位于cumulative point之前的rowset作为input rowsets。
(2)对input rowsets中的所有rowset按照版本先后进行排序。
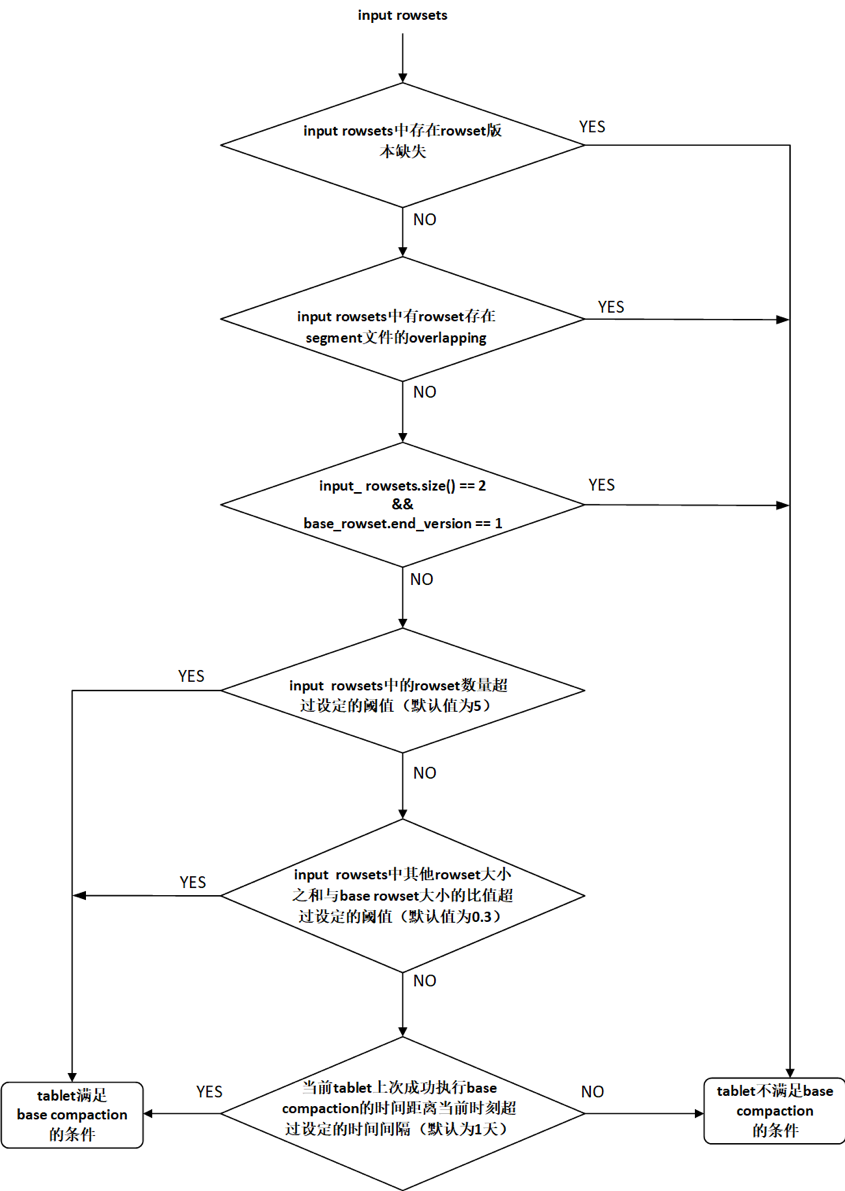
3.2 检查base compaction的执行条件
依次检查以下条件(如图2所示):
(1)版本连续性条件
遍历input rowsets,判断是否有相邻的两个rowset之间存在版本缺失,如果存在版本缺失,则当前tablet不满足base compaction的执行条件,本次base compaction任务结束;否则,检查下一个条件。
(2)rowset overlapping条件
遍历input rowsets,如果有rowset中不同segment文件之间存在overlapping,则当前tablet不满足base compaction的执行条件,本次base compaction任务结束;否则,检查检查下一个条件。
(3) base rowset条件
如果input rowsets中只有两个rowset,并且base rowset(start version为0)的end version为1,则当前tablet不满足base compaction的执行条件,本次base compaction任务结束;否则,检查下一个条件。
(4)rowset的数量条件
如果input rowsets中rowset的数量超过设定的阈值(通过base_compaction_num_cumulative_deltas配置,默认值为5),则当前tablet满足base compaction的执行条件;否则,检查下一个条件。
(5)rowset size条件
如果input rowsets中除base rowset(start version为0)之外的其他rowset大小之和与base rowset大小之比超过设定的阈值(通过base_cumulative_delta_ratio配置,默认值为0.3),则当前tablet满足base compaction的执行条件;否则,检查检查下一个条件。
(6)时间条件
如果当前tablet上一次成功执行base compaction的时间距离当前时刻超过指定的时间间隔(通过base_compaction_interval_seconds_since_last_operation配置,默认值为86400秒,即1天),则当前tablet满足base compaction的执行条件;否则,当前tablet不满足base compaction的执行条件,本次base compaction任务结束。
3.3 执行rowsets合并
将input rowsets中的所有rowset进行合并,生成一个output rowset。与cumulative compaction过程中执行rowsets合并的流程相同,不再赘述。值得一提的是,base compaction过程中会将delete操作删除的数据行真正地删除。
3.4 计算base compaction score
在compaction producer线程中,需要依据base compaction score生产base compaction任务。依次遍历tablet中的每一个rowset,所有位于cumulative point之前的rowset的 score之和为tablet当前的base compaction score,即cumulative point之前的rowset中的segment文件数目之和。
Compaction调优(一)
1. 什么是 Compaction
Doris 的数据写入模型使用了 LSM-Tree 类似的数据结构。数据都是以追加(Append)的方式写入磁盘的。这种数据结构可以将随机写变为顺序写。这是一种面向写优化的数据结构,他能增强系统的写入吞吐,但是在读逻辑中,需要通过 Merge-on-Read 的方式,在读取时合并多次写入的数据,从而处理写入时的数据变更。
Merge-on-Read 会影响读取的效率,为了降低读取时需要合并的数据量,基于 LSM-Tree 的系统都会引入后台数据合并的逻辑,以一定策略定期的对数据进行合并。Doris 中这种机制被称为 Compaction。
Doris 中每次数据写入会生成一个数据版本。Compaction的过程就是讲多个数据版本合并成一个更大的版本。Compaction 可以带来以下好处:
1. 使数据更加有序
每个数据版本内的数据是按主键有序的,但是版本之间的数据是无序的。Compaction后形成的大版本将多个小版本的数据变成有序数据。在有序数据中进行数据检索的效率更高。
2. 消除数据变更
数据都是以追加的方式写入的,因此 Delete、Update 等操作都是写入一个标记。Compaction 操作可以处理这些标记,进行真正的数据删除或更新,从而在读取时,不再需要根据这些标记来过滤数据。
3. 增加数据聚合度
在聚合模型下,Compaction 能进一步聚合不同数据版本中相同 key 的数据行,从而增加数据聚合度,减少读取时需要实时进行的聚合计算。
2. Compaction 的问题
用户可能需要根据实际的使用场景来调整 Compaction 的策略,否则可能遇到如下问题:
1. Compaction 速度低于数据写入速度
在高频写入场景下,短时间内会产生大量的数据版本。如果 Compaction 不及时,就会造成大量版本堆积,最终严重影响写入速度。
2. 写放大问题
Compaction 本质上是将已经写入的数据读取后重写写回的过程,这种数据重复写入被称为写放大。一个好的Compaction策略应该在保证效率的前提下,尽量降低写放大系数。过多的 Compaction 会占用大量的磁盘IO资源,影响系统整体效率。
Doris 中用于控制Compaction的参数非常多。本文尝试以下方面,介绍这些参数的含义以及如果通过调整参数来适配场景。
数据版本是如何产生的,哪些因素影响数据版本的产出。 为什么需要 Base 和 Cumulative 两种类型的 Compaction。 Compaction 机制是如何挑选数据分片进行 Compaction 的。 对于一个数据分片,Compaction 机制是如何确定哪些数据版本参与 Compaction 的。 在高频导入场景下,可以修改哪些参数来优化 Compaction 逻辑。 Compaction 相关的查看和管理命令。
3. 数据版本的产生
首先,用户的数据表会按照分区和分桶规则,切分成若干个数据分片(Tablet)存储在不同 BE 节点上。每个 Tablet 都有多个副本(默认为3副本)。Compaction 是在每个 BE 上独立进行的,Compaction 逻辑处理的就是一个 BE 节点上所有的数据分片。
前文说到,Doris的数据都是以追加的方式写入系统的。Doris目前的写入依然是以微批的方式进行的,每一批次的数据针对每个 Tablet 都会形成一个 rowset。而一个 Tablet 是由多个Rowset 组成的。每个 Rowset 都有一个对应的起始版本和终止版本。对于新增Rowset,起始版本和终止版本相同,表示为 [6-6]、[7-7] 等。多个Rowset经过 Compaction 形成一个大的 Rowset,起始版本和终止版本为多个版本的并集,如 [6-6]、[7-7]、[8-8] 合并后变成 [6-8]。
Rowset 的数量直接影响到 Compaction 是否能够及时完成。那么一批次导入会生成多少个 Rowset 呢?这里我们举一个例子:
假设集群有3个 BE 节点。每个BE节点2块盘。只有一张表,2个分区,每个分区3个分桶,默认3副本。那么总分片数量是(2 * 3 * 3)18 个,如果均匀分布在所有节点上,则每个盘上3个tablet。假设一次导入涉及到其中一个分区,则一次导入总共产生9个Rowset,即平均每块盘产生1-2个 Rowset。(这里仅考虑数据完全均匀分布的情况下,实际情况中,可能多个 Tablet 集中在某一块磁盘上。)
从上面的例子我们可以得出,rowset的数量直接取决于表的分片数量。举个极端的例子,如果一个Doris集群只有3个BE节点,但是有9000个分片。那么一次导入,每个BE节点就会新增3000个rowset,则至少要进行3000次compaction,才能处理完所有的分片。所以:
合理的设置表的分区、分桶和副本数量,避免过多的分片,可以降低Compaction的开销。
4. Base & Cumulative Compaction
Doris 中有两种 Compaction 操作,分别称为 Base Compaction(BC) 和 Cumulative Compaction(CC)。BC 是将基线数据版本(以0为起始版本的数据)和增量数据版本合并的过程,而CC是增量数据间的合并过程。BC操作因为涉及到基线数据,而基线数据通常比较大,所以操作耗时会比CC长。
如果只有 Base Compaction,则每次增量数据都要和全量的基线数据合并,写放大问题会非常严重,并且每次 Compaction 都相当耗时。因此我们需要引入 Cumulative Compaction 来先对增量数据进行合并,当增量数据合并后的大小达到一定阈值后,再和基线数据合并。这里我们有一个比较通用的 Compaction 调优策略:
在合理范围内,尽量减少 Base Compaction 操作。
BC 和 CC 之间的分界线成为 Cumulative Point(CP),这是一个动态变化的版本号。比CP小的数据版本会只会触发 BC,而比CP大的数据版本,只会触发CC。

整个过程有点类似 2048 小游戏:只有合并后大小足够,才能继续和更大的数据版本合并。

Compaction调优(二)
1. 数据分片选择策略
Compaction 的目的是合并多个数据版本,一是避免在读取时大量的 Merge 操作,二是避免大量的数据版本导致的随机IO。因此,Compaction 策略的重点问题,就是如何选择合适的 tablet,以保证节点上不会出现数据版本过多的数据分片。
Compaction 分数
一个自然的想法,就是每次都选择数据版本最多的数据分片进行 Compaction。这个策略也是 Doris 的默认策略。这个策略在大部分场景下都能很好的工作。但是考虑到一种情况,就是版本多的分片,可能并不是最频繁访问的分片。而 Compaction 的目的就是优化读性能。那么有可能某一张 “写多读少” 表一直在 Compaction,而另一张 “读多写少” 的表不能及时的 Compaction,导致读性能变差。
因此,Doris 在选择数据分片时还引入了 “读取频率” 的因素。“读取频率” 和 “版本数量” 会根据各自的权重,综合计算出一个 Compaction 分数,分数越高的分片,优先做 Compaction。这两个因素的权重由以下 BE 参数控制(取值越大,权重越高):
compaction_tablet_scan_frequency_factor:“读取频率” 的权重值,默认为 0。
compaction_tablet_compaction_score_factor:“版本数量” 的权重,默认为 1。
> “读取频率” 的权重值默认为0,即默认仅考虑 “版本数量” 这个因素。
生产者与消费者
Compaction 是一个 生产者-消费者 模型。由一个生产者线程负责选择需要做 Compaction 的数据分片,而多个消费者负责执行 Compaction 操作。
生产者线程只有一个,会定期扫描所有 tablet 来选择合适的 compaction 对象。因为 Base Compaction 和 Cumulative Compaction 是不同类型的任务,因此目前的策略是每生成 9 个 CC 任务,生成一个 BC 任务。任务生成的频率由以下两个参数控制:
cumulative_compaction_rounds_for_each_base_compaction_round:多少个CC任务后生成一个BC任务。
generate_compaction_tasks_min_interval_ms:任务生成的间隔。
> 这两个参数通常情况下不需要调整。
生产者线程产生的任务会被提交到消费者线程池。因为 Compaction 是一个IO密集型的任务,为了保证 Compaction 任务不会过多的占用IO资源,Doris 限制了每个磁盘上能够同时进行的 Compaction 任务数量,以及节点整体的任务数量,这些限制由以下参数控制:
compaction_task_num_per_disk:每个磁盘上的任务数,默认为2。该参数必须大于等于2,以保证 BC 和 CC 任务各自至少有一个线程。
max_compaction_threads:消费者线程,即Compaction线程的总数。默认为 10。
举个例子,假设一个 BE 节点配置了3个数据目录(即3块磁盘),每个磁盘上的任务数配置为2,总线程数为5。则同一时间,最多有5个 Compaction 任务在进行,而每块磁盘上最多有2个任务在进行。并且最多有3个 BC 任务在进行,因为每块盘上会自动预留一个线程给CC任务。
另一方面,Compaction 任务同时也是一个内存密集型任务,因为其本质是一个多路归并排序的过程,每一路是一个数据版本。如果一个 Compaction 任务涉及的数据版本很多,则会占用更多的内存,如果仅限制任务数,而不考虑任务的内存开销,则有可能导致系统内存超限。因此,Doris 在上述任务个数限制之外,还增加了一个任务配额限制:
total_permits_for_compaction_score:Compaction 任务配额,默认 10000。
每个 Compaction 任务都有一个配额,其数值就是任务涉及的数据版本数量。假设一个任务需要合并100个版本,则其配额为100。当正在运行的任务配额总和超过配置后,新的任务将被拒绝。
三个配置共同决定了节点所能承受的 Compaction 任务数量。
2. 数据版本选择策略
一个 Compaction 任务对应的是一个数据分片(Tablet)。消费线程拿到一个 Compaction 任务后,会根据 Compaction 的任务类型,选择 tablet 中合适的数据版本(Rowset)进行数据合并。下面分别介绍 Base Compaction 和 Cumulative Compaction 的数据分片选择策略。
Base Compaction
前文说过,BC 任务是增量数据和基线数据的合并任务。并且只有比 Cumulative Point(CP) 小的数据版本才会参与 BC 任务。因此,BC 任务的数据版本选取策略比较简单。
首先,会选取所有版本在 0 到 CP之间的 rowset。然后根据以下几个配置参数,判断是否启动一个 BC 任务:
base_compaction_num_cumulative_deltas:一次 BC 任务最小版本数量限制。默认为5。该参数主要为了避免过多 BC 任务。当数据版本数量较少时,BC 是没有必要的。
base_compaction_interval_seconds_since_last_operation:第一个参数限制了当版本数量少时,不会进行 BC 任务。但我们需要避免另一种情况,即某些 tablet 可能仅会导入少量批次的数据,因此当 Doris 发现一个 tablet 长时间没有执行过 BC 任务时,也会触发 BC 任务。这个参数就是控制这个时间的,默认是 86400,单位是秒。
> 以上两个参数通常情况下不需要修改,在某些情况下如何需要想尽快合并基线数据,可以尝试改小 base_compaction_num_cumulative_deltas 参数。但这个参数只会影响到 “被选中的 tablet”。而 “被选中” 的前提是这个 tablet 的数据版本数量是最多的。
Cumulative Compaction
CC 任务只会选取版本比 CP 大的数据版本。其本身的选取策略也比较简单,即从 CP 版本开始,依次向后选取数据版本。最终的数据版本集合由以下参数控制:
min_cumulative_compaction_num_singleton_deltas:一次 CC 任务最少的版本数量限制。这个配置是和 cumulative_size_based_compaction_lower_size_mbytes 配置同时判断的。即如果版本数量小于阈值,并且数据量也小于阈值,则不会触发 CC 任务。以避免躲过不比较的 CC 任务。默认是5。
max_cumulative_compaction_num_singleton_deltas:一次 CC 任务最大的版本数量限制。以防止一次 CC 任务合并的版本数量过多,占用过多资源。默认是1000。
cumulative_size_based_compaction_lower_size_mbytes:一次 CC 任务最少的数据量,和min_cumulative_compaction_num_singleton_delta 同时判断。默认是 64,单位是 MB。
简单来说,默认配置下,就是从 CP 版本开始往后选取 rowset。最少选5个,最多选 1000 个,然后判断数据量是否大于阈值即可。
CC 任务还有一个重要步骤,就是在合并任务结束后,设置新的 Cumulative Point。CC 任务合并完成后,会产生一个合并后的新的数据版本,而我们要做的就是判断这个新的数据版是 “晋升” 到 BC 任务区,还是依然保留在 CC 任务区。举个例子:
假设当前 CP 是 10。有一个 CC 任务合并了 [10-13] [14-14] [15-15] 后生成了 [10-15] 这个版本。如果决定将 [10-15] 版本移动到 BC 任务区,则需修改 CP 为 15,否则 CP 保持不变,依然为 10。
CP 只会增加,不会减少。以下参数决定了是否更新 CP:
cumulative_size_based_promotion_ratio:晋升比率。默认 0.05。
cumulative_size_based_promotion_min_size_mbytes:最小晋升大小,默认 64,单位 MB。
cumulative_size_based_promotion_size_mbytes:最大晋升大小,默认 1024,单位 MB。
以上参数比较难理解,这里我们先解释下 “晋升” 的原则。一个 CC 任务生成的 rowset 的晋升原则,是其数据大小和基线数据的大小在 “同一量级”。这个类似 2048 小游戏,只有相同的数字才能合并形成更大的数字。而上面三个参数,就是用于判断一个新的rowset是否匹配基线数据的数量级。举例说明:
在默认配置下,假设当前基线数据(即所有 CP 之前的数据版本)的数据量为 10GB,则晋升量级为 (10GB * 0.05)512MB。这个数值大于 64 MB 小于 1024 MB,满足条件。所以如果 CC 任务生成的新的 rowset 的大小大于 512 MB,则可以晋升,即 CP 增加。而假设基线数据为 50GB,则晋升量级为(50GB * 0.05)2.5GB。这个数值大于 64 MB 也大于 1024 MB,因此晋升量级会被调整为 1024 MB。所以如果 CC 任务生成的新的 rowset 的大小大于 1024 MB,则可以晋升,即 CP 增加。
从上面的例子可以看出,cumulative_size_based_promotion_ratio 用于定义 “同一量级”,0.05 即表示数据量大于基线数据的 5% 的 rowset 都有晋升的可能,而 cumulative_size_based_promotion_min_size_mbytes 和 cumulative_size_based_promotion_size_mbytes 用于保证晋升不会过于频繁或过于严格。
> 这三个参数会直接影响 BC 和 CC 任务的频率,尤其在高频导入场景下需要适当调整。我们会在后续文章中举例说明。
3. 其他 Compaction 参数和注意事项
还有一些参数和 Compaction 相关,在某些情况下需要修改:
disable_auto_compaction:默认为 false,修改为 true 则会禁止 Compaction 操作。该参数仅在一些调试情况,或者 compaction 异常需要临时关闭的情况下才需使用。
Delete 灾难
通过 DELETE FROM 语句执行的数据删除操作,在 Doris 中也会生成一个数据版本用于标记删除。这种类型的数据版本比较特殊,我们成为 “删除版本”。删除版本只能通过 Base Compaction 任务处理。因此在在遇到删除版本时,Cumulative Point 会强制增加,将删除版本移动到 BC 任务区。因此数据导入和删除交替发生的场景通常会导致 Compaction 灾难。比如以下版本序列:
[11-11] 删除版本
[12-12]
[13-13] 删除版本
[14-14]
[15-15] 删除版本
[16-16]
[17-17] 删除版本
...在这种情况下,CC 任务几乎不会被触发(因为CC任务只能选择一个版本,而无法处理删除版本),所有版本都会交给 Base Compaction 处理,导致 Compaction 进度缓慢。目前Doris还无法很好的处理这种场景,因此需要在业务上尽量避免。
Compaction调优(三)
1. 什么情况下需要调整 Compaction 参数
Compaction 的目的是合并多个数据版本,一是避免在读取时大量的 Merge 操作,二是避免大量的数据版本导致的随机IO。并且在这个过程中,Compaction 操作不能占用太多的系统资源。所以我们可以以结果为导向,从以下两个方面反推是否需要调整 Compaction 策略。
检查数据版本是否有堆积。 检查 IO 和内存资源是否被 Compaction 任务过多的占用。
查看数据版本数量变化趋势
Doris 提供数据版本数量的监控数据。如果你部署了 Prometheus + Grafana 的监控,则可以通过 Grafana 仪表盘的 BE Base Compaction Score 和 BE Cumu Compaction Score 图表查看到这个监控数据的趋势图:
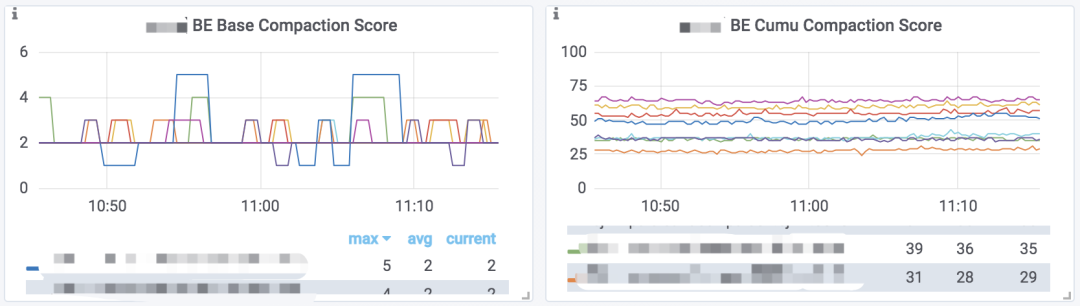
> 这个图表展示的是每个 BE 节点,所有 Tablet 中数据版本最多的那个 Tablet 的版本数量,可以反映出当前版本堆积情况。
> 部署方式参阅:http://doris.incubator.apache.org/master/zh-CN/administrator-guide/operation/monitor-alert.html
如果没有安装这个监控,如果你是用的 Palo 0.14.7 版本以上,也可以通过以下命令在命令行查看这个监控数据的趋势图:
mysql> ADMIN SHOW BACKEND METRIC ("nodes" = "30746894", "metrics" = "BE_BASE_COMPACTION_SCORE", "time" = "last 4 hours");
mysql> ADMIN SHOW BACKEND METRIC ("nodes" = "30746894", "metrics" = "BE_CUMU_COMPACTION_SCORE", "time" = "last 4 hours");
> 该命令具体帮助可执行 HELP ADMIN SHOW METRIC 查看
注意这里有两个指标,分别表示 Base Compaction 和 Cumulative Compaction 所对应的版本数量。在大部分情况下,我们只需要查看 Cumulative Compaction 的指标,即可大致了解集群的数据版本堆积情况。
版本是否堆积没有一个明确的界限,而是根据使用场景和查询延迟进行判断的一个经验值。我们可以按照以下步骤进行简单的推断:
观察数据版本数量的趋势,如果趋势平稳,则说明 Compaction 和导入速度基本持平。如果呈上升态势,则说明 Compaction 速度跟不上导入速度了。如果呈下降态势,说明 Compaction 速度超过了导入速度。如果呈上升态势,或在平稳状态但数值较高,则需要考虑调整 Compaction 参数以加快 Compaction 的进度。
通常版本数量维持在 100 以内可以视为正常。而在大部分批量导入或低频导入场景下,版本数量通常为10-20甚至更低。
查看Compaction资源占用
Compaction 资源占用主要是 IO 和 内存。
对于 Compaction 占用的内存,可以在浏览器打开以下链接:
http://be_host:webserver_port/mem_tracker
在搜索框中输入 AutoCompaction:

则可以查看当前Compaction的内存开销和历史峰值开销。
而对于 IO 操作,目前还没有提供单独的 Compaction 操作的 IO 监控,我们只能根据集群整体的 IO 利用率情况来做判断。我们可以查看监控图 Disk IO util:
或者通过命令在命令行查看(Palo 0.14.7 以上版本):
mysql> ADMIN SHOW BACKEND METRIC ("nodes" = "30746894", "metrics" = "BE_DISK_IO", "time" = "last 4 hours");
这个监控展示的是每个 BE 节点上磁盘的 IO util 指标。数值越高表示IO越繁忙。当然大部分情况下 IO 资源都是查询请求消耗的,这个监控主要用于指导我们是否需要增加或减少 Compaction 任务数。
2. Compaction 调优策略
如果版本数量有上升趋势或者数值较高,则可以从以下两方面优化 Compaction:
修改 Compaction 线程数,使得同时能够执行更多的 Compaction 任务。 优化单个 Compaction 的执行逻辑,使数据版本数量维持在一个合理范围。
优化前的准备工作
在优化 Compaction 执行逻辑之前,我们需要使用一些命令来进一步查看一些Compaction的细节信息。
首先,我们通过监控图找到一个版本数量最高的 BE 节点。然后执行以下命令分析日志:
$> grep "succeed to do base" log/be.INFO.log.20210505-142010 |tail -n 100
$> grep "succeed to do cumu" log/be.INFO.log.20210505-142010 |tail -n 100
以上两个命令可以查看最近100个执行完成的 compaction 任务:
I0505 17:06:56.143455 675 compaction.cpp:135] succeed to do cumulative compaction. tablet=106827682.505347040.d040c1cdf71e5c95-3a002a06127ccd86, output_version=2-2631, current_max_version=2633, disk=/home/disk6/palo.HDD, segments=57. elapsed time=2.29371s. cumulative_compaction_policy=SIZE_BASED.
I0505 17:06:56.520058 666 compaction.cpp:135] succeed to do cumulative compaction. tablet=106822189.1661856168.654562832a620ea6-46fe84c73ea84795, output_version=2-3247, current_max_version=3250, disk=/home/disk2/palo.HDD, segments=22. elapsed time=2.66858s. cumulative_compaction_policy=SIZE_BASED.
通过日志时间可以判断 Compaction 是否在持续正确的执行,通过 elapsed time 可以观察每个任务的执行时间。
我们还可以执行以下命令展示最近100个 compaction 任务的配额(permits):
$> grep "permits" log/be.INFO |tail -n 100
I0505 17:04:07.120920 667 compaction.cpp:83] start cumulative compaction. tablet=106827970.777011641.9c474de1b8ba9199-4addeb135d6834ac, output_version=2-2623, permits: 39
I0505 17:04:13.898777 672 compaction.cpp:83] start cumulative compaction. tablet=106822777.1948936074.a44ac9462e79b76d-4a33ee39559bb0bf, output_version=2-3238, permits: 22
配额和版本数量成正比。
我们可以找到 permits 较大的一个任务对应的 tablet id,如上图permit 为 39 的任务的 tablet id 为 106827970,然后继续分析这个 tablet 的 compaction 情况。
通过 MySQL 客户端连接 Doris 集群后,执行:
mysql> show tablet 106827970;
+--------------------------+-----------+---------------+-----------+---------+----------+-------------+----------+--------+----------------------------------------------------------------------------+
| DbName | TableName | PartitionName | IndexName | DbId | TableId | PartitionId | IndexId | IsSync | DetailCmd |
+--------------------------+-----------+---------------+-----------+---------+----------+-------------+----------+--------+----------------------------------------------------------------------------+
| default_cluster:test | tbl1 | p20210505 | tbl1 | 3828954 | 63708800 | 106826829 | 63709761 | true | SHOW PROC '/dbs/3828954/63708800/partitions/106826829/63709761/106827970'; |
+--------------------------+-----------+---------------+-----------+---------+----------+-------------+----------+--------+----------------------------------------------------------------------------+
然后执行后面的 SHOW PROC 语句,我们可以获得这个 tablet 所有副本的详细信息。其中 VersionCount 列表示对应副本的数据版本数量。我们可以选取一个 VersionCount 较大的副本,在浏览器打开 CompactionStatus 列显示的 URL,得到如下Json结果:
{
"cumulative policy type": "SIZE_BASED",
"cumulative point": 18438,
"last cumulative failure time": "1970-01-01 08:00:00.000",
"last base failure time": "1970-01-01 08:00:00.000",
"last cumulative success time": "2021-05-05 17:18:48.904",
"last base success time": "2021-05-05 16:14:49.786",
"rowsets": [
"[0-17444] 13 DATA NONOVERLAPPING 0200000000b1fb8d344f83103113563dd81740036795499d 2.86 GB",
"[17445-17751] 1 DATA NONOVERLAPPING 0200000000b25183344f83103113563dd81740036795499d 68.61 MB",
"[17752-18089] 1 DATA NONOVERLAPPING 0200000000b2b9a2344f83103113563dd81740036795499d 74.52 MB",
"[18090-18437] 1 DATA NONOVERLAPPING 0200000000b32686344f83103113563dd81740036795499d 76.41 MB",
"[18438-18678] 1 DATA NONOVERLAPPING 0200000000b37084344f83103113563dd81740036795499d 53.07 MB",
"[18679-18679] 1 DATA NONOVERLAPPING 0200000000b36d87344f83103113563dd81740036795499d 3.11 KB",
"[18680-18680] 1 DATA NONOVERLAPPING 0200000000b36d70344f83103113563dd81740036795499d 258.40 KB",
"[18681-18681] 1 DATA NONOVERLAPPING 0200000000b36da0344f83103113563dd81740036795499d 266.98 KB",
],
"stale_rowsets": [
],
"stale version path": [
]
}
这里我们可以看到一个 tablet 的 Cumulative Point,最近一次成功、失败的 BC/CC 任务时间,以及每个 rowset 的版本信息。如上面这个示例,我们可以得出以下结论:
基线数据量大约在2-3GB,增量rowset增长到几十MB后就会晋升到BC任务区。 新增rowset数据量很小,且版本增长较快,说明这是一个高频小批量的导入场景。
我们还可以进一步的通过以下命令分析指定 tablet id 的日志:
# 查看 tablet 48062815 最近十个任务的配额情况
$> grep permits log/be.INFO |grep 48062815 |tail -n 10
# 查看 tablet 48062815 最近十个执行完成的 compaction 任务
$> grep "succeed to do" log/be.INFO |grep 48062815 |tail -n 10
另外,我们还可以在浏览器打开以下 URL,查看一个 BE 节点当前正在执行的 compaction 任务:
be_host:webserver_port/api/compaction/run_status
{
"CumulativeCompaction": {
"/home/disk2/palo": [],
"/home/disk1/palo": [
"48061239"
]
},
"BaseCompaction": {
"/home/disk2/palo": [],
"/home/disk1/palo": [
"48062815",
"48061276"
]
}
}
这个接口可以看到每个磁盘上当前正在执行的 compaction 任务。
通过以上一系列的分析,我们应该可以对系统的 Compaction 情况有以下判断:
Compaction 任务的执行频率、每个任务大致的执行耗时。 指定节点数据版本数量的变化情况。 指定 tablet 数据版本的变化情况,以及 compaction 的频率。
这些结论将指导我们对 Compaction 进行调优。
修改 Compaction 线程数
增加 Compaction 线程数是一个非常直接的加速 Compaction 的方法。但是更多的任务意味着更大的 IO 和 内存开销。尤其在机械磁盘上,因为随机读写问题,有时可能单线程串行执行的效率会高于多线程并行执行。Doris 默认配置为每块盘两个 Compaction 任务(这也是最小的合法配置),最多 10 个任务。如果磁盘数量多于 5,在内存允许的情况下,可以修改 max_compaction_threads 参数增加总任务数,以保证每块盘可以执行两个 Compaction 任务。
对于机械磁盘,不建议增加每块盘的任务数。对于固态硬盘,可以考虑修改 compaction_task_num_per_disk 参数适当增加每块盘的任务数,如修改为 4。注意修改这个参数的同时可能还需同步修改 max_compaction_threads,使得 max_compaction_threads 大于等于 compaction_task_num_per_disk * 磁盘数量。
优化单个 Compaction 任务逻辑
这个优化方式比较复杂,我们尝试从几个场景出发来说明:
场景一:基线数据量大,Base Compaction 任务执行时间长。
BC 任务执行时间长,意味着一个任务会长时间占用 Compaction 工作线程,从而导致其他 tablet 的 compaction 任务时间被挤占。如果是因为 0 号版本的基线数据量较大导致,则我们可以考虑尽量推迟增量rowset 晋升到 BC 任务区的时间。以下两个参数将影响这个逻辑:
cumulative_size_based_promotion_ratio:默认 0.05,基线数据量乘以这个系数,即晋升阈值。可以调大这个系数来提高晋升阈值。
cumulative_size_based_promotion_size_mbytes:默认 1024MB。如果增量rowset的数据量大于这个值,则会忽略第一个参数的阈值直接晋升。因此需要同时调整这个参数来提升晋升阈值。
当然,提升晋升阈值,会导致单个 BC 任务需要处理更大的数据量,耗时更长,但是总体的数据量会减少。举个例子。基线数据大小为 1024GB,假设晋升阈值分别为 100MB 和 200MB。数据导入速度为 100MB/分钟。每5个版本执行一次 BC。那么理论上在10分钟内,阈值为 100MB 时,BC 任务处理的总数据量为 (1024 + 100 * 5)* 2 = 3048MB。阈值为 200MB 是,BC 任务处理的总数据量为 (1024 + 200 * 5) = 2024 MB。
场景二:增量数据版本数量增长较快,Cumulative Compaction 处理过多版本,耗时较长。
max_cumulative_compaction_num_singleton_deltas 参数控制一个 CC 任务最多合并多少个数据版本,默认值为 1000。我们考虑这样一种场景:针对某一个 tablet,其数据版本的增长速度为 1个/秒。而其 CC 任务的执行时间 + 调度时间是 1000秒(即单个 CC 任务的执行时间加上Compaction再一次调度到这个 tablet 的时间总和)。那么我们可能会看到这个 tablet 的版本数量在 1-1000之间浮动(这里我们忽略基线版本数量)。因为在下一次 CC 任务执行前的 1000 秒内,又会累积 1000 个版本。
这种情况可能导致这个 tablet 的读取效率很不稳定。这时我们可以尝试调小 max_cumulative_compaction_num_singleton_deltas 这个参数,这样一个 CC 所要合并的版本数更少,执行时间更短,执行频率会更高。还是刚才这个场景,假设参数调整到500,而对应的 CC 任务的执行时间 + 调度时间也降低到 500,则理论上这个 tablet 的版本数量将会在 1-500 之间浮动,相比于之前,版本数量更稳定。
当然这个只是理论数值,实际情况还要考虑任务的具体执行时间、调度情况等等。
3. 手动 Compaction
某些情况下,自动 Compaction 策略可能无法选取到某些 tablet,这时我们可能需要通过 Compaction 接口来主动触发指定 tablet 的 Compaction。我们以 curl 命令举例:
curl -X POST http://192.168.1.1:8040/api/compaction/run?tablet_id=106818600\&schema_hash=6979334\&compact_type=cumulative
这里我们指定 id 为 106818600,schema hash 为 6979334 的 tablet 进行 Cumulative Compaction(compact_type参数为 base 则触发 Base Compaction)。其中 schema hash 可以通过 SHOW TABLET tablet_id 命令得到的 SHOW PROC 命令获取。
如果提交成功,则会返回:
{"status": "Success", "msg": "compaction task is successfully triggered."}
这是一个异步操作,命令只是提交compaction 任务,之后我们可以通过以下 API 来查看任务是否在运行:
curl -X GET http://192.168.1.1:8040/api/compaction/run_status?tablet_id=106818600\&schema_hash=6979334
返回结果:
{
"status" : "Success",
"run_status" : false,
"msg" : "compaction task for this tablet is running",
"tablet_id" : 106818600,
"schema_hash" : 6979334,
"compact_type" : "cumulative"
}
当然也可以直接查看 tablet 的版本情况:
curl -X GET http://192.168.1.1:8040/api/compaction/show?tablet_id=106818600\&schema_hash=6979334