
【NLP】如何在文本分类任务中Fine-Tune BERT
 问 题
问 题 目 标
目 标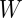 是task specific层的参数,最后通过最大化log-probability of correct label优化模型参数。
是task specific层的参数,最后通过最大化log-probability of correct label优化模型参数。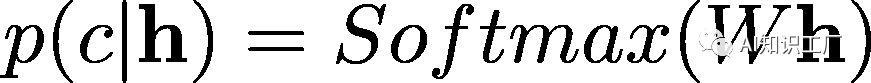
 方 法
方 法How to Fine-Tune BERT for Text Classification?[1]这篇论文从四个方面对BERT(BERT base)进行不同形式的pretrain和fine-tune,并通过实验展示不同形式的pretrain和fine-tune之间的效果对比。
当我们在特定任务上fine-tune BERT的时候,往往会有多种方法利用Bert,举个例子:BERT的不同层往往代表着对不同语义或者语法特征的提取,并且对于不同的任务,不同层表现出来的重要性和效果往往不太一样。因此如何利用类似于这些信息,以及如何选择一个最优的优化策略和学习率将会影响最终fine-tune 的效果。
对于长文本的处理
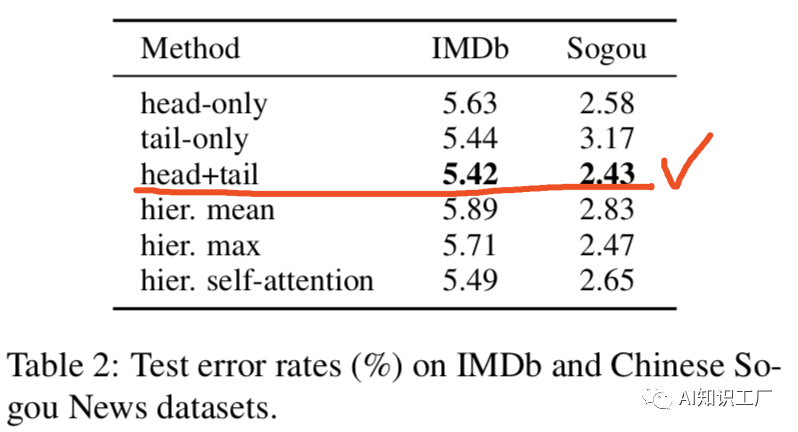
Fine-tune层的选择
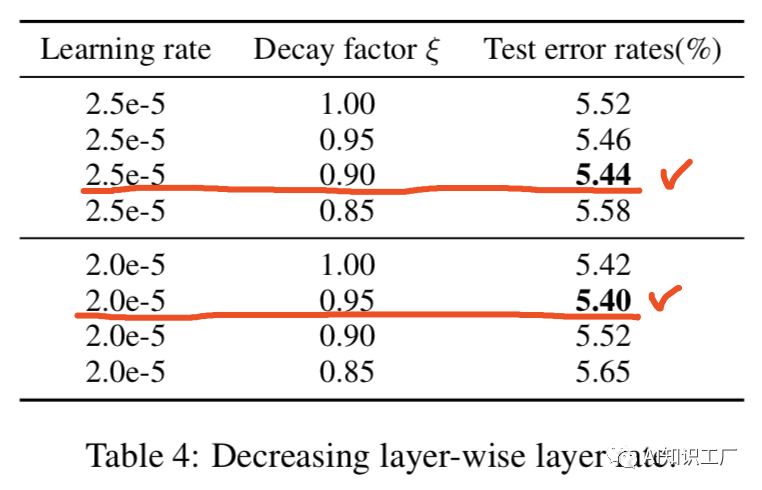
学习率优化策略
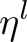 代表第l层的学习率,我们设定base learning rate为
代表第l层的学习率,我们设定base learning rate为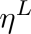 ,代表顶层的学习率,其他层的策略如公式(2)所示,其中
,代表顶层的学习率,其他层的策略如公式(2)所示,其中 是衰减系数,如果
是衰减系数,如果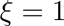 ,那么每层的学习率是一样的,如果
,那么每层的学习率是一样的,如果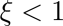 ,那么越往下的层学习率就越低。
,那么越往下的层学习率就越低。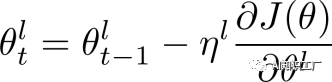 (1)
(1)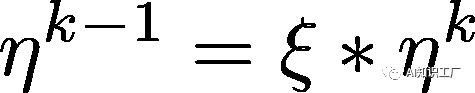 (2)
(2)
灾难性遗忘问题
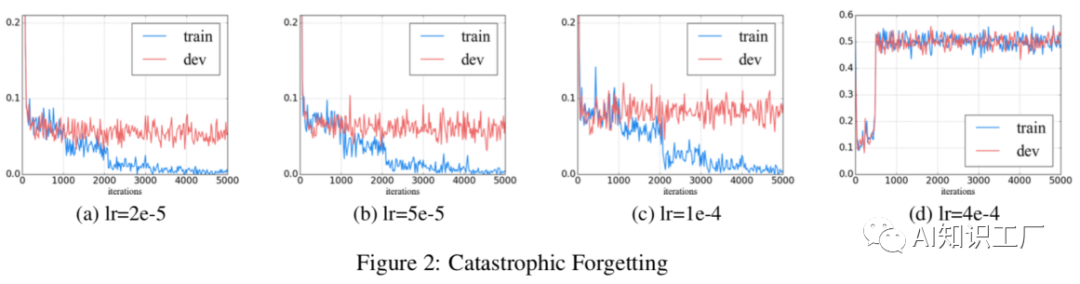
任务内进一步预训练:
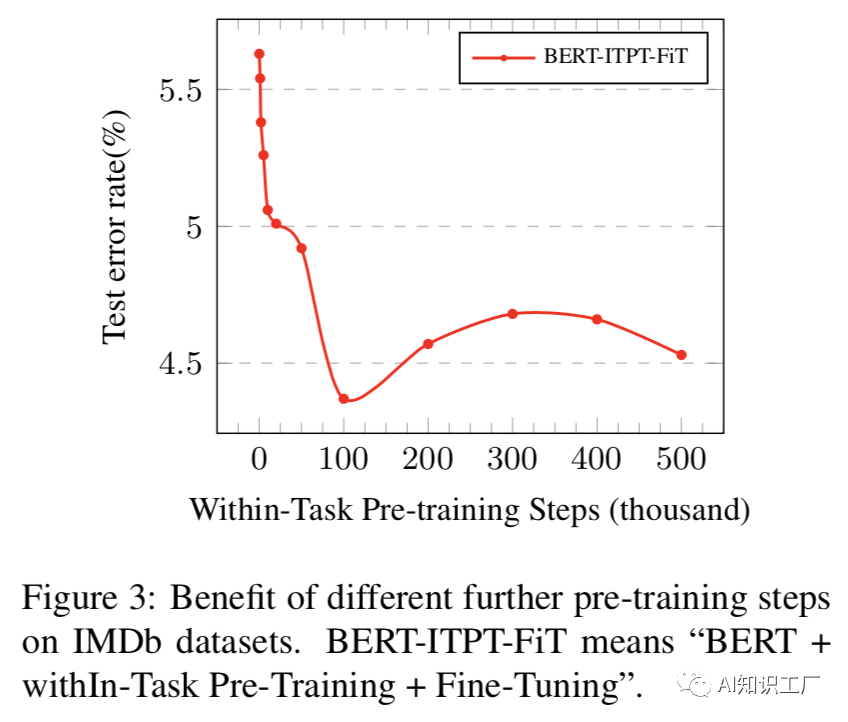
领域内和交叉域内的进一步预训练:
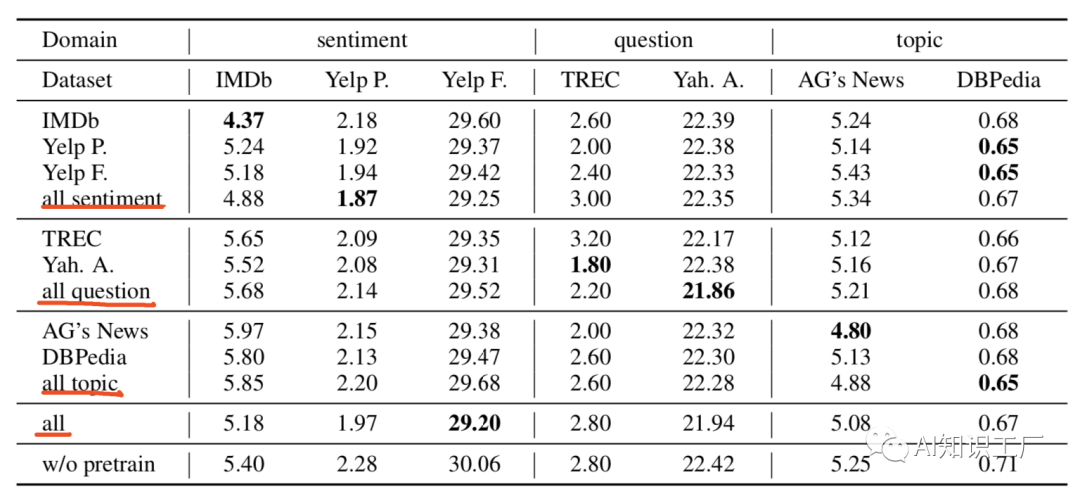
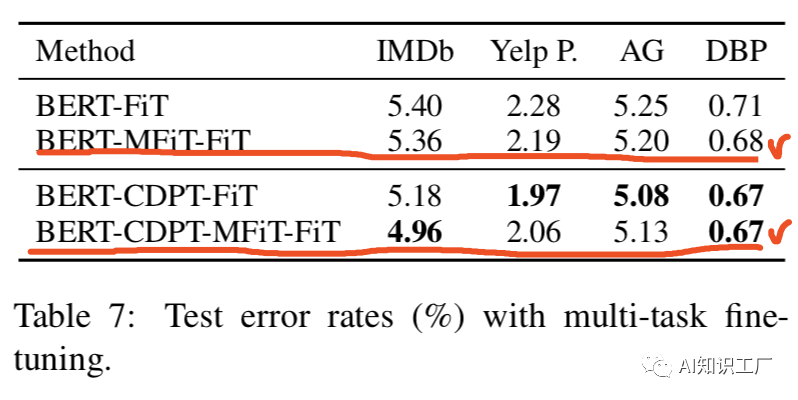
BERT-FiT = “BERT + Fine-Tuning”.
BERT-CDPT-MFiT-FiT = “BERT + Cross-Domain Pre-Training+Multi-Task Pre-Training+ Fine-Tuning”.(先在交叉域上做pretrain,然后在多任务域上做pretrain,最后在target-domian上做fine-tune)

往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码:
评论