
揭开KPI异常检测顶级AI模型面纱(1)
原子弹从入门到精通
GDE全球开发者大赛-KPI异常检测告一段落,来自深圳福田莲花街道的“原子弹从入门到精通“有幸取得了总榜TOP1的成绩,下面给出他的解决方案。
01
背景介绍

评估指标:
本赛题采用F1作为评估指标,具体计算公式如下:
P = TP/(TP+FP)
R = TP/(TP+FN)
F1 = 2*P*R/(P+R)

02
数据探索
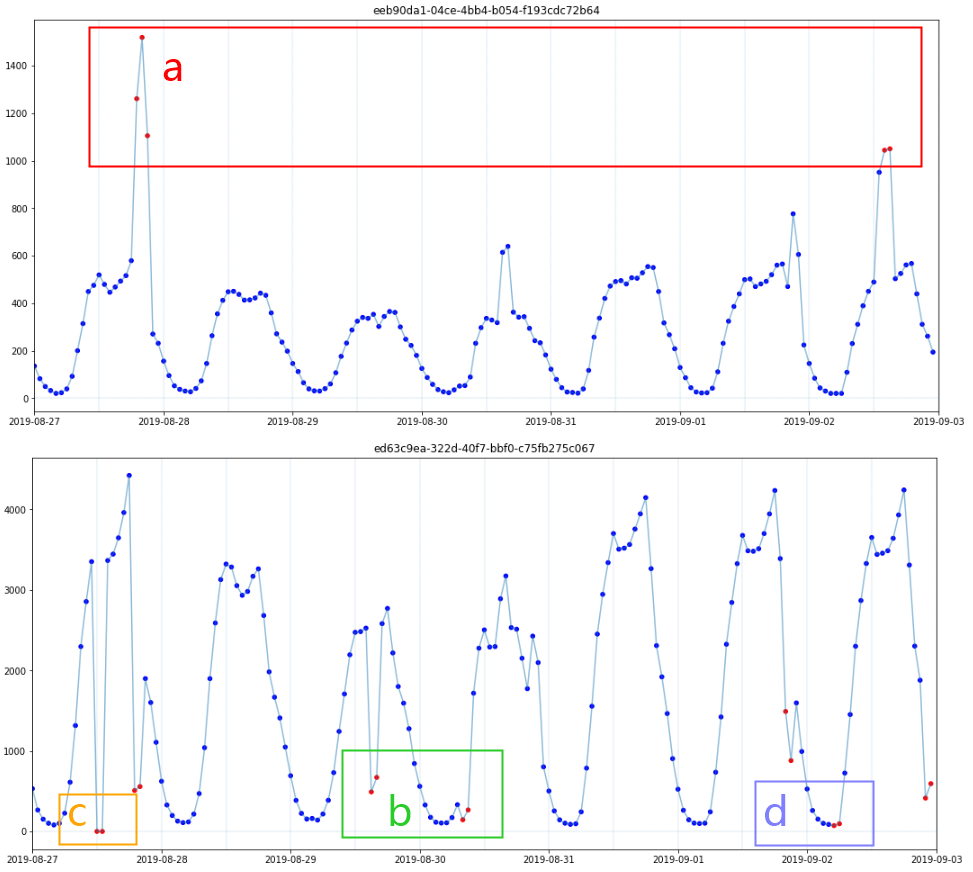
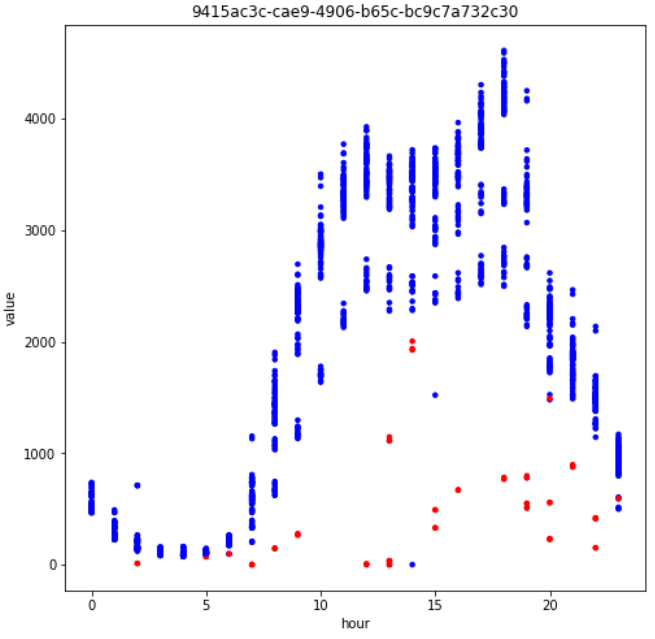
如Fig3中a部分(红框)所示,边界型异常中异常样本的取值范围与正常值取值完全不同,即存在明确的决策边界可以完全分离异常点。
如Fig3中b部分(绿框)所示,正常样本点的走势往往沿着一个趋势,而趋势破坏型的异常点会偏离这个趋势,但取值范围可能仍然在正常样本的取值范围内,这类异常与相邻点的差异较大,与相同时刻正常点的取值差异也较大。
如Fig3中c部分(橙框)所示,此类异常取值直接为0,根据我对业务的理解,正常的KPI不应出现0值,根据分析,20个KPI中有19个正常取值均不应为0,仅1个KPI正常取值为0,非0则为异常。
如Fig3中d部分(紫框)所示,此类异常往往既没有破坏趋势,取值也在正常的范围内,但可能会偏离相同时刻的正常取值。
03
解题思路
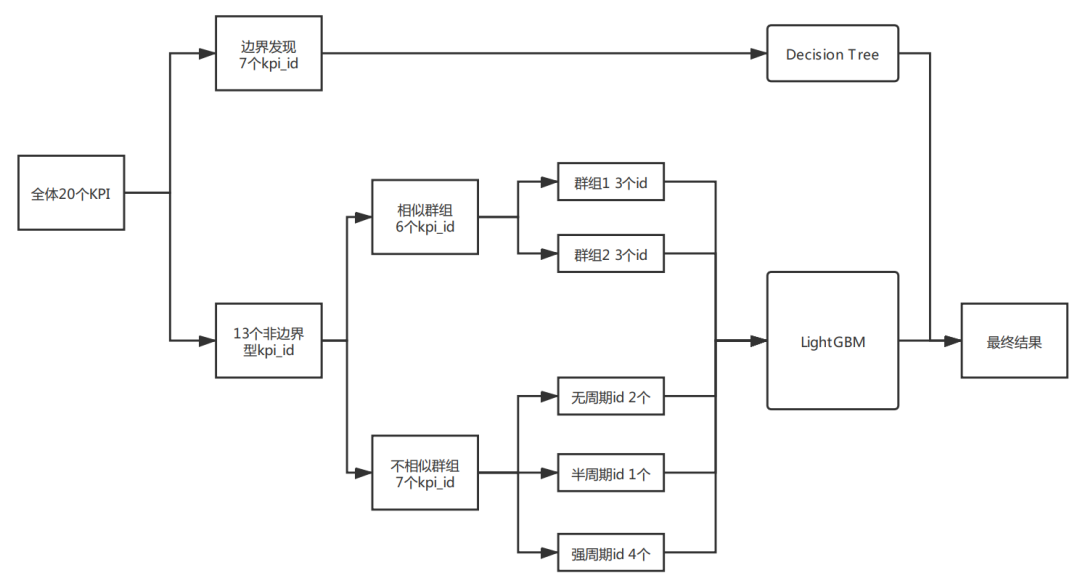
赛题中共有20个不同的KPI,KPI物理意义不同且异常的种类也多种多样,若将所有KPI作为一个整体建立一个统一的二分类模型,模型效果差强人意,难以进入前排,但若对每个KPI单独建模,则需要建立并维护调优至少20个不同的模型,维护成本过高,因此我的思路是将KPI或异常进行分类建模。
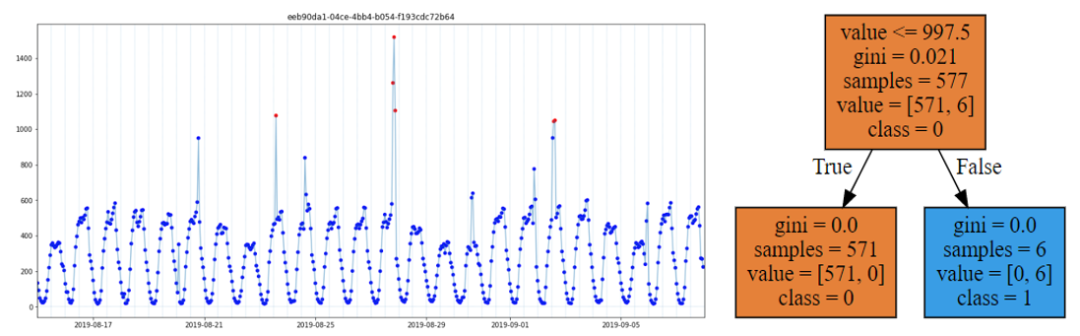
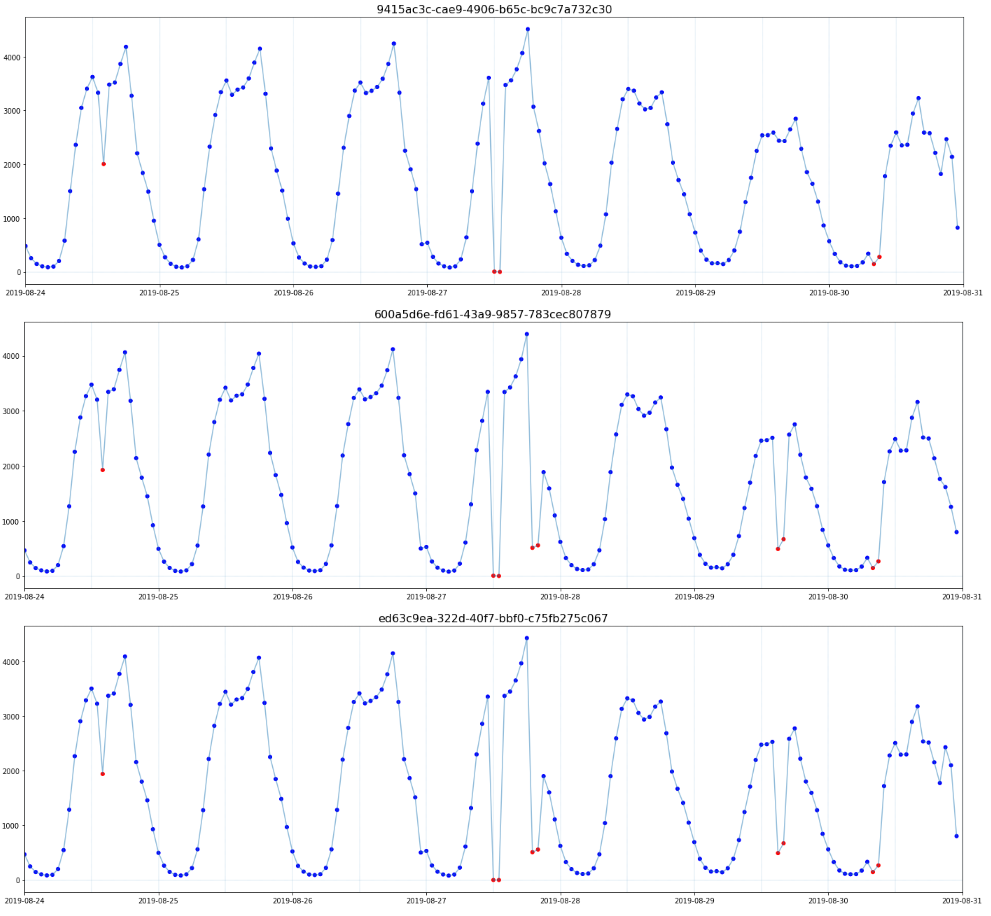
决策树会根据目标的分布将样本划分在不同的特征空间范围内(如Fig4 所示),非常适合用于边界的发现与确定。因此针对边界型异常,即好坏样本取值完全不同的异常,我采用决策树进行边界的自动发现与确定,具体如下:
04
特征构造
05
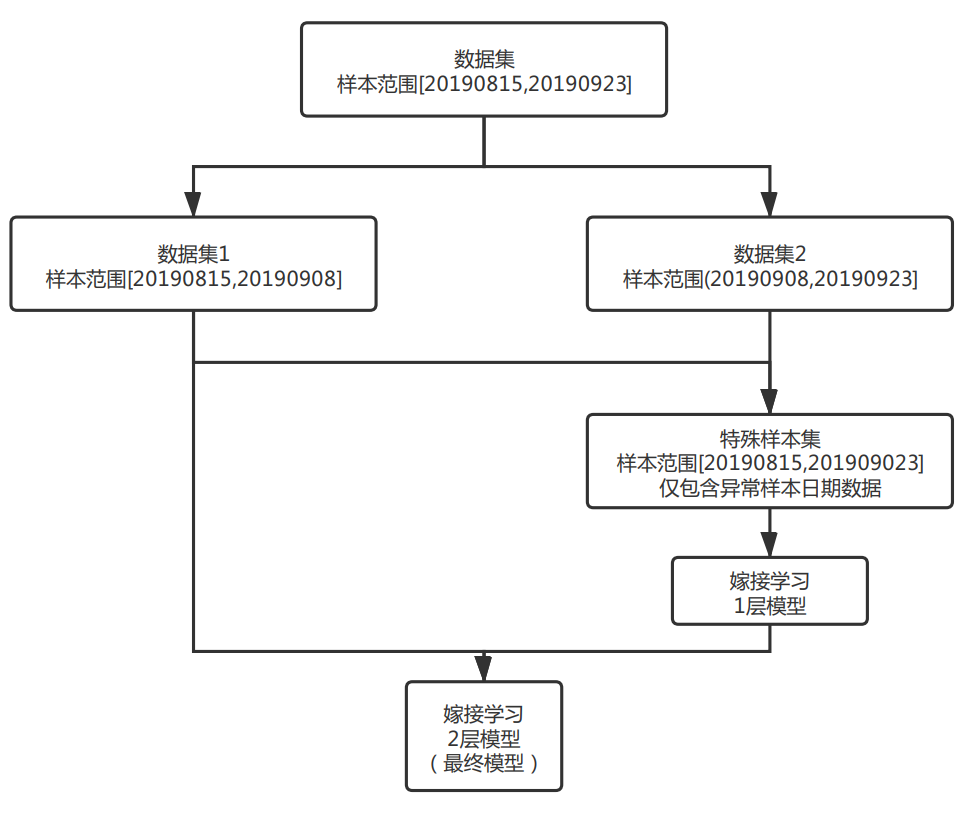
模型方案
06
鸣谢
非常感谢希旭哥,苕芸博士,素颜姐,小爱姐等人在比赛过程中的帮助与指导,希旭哥还是一如既往的热情,总能在第一时间为大家答疑解惑。
加群交流学习