
AI新视界:揭开AI大模型的黑魔法面纱

全文字数:8600字,阅读时间:30分钟
本文来自智次方直播:AI新视界:揭开AI大模型的黑魔法面纱
点击上方蓝色文字

关注我们
金秋9月,智次方与智用人工智能应用研究院携手推出AI大模型系列公开课,从认知、应用、商业、安全等不同方向,带您领略AI大模型的魅力与应用前景。
9月6日晚,智用研究院首席数字规划师 赵铭老师以“AI新视界:揭开AI大模型的黑魔法面纱”为主题进行了一次深度内容分享。
以下根据直播内容整理:
“大模型”的进化历程
人工智能的领域非常广泛,基本上在计算机科学领域中,能够模仿人类思维和决策的都被称为人工智能。这个领域非常庞大,其中有许多不同的方法,但最终都可以实现类似的功能。
在上世纪90年代左右,出现了一种叫做机器学习的流派。其思想是如果我们把好多历史数据输入到模型中,它就可以帮我们生成一条趋势线,类似于股票的K线图,我们可以用它来预测未来可能发生的事情。
到了大约2010年前后,在机器学习领域中出现了一个小流派——深度学习。人们开始使用一种新的架构来实现趋势的发现,这个架构叫做深层神经网络。这个架构是从模拟人类思维方式、模拟人类大脑中得来的。随着大家对大脑的了解越来越多,发现大脑皮层中有很多神经元,虽然不知道这些神经元如何工作,但是我们可以模仿神经元来构建多层神经网络,一层一层地将一个大任务分解成许多小任务,让许多神经元一起工作。基于这个理念,人们开始研究生成神经网络算法和框架,这就是深度学习的起源。
深度学习强调“迁移学习”的概念。不要被这些听起来很高大上的名词迷惑,迁移学习的原理也很简单。以前的机器学习想法是,如果我研究了过去的股票价格,我就能预测未来的股市会涨还是跌。迁移学习的思想类似于如果我研究了股票市场的涨跌,我是否也可以用这个模型去预测期货市场,或者用这个模型去预测货币市场。目的是用一个任务学习知识,然后将这个知识应用到另一个任务中,就像学习可以迁移一样。
随着深度学习的继续发展,大家慢慢发现无论如何研究下去,最基础的模型的共性是一样的。我们称这一类非常基础的、有共性的模型为“基础模型”。实际上,基础模型并不新颖,已经出现很多年了。其实大家每天都在接触基础模型,比如,有人在开新款的新能源的车型,它有L2级别的自动驾驶,这一功能是靠车里面的摄像头或传感器,来探测前方是否有障碍物,探测车道的位置,然后使得车辆行驶在道路中间。这是视觉探测。视觉探测就是生成神经网络里面的基础模型在运作,也是Resnet做的事情,或者说基于Resnet衍生出来的大量图像识别技术、视频识别技术,都是在基础模型之上做出来的。
在基础模型的发展中,就开始出现了大模型。实际上大模型就是基础模型里面的一个分类。那么为什么叫它“大”呢?是因为以前的基础模型没有用到那么多的数据和参数。而大模型里面用到的模型非常特别,它用到了大量的数据、大量的计算,而且具有大范围的通用性。
为了让大家对“数据到底有多大”有一个感性的认识,我来举个例子。支撑你每天完成L2级别自动驾驶的Resnet这种图像识别技术一般用到多少参数?它的参数级别大概是个位数的亿,比如说2亿到5亿这样一个级别。当然,现在的视觉引擎,比如说有一些摄像头可以识别到人有没有在笑,这个人的年龄到底是50岁还是30岁,这都是基于Resnet类似的技术发展出来的。它的参数也会越来越多,但再怎么多其实也就是在几亿到几十亿这样一个参数。到达十几二十亿参数的,说明这个图像模型已经非常强大了。
但是我们今天讲的大模型,是一个叫Transformer的模型。这个模型非常强大,它的参数可以达到多少呢?它是以几十亿为起步的。我们经常听到的是65亿个参数。但这只是它的起步值,而我们现在主流使用的大模型,能够完成一些绘画任务的,基本上都在百亿甚至千亿级别。当然,今天很多人使用的ChatGPT模型,一般达到什么参数级别呢?至少是百亿起步,而百亿只是起步点。作为一个玩家,如果你想要做得更好,你需要有大几百亿的参数量,甚至到千亿级、万亿级。
实际上,业界已经开始探讨万亿级参数的某些大模型要大到什么程度,既然参数量如此之大,计算量也非常惊人,以前我们的那些视觉训练,可能只需要一台电脑和一张好一点的显卡就可以运行。但如今我们发现英伟达公司非常厉害,只有他们的机器才能运行Transformer模型,而且不是一台机器,是一个由多台机器组成的集群来运行。这是因为它的数据量和参数量太大了,只有这样庞大的机器才能承受。但一旦运行起来,你会发现它非常强大,可以支持很多东西,这也完美的诠释了我们刚才提到的迁移学习的任务。你让它训练中文,然后你会发现它也能用英文完成任务。你让它训练古诗词,然后你会发现它也可以用于写其他古代文学。你让它来训练医学,你会发现它也能稍微懂一点法律。只要给它足够的语料来训练,它的迁移学习就能做得非常好。
这就是从机器学习发展到现在大模型的发展历程。
人工智能发展的3要素
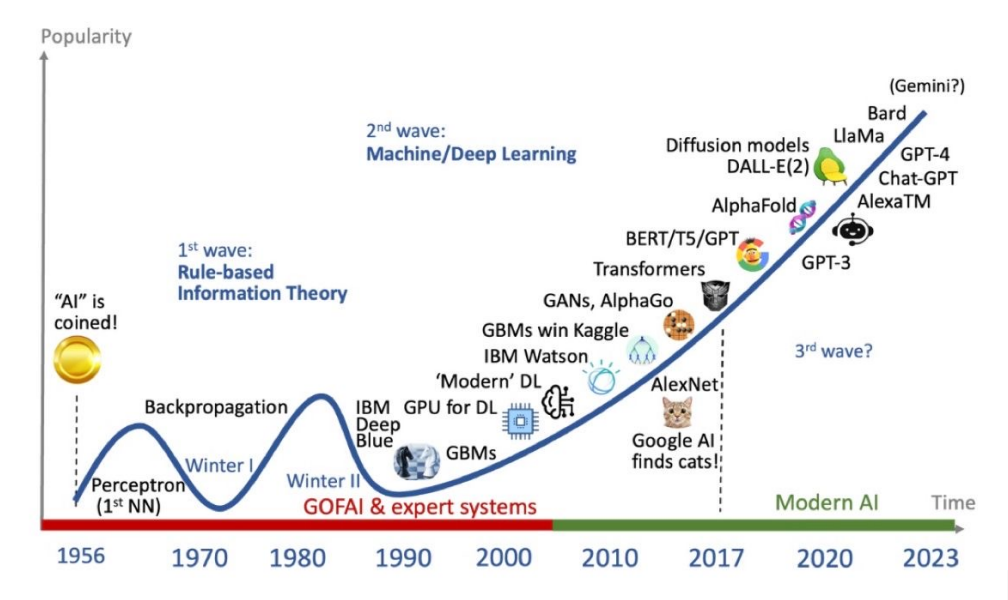
接下来,我们将时间轴拉开,可以在这张图中看到人工智能发展过程中每一个技术出现的时间点。我刚才有讲到一些,大家有没有注意到2017年就开始出现了Transformer,所以并不是今天有了ChatGPT才有了Transformer。也就是说,它已经发展了五六年,才最终从理论变成了我们今天可以使用的应用。
而刚才讲到的大模型,或者说基于大模型基于的基础模型最厉害的地方在于它的迁移学习能力,但是迁移学习能力最关键的来自于人工智能发展的三个要素:数据、算法和算力。这三个要素就像一个三角形,它们互相制约、互相支持,共同发展。
以数据为例,很多年前,当我们谈到数据时,大家通常想到的是数据库,里面存放个表。即使你不从事IT行业,每天使用 Excel 表格也是在使用数据。后来,我们发现除了数据库或者 Excel 表格之外的其他东西也可以被视为数据。比如说,你提供给我一个文件,员工手册或产品说明书,这些PDF文件也可以被视为数据。我现在说话的语音也是数据,大家拍照的面部特征也是数据。我们将这些数据汇总到一起,就可以形成一个数据湖。从数据库到数据仓库再到数据湖,业界的发展趋势是慢慢的海纳百川,逐渐涵盖一切类型的数据。
那这些数据一定有方法去处理它,这就是我们要讲到的算法。算法的发展也十分有趣。早期,我们使用数学的方式来教计算机如何处理数据。例如,我们用数学告诉计算机什么是加法,一加一等于二就是加法。我们以前使用的所有算法,无论是最简单的归纳总结还是最复杂的预测,其实都是有数学理论作为基础支撑的。一定是数学家先提出数学公式,然后我们计算机工程师才能写出算法。因此,实际上整个行业在过去30年是数学引领了计算机的发展。
大约从2010年开始,情况已经不同了,因为计算机中出现了一些新的算法,这些算法是数学解释不了或无法解释的。由于深层神经网络的出现,就像我们人类一样,尽管我们的神经学或生物学再怎么发达,我们仍然无法解释它们是如何运作的。现在的生成神经网络到底是如何运作的?一旦规模扩大,以我们人类目前的理解能力和数学建模能力,就很难提供一个清晰的解释。这也是为什么当2017年Transformer模型出现时,业界一开始并不了解它的潜力。
但大约在2019年和2020年,当Transformer模型的规模达到一定程度时,以GPT 3为代表,达到了千亿级别的参数量,GPT 3的参数级别大约在1700多亿。人们发现,你以为你知道这个Transformer模型的工作原理,但实际上你不知道,你发现它好像可以推理,好像能做许多你没有教过它的事情。从这个时候开始,人们慢慢发现数学不再那么容易解释了。如果再过十年、二十年,我不知道未来的世界会是什么样子,但当我们回顾2020年到2023年时,人们会发现这是一个分水岭,人工智能、科学、数学这样一个分水岭。
但是有了这么奇妙的算法,你需要有地方能够计算它,对不对?《三体》里面讲过,我们最早的可以用人来代替计算机里面的计算单元,用人来代替晶体管好像也能干完一些事情,但是对于像神经网络算法,就不能再用简单的晶体管来计算了。
在这种情况下,提高算力必须通过提高三角形中的“数据”和”算法”。GPU以前我们主要用来做游戏,对不对?后来发现算法特别是神经网络算法,它不像CPU那样依赖于执行,我们可以把一张图切成几千个、几万个,然后让每个处理器独立处理,这样会更快。当GPU有几十个核时,CPU可能只有两个或四个核。这就是为什么在20世纪90年代和本世纪初,越来越多的人开始使用GPU。除了GPU之外,现在还有一些专用芯片,专门用于人工智能,它不需要干其他事情,只需要处理人工智能。这是特殊芯片的算力的发展。
随着云计算、边缘计算等技术的发展,有时候是数据跑得多快一点,有时候是算法跑得快一点,但这个三角形中的三个要素永远都在相互发展。
今天我主要分享的是中间的一环算法,特别是其中的Transformer。
OpenAI的脱颖而出
GPT中的T其实就是Transformer,是ChatGPT把它带火的。ChatGPT可以在两个月把用户量突破到1亿,基本上已经没有其他的应用能够跟它比肩的了。
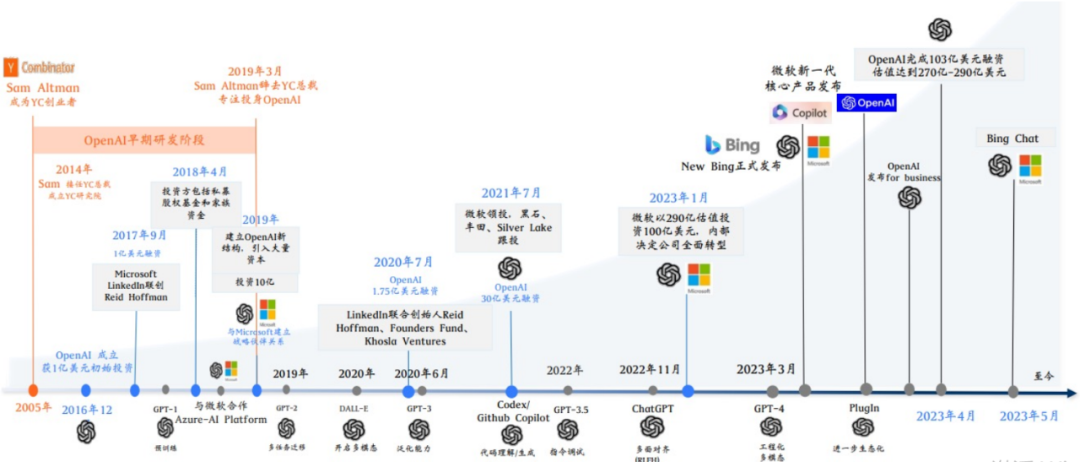
让我们来看看开发ChatGPT背后的公司OpenAI,其中比较重要的时间点是它的成立,包括被微软投资。实际上它并不是唯一一家,也不是第一家做大模型的公司。同时,还有其他几家公司在这个领域有影响力的包括谷歌、Facebook(现在叫Meta)等公司都在做大模型。
你们可能会好奇为什么OpenAI会脱颖而出。我个人的看法是,首先,他们的工程化让大模型往前迈进了很大很大的一步。什么是工程化模型?你可以把这个模型看成是一个天赋异禀的小孩子,他可能一出生就有180的智商,你让他学什么,他就学什么。这个过程就像是在公开教育这个小孩子,但是如果你教得慢,他在9岁时可能就被其他人甩在了后面。虽然他天赋异禀,但如果教得不好,他的思维年龄可能现在还停留在6岁或7岁,这样一来就会落后了。也许大家最初的思路都是基于同一份论文,就是谁家教的好的问题,也是工程化做得好的问题。
传统机器学习的套路
在讲Transformer之前,我想先介绍一下机器学习是如何完成这些工作的,以及如何将一个算法转化为可用的。大家千万不要认为机器学习听起来很高端,实际上它很简单。
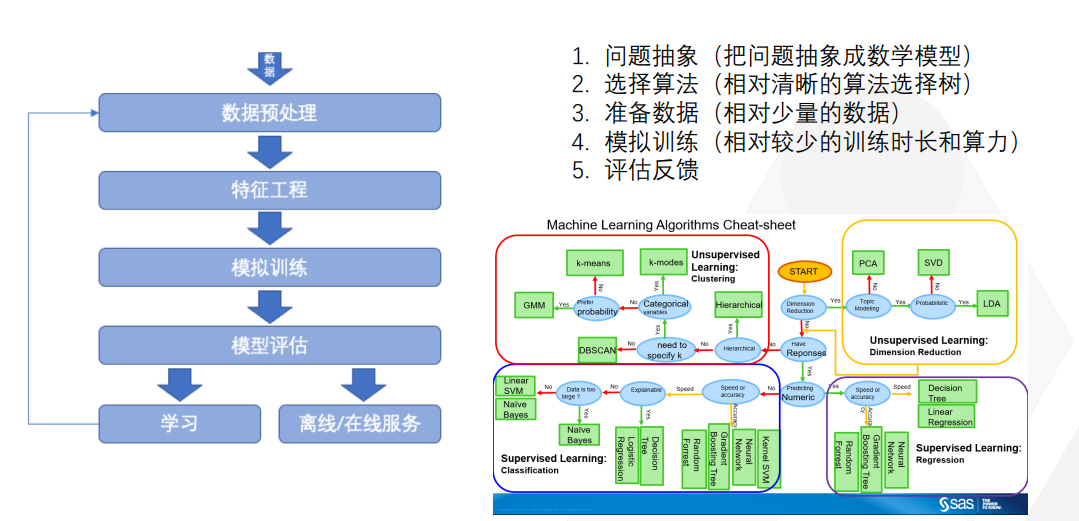
首先,你需要提出你的问题,比如说我要预测股票的价格从哪个期货市场赚钱,这就是我的问题。将其抽象成一个数学模型,比如说我使用数学中的归纳算法模型,如果我能够归纳得足够丰富、足够准确,我就能够猜出明天的股票价格。
第一步是问题抽象,第二步是选择算法。算法有很多种,选出来之后,你需要准备数据。爬下来所有交易所的数据,甚至是一级、二级市场的数据。传统机器学习用相对于较少的数据,来推断未来的规律。使用相对较少的训练时长和算力来对模型进行训练。模型训练完成后需要进行评估和反馈。慢慢地让模型越来越趋向真实,就像你画一幅画一样。这是传统机器学习的套路,但Transformer模型并不是这样的,大家会发现中间有很多可以学习的新名词和方法。
理解Transformer算法相关的概念
GPT的“G” 指的是生成式,“P”指的是预训练。因此,它被称为生成式预训练transformer。首先需要预训练这个transformer模型,这个训练需要专门的语料库,需要人工进行标记的语料库。此外,还需要人工反馈。例如,您向 GPT 提出一个问题,它给出两个答案,然后需要人工去告诉它哪个答案更好,这样它就会在下一次回答时会表现得更好。这是一个正向反馈循环。
预训练是通过大规模、海量的通用文本,来让模型学到广泛的通用知识和上下文的理解。具体是什么意思?如果我现在让 ChatGPT 写一篇文章,它可以写,我让它写古诗,它也可以写。但它真的能读懂古诗吗?或者,如果我让它写文案,它真的懂法律条文吗?实际上,它不理解这些,它只知道每个字出现的概率。
我们经常听到在大模型里面,某某公司很厉害,基于一个模型做了微调。
微调是什么意思呢?原本这个模型是个通用模型,可以做任何事情。然而,当你问它一些特定的问题时,它可能不懂。例如,如果我问它中国的古诗词,它可能不懂。但是,如果我提供大量的中国古诗词进行微调,它就能更好地理解中国古诗词,知道当你要写七言古诗时,需要规律是什么,押韵是什么样子的。这就是微调。
因此,微调实际上是迁移学习的理念,将通用学习微调到能够迁移支持另一个领域,让其理解,包括语言的微调,例如理解中文之后,它几乎也可以理解日语,理解英语,也可以理解法语。如果加入中英文对照的语料进行微调后,它也可以理解中文。
但是放心,我们今天的大模型,至少到目前为止,这个Transformer模型并没有真正的理解能力,没有科幻小说中的自主决策能力。我今天揭开AI大模型的面纱,让大家知道这一点:大模型没有真正的理解能力,它只判断出现的概率。
最后一个概念是参数。我们之前提到了千亿参数,几十亿参数。我今天所说的每句话、每个字后面都是在一个庞大的向量网络来支撑。比如“我是谁”,这个“我”字后面有一个庞大的向量宇宙来支撑它。向量怎么理解呢?可以想象一下多维宇宙。我们所处的宇宙是三维的,加上时间维度可能是四维的,还可以有其他维度。在数学中,我们可能会有一个多维的数学网宇宙,不用管它是什么,只需要知道可能有很多维度。
所以,如果我把一篇金庸小说输入到模型中,它会经常发现中间有些字词是相关联的,比如说,“九”字后面经常会跟着“阳”或者“阴”,“九阳正经”、“九阴真经”,那么“九”字的向量数据库里面,向量网络里面就一定有“阳”或者“阴”出现。这两个字老是出现在一起,对不对?这是金庸小说中的常见模式。所以当我询问金庸小说里面哪个武功最强时,如果我给出“九”这个提示,模型就会立刻判断。从概率角度来看,你肯定想我回答“九阳”或“九阴”,这个概率最大,不会回答其他的东西,比如“九九艳阳天”之类的,对吧?这就是一个概率问题。所以,向量代表的就是这个字与其他字发生关系的概率有多大。
因此,你可以设想,如果我的向量网络的维度越多,那么我的向量就越复杂。这是否意味着,我能够用这个向量网络来记录一个庞大的语料库,这个语料库可能比中国国家图书馆和大英国家图书馆的所有书加起来还要大,其中每个字与其他字发生关系的概率都能被记录下来。这样,当我需要回答“莎士比亚文体中哈姆雷特到底得罪了多少人”这类问题时,我就能从哈姆雷特的向量网络中轻松找到答案,这只是一个概率问题。通过这种方式,大家应该能够轻松理解参数所代表的是每个字与其他字发生关系的概率。有了这样的基础理解之后,我们就能轻松理解Transformer算法了。
Transformer算法架构的工作原理
这是一个最基本的 Transformer 结构图。不要以为它很复杂,用我刚才讲给大家的知识,一讲解大家就理解了。
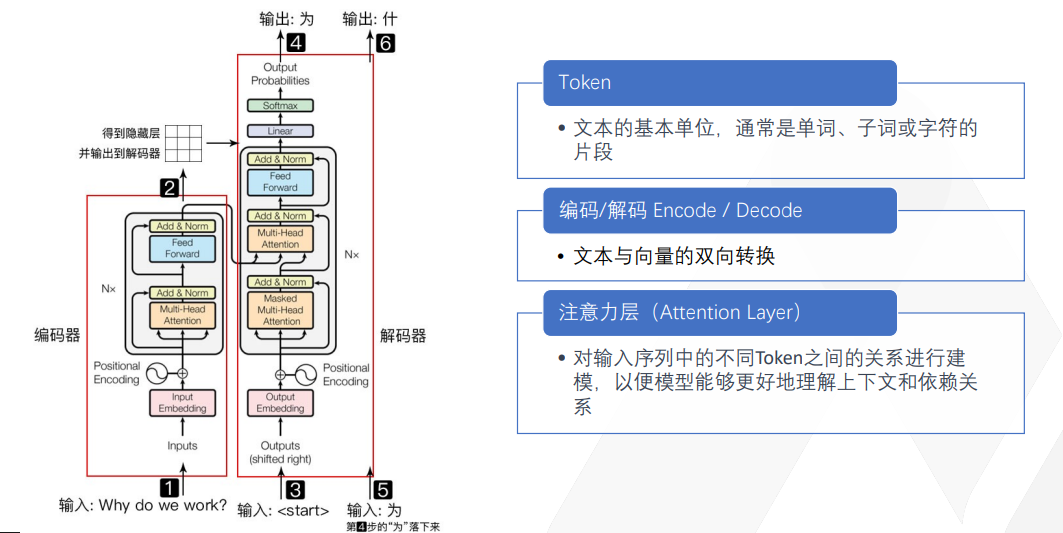
这里举的一个例子是让 GPT 帮我翻译英语到中文,将“why do we walk”翻译为“为什么我们要工作?”这是我们打工人的永恒问题。我的输入是一句英文输出,它得输出成中文。那我们来看看这个Transformer 算法怎么做?
首先,它把你的输入先拆成token。token在中文里好像不太好直接翻译,我就直接叫它 token。
在英语里,token 通常就是一个单词,其实在中文里面就是一个字。比如“我来自于哪里?”就可以拆成“我”一个 token,“来”一个 token,“自”一个 token,“于”一个 token,“哪”一个 token,“里”一个 token。英语有时候一个字还不止一个 token,因为英国人为了表达一个没见过的概念,有时候就把好多个英语单词组成一块。如果你们考过美国的托福、GRE 考试,就会见到那种特别长二三十个字母的英文单词。这种单词通常会进入到Transformer算法,然后把它切成好多个块,每个块代表了一个意思,每个块就是一个 token。所以英语经常会一个字是几个 token,而中文基本上一个字就是一个 token。
拆完之后,每一个 token 对应了一个向量的多维空间。就像我刚才举的例子,一个“我”字后面带一个向量空间,“九阳真经”这个“九”字后面又有一个向量空间,每个字都有一个向量空间。这个时候我告诉它说,你要帮我翻译,那它就会先来判断,说好,这里面出现了“为什么”?“why”是“为什么”?第一个字是“why”,它先输出个“why”,输出完“why”之后,它就在“why”的向量空间里去找。
我要表达这个 why 这个意思的话,最大概率的会是什么呢?是为什么?还是为何?还是为了?还是为什么?AI找到了“为什么”这个词出现的概率最大,因此毫不犹豫地输出了这个词。同样的道理,AI发现概率最大的第三个词肯定是“么”,于是也将其输出。
在与ChatGPT聊天时,它不会给你一个完整的句子,而是一个一个字地输出。它靠每个字去猜下一个字出现的最大几率,这是一个基于多维向量空间的算法,不是很复杂。
有时候,我们中国人很好奇,AI算法能否区分“南京市长江大桥nán jīng shì cháng jiāng dà qiáo”和“南京市长,江大桥nán jīng shì zhǎng jiāng dà qiáo”的区别。你认为Transformer算法能否区分呢?这是一个非常有趣的问题。
在使用传统的生成神经网络时,微软的一个研究院专门研究如何断句,因为中文断句是一个很大的问题。我们需要编写算法来判断是将断点放在“长江大桥”前面还是藏在“zhǎng”的后面。
然而自从出现了Transformer算法,我们发现对于Transformer算法来说,断句并不重要,它只关注每个字的向量空间。因此,在南京市这个例子中,后面出现的大概率是“长江大桥”,而不是“市长江大桥”。由于“江大桥”出现在“市长”的字后面的概率微乎其微,因此它不太可能被选中。因此,Transformer算法绝对不会将“南京市长江大桥”断成“南京市长”。
在过去,我们担心如何断句,如何理解中文的语义和语法,以及如何理解日语和韩语中的语法等问题。这些问题都是以前使用神经网络时需要解决的问题。但现在,这些问题都不再是问题,许多从事神经网络工作的人可能需要转换方向,转向Transformer算法方向,因为在这个领域,这些都不是问题。
接下来是Attention Layer注意力层,用于操作处理每个字背后的多维向量空间。这一层被称为自注意力层,指的是它只关注这个字本身的向量,而无需关注其他内容,如语法、语言和断句等。因此,我们可以让算法自行发挥向量空间算法的优势。
好,现在你们应该理解为什么它可以写诗,为什么它可以回答问题了。
Transformer的独特之处
传统的深度学习方法不能做的事情,为什么只有Transformer 才能做到?
为了解答这个问题,我们先思考一下传统的神经网络是用来干什么的。我们通常用它来进行自动驾驶视频识别和图片识别,为什么呢?因为我们可以将一张图片轻松地拆成小块,每个小块都可以单独处理,不需要依赖其他的块,也不需要识别这个小块和其他小块之间有多少关联。如果说没有关联也不完全正确,是有关联的,比如你将前面一辆车的车牌号码切成许多小块,必须将它们连起来才能读出完整的车牌号码,因此它们之间是有关联性的。
但是相比于文字,这种关联性并不那么复杂,因此传统的深度学习模型只需要挖几层就挖到底了,不需要挖很多层,也不需要进行复杂的并行处理,只需要将图片分割成小块,进行简单的单线条处理即可。但是对于文本来说,传统的深度学习模型就不行了。
在处理文本时,我们发现在一句话中,每个单词放在前面或后面都有完全不同的意思,这在中文中尤其明显。中文中有各种各样的梗,比如谐音梗、词语顺序梗等,因此传统的深度学习模型就蒙了,无法断句,无法处理顺序。它需要将整句话的上下文连起来才能理解意思,因此它无法处理。
而 Transformer 的独特之处在于其attention 机制(注意力机制),它只关注概率,不关注断句或顺序,只关注下一个字与当前字之间的关系。因此 Transformer 实际上是一种归纳总结的算法,它是一种预测算法,用于预测下一个词或下一个字出现的概率。而且在处理完后,它解决了并发性问题,因为每个字只关注自己的向量空间和下一个字的向量空间。因此即使你给我一篇文章,我也可以将其拆分成多个小块进行并行计算,只要我的计算机足够强大,我就能够在一秒钟内理解整篇文章并回答任何问题。Transformer解决了分布式语言处理的问题,真正可以并行处理整篇文章。无论是整本小说还是整个图书馆,只要你的计算能力足够强,Transformer就能处理。
GPT的局限性
GPT 的演进历程经历了很长时间,从最初的 1.0 版本发展到现在的 3.5版本、4.0 版本,参数量越来越多。
在这么多年的发展历程中,GPT 的主要转折点在 GPT 3 上。因为在应用Transformer算法之前,人们无法看出它的潜力。正如之前提到的,OpenAI 跑出了赛道,因为他是第一家将具有智商 180 的天赋异禀的孩子训练到了 1000 亿级参数的 GPT 3,这是第一家做到的。因此,GPT 3 比其他人更快地达到了临界点和爆发点,而其他人仍在训练 GPT 2 级别的模型,仍在使用数十亿级别的参数进行训练。
GPT 3通过微调和迁移学习来利用少量的样本进行学习。
GPT 4 已经在 OpenAI 上开始应用了,但目前仅限于付费用户使用,因为 OpenAI 是一个闭源的平台,它不公开使用了多少参数。但是大家基本上可以猜测,大概 GPT 3.5 的参数量达到了 1700 多亿。GPT-4 在 3. 5 基础上,规模扩大了 100 倍,应该是达到了万亿级别、十万亿级别的参数量。因此,它的能力非常强大,可以帮助你撰写文章、进行新闻分析,甚至编写 Python 代码等等。
然而 GPT本身仍然存在缺陷和局限性。

大家看这张图片是我随意测试的结果。我测试了李白是否写过一首古诗来赞美“郑和下西洋”,而它很聪明地判断出“郑和下西洋”属于明代,而李白是唐代的诗人。但是,当我再次欺骗它时,问它李白是否写过一首有关“大禹治水”的诗,它就上当了,它真的写了一首像模像样的大禹治水的诗。
尽管GPT已经发展到3.5和4,看起来非常聪明,但它仍然有其局限性,即它没有真正的理解能力和知识能力。真正的知识能力是指真正的推理判断能力。作为人类个体,我们的强大之处在于我们自己的判断力。没有判断力,我们就只是一个计算机。GPT似乎什么都懂,但它没有判断力,因此会产生幻觉,它不太可靠,会有一些推理偏见和错误。因此,在使用GPT时,需要注意它的局限性。
或许在将来,我们可以在所有的概率判断之前先加一层推理逻辑判断,这样它可能会变得更好,但这个算法会更加复杂和麻烦。你必须首先让它具备推理能力,而以前我们的生成神经网络做的就是推理学,而现在的Transformer则是做简单的概率预测。这两个东西存在一些差别,你需要让它先做推理,再做预测。
我今天的分享就到这里,谢谢大家。