
通过这三个文件彻底搞懂rocketmq的存储原理
RocketMQ是阿里开发的一个高性能的消息队列,支持各种消息类型,而且支持事务消息,可以说是现在的很多系统中的香饽饽了,所以呢,怎么使用大家肯定是要学习的
我们作为一个有梦想的程序员,在学习一门技术的时候,肯定是不能光知其然,这是远远不够的,我们必须要知其所以然,这样才能在面试的时候侃侃而谈,啊呸,不对,这样我们才能在工作中遇到问题的时候,理性的去思考如何解决问题
我们知道RocketMQ的架构是producer、NameServer、broker、Consumer,producer是生产消息的,NameServer是路由中心,负责服务的注册发现以及路由管理这些。
Consumer是属于消费消息的,broker则属于真正的存储消息,以及进行消息的持久化,也就是存储消息的文件和索引消息的文件都在broker上
消息队列的主要作用是解耦异步削峰,也就意味着消息队列中的存储功能是必不可少的,而随着时代的发展,业务量的增加也对消息队列的存储功能的强度的要求越来越高了
也就是说你不能光性能好,你得存储的消息也得足够支撑我的业务量,你只能存储100MB的消息,我这系统每分钟的消息业务量可能500MB了,那肯定不够使啊,那还削个啥的峰啊,峰来了你自己都顶不住

RocketMQ凭借其强大的存储能力和强大的消息索引能力,以及各种类型消息和消息的特性脱颖而出,于是乎,我们这些有梦想的程序员学习RocketMQ的存储原理也变得尤为重要
而要说起这个存储原理,则不得不说的就是RocketMQ的消息存储文件commitLog文件,消费方则是凭借着巧妙的设计Consumerqueue文件来进行高性能并且不混乱的消费,还有RocketMQ的强大的支持消息索引的特性,靠的就是indexfile索引文件
我们这篇文章就从这commitLog、Consumerqueue、indexfile这三个神秘的文件说起,搞懂这三个文件,RocketMQ的核心就被你掏空了
先上个图,写入commitLog文件时commitLog和Consumerqueue、indexfile文件三者的关系

Commitlog文件
大小和命名规则
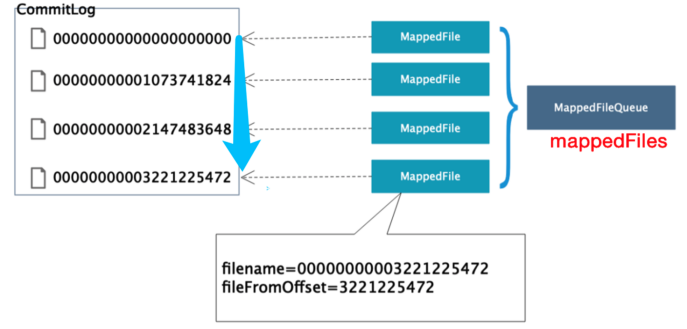
文件存储规则和特点

简单看下源码
public PutMessageResult putMessage(MessageExtBrokerInner msg) {if (this.shutdown) {log.warn("message store has shutdown, so putMessage is forbidden");return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);}// 从节点不允许写入if (BrokerRole.SLAVE == this.messageStoreConfig.getBrokerRole()) {long value = this.printTimes.getAndIncrement();if ((value % 50000) == 0) {log.warn("message store is slave mode, so putMessage is forbidden ");}return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);}// store是否允许写入if (!this.runningFlags.isWriteable()) {long value = this.printTimes.getAndIncrement();if ((value % 50000) == 0) {log.warn("message store is not writeable, so putMessage is forbidden " + this.runningFlags.getFlagBits());}return new PutMessageResult(PutMessageStatus.SERVICE_NOT_AVAILABLE, null);} else {this.printTimes.set(0);}// topic过长if (msg.getTopic().length() > Byte.MAX_VALUE) {log.warn("putMessage message topic length too long " + msg.getTopic().length());return new PutMessageResult(PutMessageStatus.MESSAGE_ILLEGAL, null);}// 消息附加属性过长if (msg.getPropertiesString() != null && msg.getPropertiesString().length() > Short.MAX_VALUE) {log.warn("putMessage message properties length too long " + msg.getPropertiesString().length());return new PutMessageResult(PutMessageStatus.PROPERTIES_SIZE_EXCEEDED, null);}if (this.isOSPageCacheBusy()) {return new PutMessageResult(PutMessageStatus.OS_PAGECACHE_BUSY, null);}long beginTime = this.getSystemClock().now();// 添加消息到commitLogPutMessageResult result = this.commitLog.putMessage(msg);long eclipseTime = this.getSystemClock().now() - beginTime;if (eclipseTime > 500) {log.warn("putMessage not in lock eclipse time(ms)={}, bodyLength={}", eclipseTime, msg.getBody().length);}this.storeStatsService.setPutMessageEntireTimeMax(eclipseTime);if (null == result || !result.isOk()) {this.storeStatsService.getPutMessageFailedTimes().incrementAndGet();}return result;}
consumerQueue文件
存放位置和结构
ConsumeQueue的作用
offsetTable.offset
简单看下构建过程
public void run() {while (!this.isStopped()) {try {Thread.sleep(1);this.doReput(); // 构建ComsumerQueue} catch (Exception e) {DefaultMessageStore.log.warn(this.getServiceName() + " service has exception. ", e);}}}
private void doReput() {for (boolean doNext = true; this.isCommitLogAvailable() && doNext; ) {SelectMappedBufferResult result = DefaultMessageStore.this.commitLog.getData(reputFromOffset);// 拿到所有的最新写入CommitLog的数据if (result != null) {try {this.reputFromOffset = result.getStartOffset();for (int readSize = 0; readSize < result.getSize() && doNext; ) {DispatchRequest dispatchRequest =DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false); // 一条一条的读消息int size = dispatchRequest.getMsgSize();if (dispatchRequest.isSuccess()) {if (size > 0) {DefaultMessageStore.this.doDispatch(dispatchRequest); // 派发消息,进行处理,其中就包括构建ComsumerQueuethis.reputFromOffset += size;readSize += size;} else if (size == 0) { //this.reputFromOffset = DefaultMessageStore.this.commitLog.rollNextFile(this.reputFromOffset);readSize = result.getSize();}} else if (!dispatchRequest.isSuccess()) { // 获取消息异常if (size > 0) {log.error("[BUG]read total count not equals msg total size. reputFromOffset={}", reputFromOffset);this.reputFromOffset += size;} else {doNext = false;if (DefaultMessageStore.this.brokerConfig.getBrokerId() == MixAll.MASTER_ID) {this.reputFromOffset += result.getSize() - readSize;}}}}} finally {result.release();}} else {doNext = false;}}}
indexFile文件
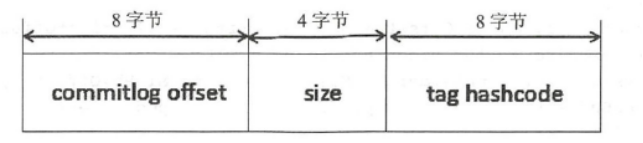
文件结构

文件详细信息
//8位 该索引文件的第一个消息(Message)的存储时间(落盘时间)this.byteBuffer.putLong(beginTimestampIndex, this.beginTimestamp.get());//8位 该索引文件的最后一个消息(Message)的存储时间(落盘时间)this.byteBuffer.putLong(endTimestampIndex, this.endTimestamp.get());//8位 该索引文件第一个消息(Message)的在CommitLog(消息存储文件)的物理位置偏移量(可以通过该物理偏移直接获取到该消息)this.byteBuffer.putLong(beginPhyoffsetIndex, this.beginPhyOffset.get());//8位 该索引文件最后一个消息(Message)的在CommitLog(消息存储文件)的物理位置偏移量this.byteBuffer.putLong(endPhyoffsetIndex, this.endPhyOffset.get());//4位 该索引文件目前的hash slot的个数this.byteBuffer.putInt(hashSlotcountIndex, this.hashSlotCount.get());//4位 索引文件目前的索引个数this.byteBuffer.putInt(indexCountIndex, this.indexCount.get());
//slot的数据存放位置 40 + keyHash %(500W)* 4int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;//Slot Table//4字节//记录该slot当前index,如果hash冲突(即absSlotPos一致)作为下一次该slot新增的前置indexthis.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
//Index Linked list//topic+message key的hash值this.mappedByteBuffer.putInt(absIndexPos, keyHash);//消息在CommitLog的物理文件地址, 可以直接查询到该消息(索引的核心机制)this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);//消息的落盘时间与header里的beginTimestamp的差值(为了节省存储空间,如果直接存message的落盘时间就得8bytes)this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);//9、记录该slot上一个index//hash冲突处理的关键之处, 相同hash值上一个消息索引的index(如果当前消息索引是该hash值的第一个索引,则prevIndex=0, 也是消息索引查找时的停止条件),每个slot位置的第一个消息的prevIndex就是0的this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
再论结构

查询流程
公式1:第n个slot在indexFile中的起始位置是这样:40+(n-1)*4 公式2:第s个index在indexFile中的起始位置是这样:40+5000000*4+(s-1)*20
包括当前机器IP+进程号+MessageClientIDSetter.class.getClassLoader()的hashCode值+消息生产时间与broker启动时间的差值+broker启动后从0开始单调自增的int值,前面三项很明显可能重复,后面两项一个是时间差,一个是重启归零,也可能重复
简单看下源码,感兴趣的下载源码去研究
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {//1. 判断该索引文件的索引数小于最大的索引数,如果>=最大索引数,IndexService就会尝试新建一个索引文件if (this.indexHeader.getIndexCount() < this.indexNum) {//2. 计算该message key的hash值int keyHash = indexKeyHashMethod(key);//3. 根据message key的hash值散列到某个hash slot里int slotPos = keyHash % this.hashSlotNum;//4. 计算得到该hash slot的实际文件位置Positionint absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;try {//5. 根据该hash slot的实际文件位置absSlotPos得到slot里的值//这里有两种情况://1). slot=0, 当前message的key是该hash值第一个消息索引//2). slot>0, 该key hash值上一个消息索引的位置int slotValue = this.mappedByteBuffer.getInt(absSlotPos);//6. 数据校验及修正if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {slotValue = invalidIndex;}long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();timeDiff = timeDiff / 1000;if (this.indexHeader.getBeginTimestamp() <= 0) {timeDiff = 0;} else if (timeDiff > Integer.MAX_VALUE) {timeDiff = Integer.MAX_VALUE;} else if (timeDiff < 0) {timeDiff = 0;}//7. 计算当前消息索引具体的存储位置(Append模式)int absIndexPos =IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize+ this.indexHeader.getIndexCount() * indexSize;//8. 存入该消息索引this.mappedByteBuffer.putInt(absIndexPos, keyHash);this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);//9. 关键之处:在该key hash slot处存入当前消息索引的位置,下次通过该key进行搜索时//会找到该key hash slot -> slot value -> curIndex ->//if(curIndex.prevIndex>0) pre index (一直循环 直至该curIndex.prevIndex==0就停止)this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());if (this.indexHeader.getIndexCount() <= 1) {this.indexHeader.setBeginPhyOffset(phyOffset);this.indexHeader.setBeginTimestamp(storeTimestamp);}this.indexHeader.incHashSlotCount();this.indexHeader.incIndexCount();this.indexHeader.setEndPhyOffset(phyOffset);this.indexHeader.setEndTimestamp(storeTimestamp);return true;} catch (Exception e) {log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);}} else {log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()+ "; index max num = " + this.indexNum);}return false;}
public void selectPhyOffset(final ListphyOffsets, final String key, final int maxNum, final long begin, final long end, boolean lock) {if (this.mappedFile.hold()) {//1. 计算该key的hashint keyHash = indexKeyHashMethod(key);//2. 计算该hash value 对应的hash slot位置int slotPos = keyHash % this.hashSlotNum;//3. 计算该hash value 对应的hash slot物理文件位置int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;FileLock fileLock = null;try {//4. 取出该hash slot 的值int slotValue = this.mappedByteBuffer.getInt(absSlotPos);//5. 该slot value <= 0 就代表没有该key对应的消息索引,直接结束搜索// 该slot value > maxIndexCount 就代表该key对应的消息索引超过最大限制,数据有误,直接结束搜索if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()|| this.indexHeader.getIndexCount() <= 1) {} else {//6. 从当前slot value 开始搜索for (int nextIndexToRead = slotValue; ; ) {if (phyOffsets.size() >= maxNum) {break;}//7. 找到当前slot value(也就是index count)物理文件位置int absIndexPos =IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize+ nextIndexToRead * indexSize;//8. 读取消息索引数据int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);//9. 获取该消息索引的上一个消息索引index(可以看成链表的prev 指向上一个链节点的引用)int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);//10. 数据校验if (timeDiff < 0) {break;}timeDiff *= 1000L;long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;boolean timeMatched = (timeRead >= begin) && (timeRead <= end);//10. 数据校验比对 hash值和落盘时间if (keyHash == keyHashRead && timeMatched) {phyOffsets.add(phyOffsetRead);}//当prevIndex <= 0 或prevIndex > maxIndexCount 或prevIndexRead == nextIndexToRead 或 timeRead < begin 停止搜索if (prevIndexRead <= invalidIndex|| prevIndexRead > this.indexHeader.getIndexCount()|| prevIndexRead == nextIndexToRead || timeRead < begin) {break;}nextIndexToRead = prevIndexRead;}}} catch (Exception e) {log.error("selectPhyOffset exception ", e);} finally {this.mappedFile.release();}}}
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️