
如何使用HiveSQL进行OLAP分析
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

在线分析处理(OLAP,Online Analytical Processing)是通过带层次的维度和跨维度进行多维分析的,简单理解为一种多维数据分析的方式,通过OLAP可以展示数据仓库中数据的多维逻辑视图。在多维分析中,数据是按照维度(观察数据的角度)来表示的,比如商品、城市、客户。而维通常按层次(层次维度)组织的,如城市、省、国家,再比如时间也是有层次的,如天、周、月、季度和年。不同的管理者可以从不同的维度(视角)去观察这些数据,这些在多个不同维度上对数据进行综合考察的手段就是通常所说的数据仓库多维查询,最常见的就如上卷(roll-up)和下钻(drill-down)了,所谓上卷,指的是选定特定的数据范围之后,对其进行汇总统计以获取更高层次的信息。所谓下钻,指的是选定特定的数据范围之后,需要进一步查看细节的数据。从另一种意义上说,钻取就是针对多维展现的数据,进一步探究其内部的组成和来源。值得注意的是,上卷和下钻要求维度具有层级结构,即数仓中所说的层次维度。
如何实现数据的多维分析
Hive提供了多维数据分析的函数,如GROUPING SETS,GROUPING_ID,CUBE,ROLLUP,通过这些分析函数,可以轻而易举的实现多维数据分析。下面将会通过一个案例来了解这些函数的具体含义以及该如何使用这些函数。注意:在hive中使用这些函数之前,要确保开启了map端聚合,即set hive.map.aggr=true,否则会报如下错误:

简单介绍
GROUPING SETS
在一个group by查询中,通过该子句可以对不同维度或同一维度的不同层次进行聚合,简单理解为一条sql可以实现多种不同的分组规则,用户可以在该函数中传入自己定义的多种分组字段,本质上等价于多个group by语句进行UNION,对于GROUPING SETS子句中的空白集'()'表示对总体进行聚集。
示例模板
-- 使用GROUPING SETS查询
SELECT a,
b,
SUM(c)
FROM tab1
GROUP BY a,b
GROUPING SETS ((a,b), a,b, ());
-- 与GROUP BY等价关系
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b
UNION
SELECT a, null, SUM( c ) FROM tab1 GROUP BY a, null
UNION
SELECT null, b, SUM( c ) FROM tab1 GROUP BY null, b
UNION
SELECT null, null, SUM( c ) FROM tab1;
GROUPING__ID
当使用聚合时,有时候会出现数据本身为null值,很难区分究竟是数据列本身为null值还是聚合数据行为null,即无法区分查询结果中的null值是属于列本身的还是聚合的结果行,因此需要一种方法识别出列中的null值。grouping_id 函数就是此场景下的解决方案。注意该函数是有两个下划线。这个函数为每种聚合数据行生成唯一的组id。它的返回值看起来像整型数值,其实是字符串类型,这个值使用了位图策略(bitvector,位向量),即它的二进制形式中的每一位表示对应列是否参与分组,如果某一列参与了分组,对应位就被置为1,否则为0。通过这种方式可以区分出数据本身中的null值。看到这是不是还是一头雾水,没关系,来看下面的示例:
-- 创建表
create table test_grouping__id(id int,amount decimal(10,2));
-- 插入数据
insert into table test_grouping__id values(1,null),(1,1),(2,2),(3,3),(3,null),(4,5);
--执行查询
SELECT id,
amount,
grouping__id,
count(*) cnt
FROM test_grouping__id
GROUP BY id,
amount
GROUPING sets(id,(id,amount),())
ORDER BY grouping__id
查询结果分析
查询结果如下图所示:绿色框表示未进行分组,即进行全局聚合,grouping_id等于0,表示没有字段参与分组。蓝色框表示按照id进行分组,对应的grouping_id为1,表示只有一个字段参与了分组。橘色的框表示按照id和amount两个字段进行分组,grouping_id为3,即有两个字段参与了分组,转成十进制为2^0 + 2^1 = 3。
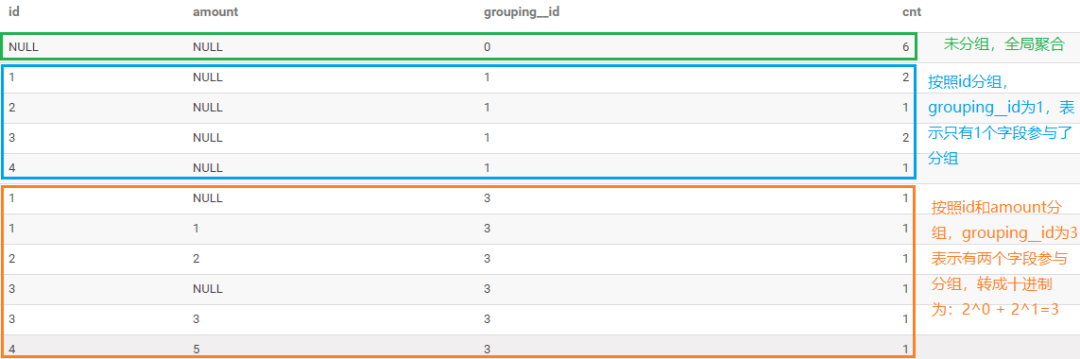
以上面为例,分组字段为id、amount,转成二进制表示形式为:

ROLLUP
通用的语法为WITH ROLLUP,需要与group by一起用于在维的层次结构级别上计算聚合。功能为可以按照group by的分组字段进行组合,计算出不同分组的结果。注意对于分组字段的组合会与最左边的字段为主。使用ROLLUP的GROUP BY a,b,c假定层次结构是“ a”向下钻取到“ b”,“ b”向下钻取到“ c”。则可以通过GROUP BY a,b,c,WITH ROLLUP进行实现,该语句等价于GROUP BY a,b,c GROUPING SETS((a,b,c),(a,b),(a),())。即使用WITH ROLLUP,首先会对全局聚合(不分组),然后会按GROUP BY字段组合,进行聚合,但是最左侧的分组字段必须参与分组,比如a字段是最左侧的字段,则a必定参与分组组合。
示例模板
-- 使用WITH ROLLUP查询
SELECT a,
b,
c
SUM(d)
FROM tab1
GROUP BY a,b,c
WITH ROLLUP
-- 等价于下面的方式
SELECT a,
b,
c,
SUM(d)
FROM tab1
GROUP BY a,b,c
GROUPING SETS ((a,b,c), (a,b), (a),());
CUBE
CUBE表示一个立方体,apache的kylin使用就是这种预计算方式。即会对给定的维度(分组字段)进行多种组合之后,形成不同分组规则的数据结果。一旦我们在一组维度上计算出CUBE,就可以得到这些维度上所有可能的聚合聚合结果。比如:GROUP BY a,b,c WITH CUBE,等价于GROUP BY a,b,c GROUPING SETS((a,b,c),(a,b),(b,c), (a,c),(a),(b),(c),())。
其实,可以将上面的情况抽象成排列组合的问题,即从分组字段集合(假设有n个字段)中随意取出0~n个字段,那么会有多少中组合方式,如下面公式所示:
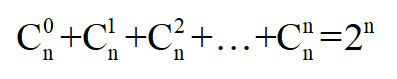
结合上面的例子,GROUP BY a,b,c WITH CUBE,那么所有的组合方式有:(a,b,c),(a,b),(b,c), (a,c),(a),(b),(c),(),一共有8种组合,即2^3 = 8。
示例模板
-- 使用WITH CUBE查询
SELECT a,
b,
c
SUM(d)
FROM tab1
GROUP BY a,b,c
WITH CUBE
-- 等价于下面的方式
SELECT a,
b,
c,
SUM(d)
FROM tab1
GROUP BY a,b,c
GROUPING SETS ((a,b,c),(a,b),(b,c), (a,c),(a),(b),(c),());
使用案例
数据准备
有一份用户行为数据集,包括用户的所有行为(包括pv点击、buy购买、cart加购、fav收藏),具体如下表所示:
| 字段名 | 列名称 | 说明 |
|---|---|---|
| user_id | 用户ID | 整数类型,用户ID |
| item_id | 商品ID | 整数类型,商品ID |
| category_id | 商品类目ID | 整数类型,商品所属类目ID |
| behavior | 行为类型 | 字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| access_time | 时间戳 | 行为发生的时间戳,单位秒 |
-- 创建表
CREATE TABLE user_behavior
(
user_id int ,
item_id int,
category_id int,
behavior string,
access_time string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
-- 装载数据
1,101,1,pv,1511658000
2,102,1,pv,1511658000
3,103,1,pv,1511658000
4,104,2,cart,1511659329
5,105,2,buy,1511659326
6,106,3,fav,1511659323
7,101,1,pv,1511658010
8,102,1,buy,1511658200
9,103,1,cart,1511658030
10,107,3,fav,1511659332
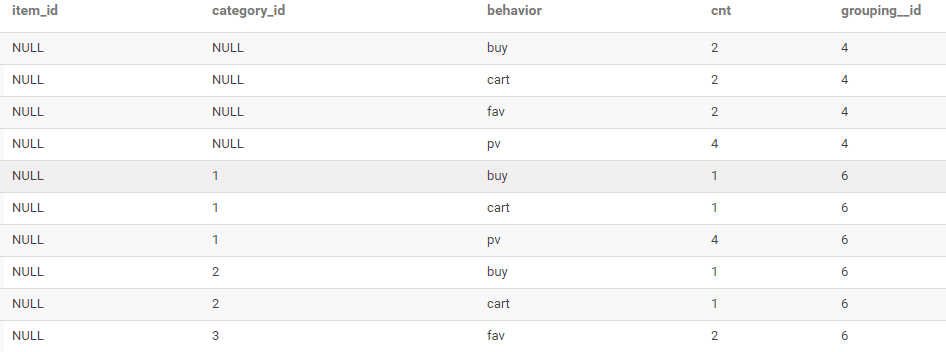
GROUPING SETS使用
-- 查询每种商品品类、每种用户行为的访问次数
-- 查询每种用户行为的访问次数
SELECT
item_id,
category_id,
behavior,
COUNT(*) AS cnt,
GROUPING__ID
FROM user_behavior
GROUP BY item_id,category_id,behavior
GROUPING SETS ((category_id,behavior),behavior)
ORDER BY GROUPING__ID;
结果如下:
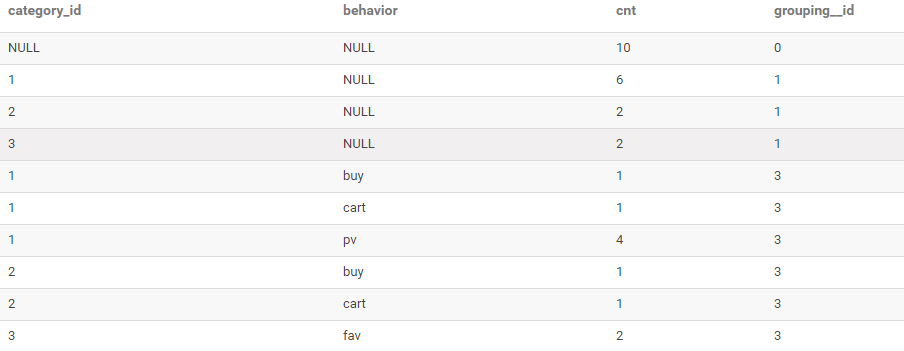
ROLLUP使用
-- 查询每种商品品类的访问次数
-- 查询每种商品品类、每种用户行为的次数
-- 查询用户的总访问次数
SELECT
category_id,
behavior,
COUNT(*) AS cnt,
GROUPING__ID
FROM user_behavior
GROUP BY category_id,behavior
WITH ROLLUP
ORDER BY GROUPING__ID;
结果如下:
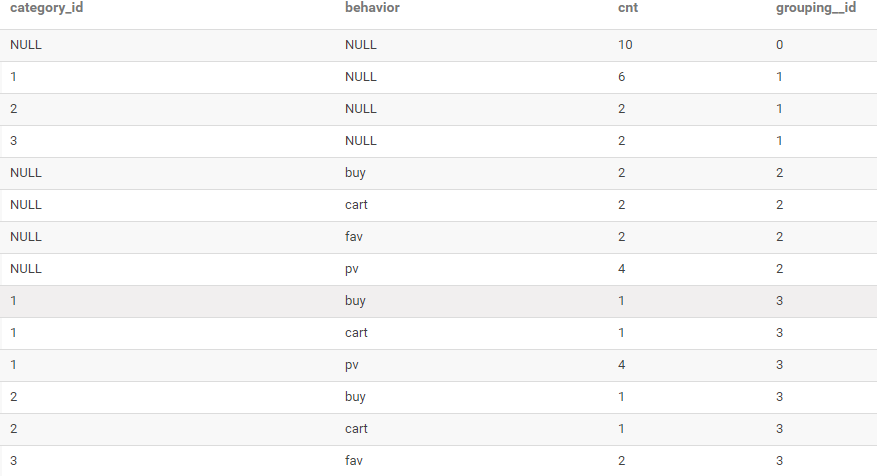
CUBE使用
-- 查询每种商品品类的访问次数
-- 查询每种用户行为的次数
-- 查询每种商品品类、每种用户行为的次数
-- 查询用户的总访问次数
SELECT
category_id,
behavior,
COUNT(*) AS cnt,
GROUPING__ID
FROM user_behavior
GROUP BY category_id,behavior
WITH CUBE
ORDER BY GROUPING__ID;
结果如下:
总结
本文首先介绍了什么是OLAP,接着介绍Hive中提供的几种OLAP分析的函数,并对每一种函数进行了详细说明,并给出了相关的图示解释,最后以一个案例说明了这几种函数的使用方式,可以进一步加深理解.