
ICRA2022 | OPV2V: 首个大型自动驾驶协同感知数据集+代码框架已开源

极市导读
本篇文章提出了首个大型自动驾驶协同感知数据集, 并提供了多达16个模型的综合Benchmark以及一套完整的代码框架,为协同感知这个新领域提供了基准。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

单位:UCLA Mobility Lab
论文链接:https://arxiv.org/pdf/2109.07644.pdf
代码链接:https://github.com/DerrickXuNu/OpenCOOD
项目主页:https://mobility-lab.seas.ucla.edu/opv2v/
1.研究动机
得幸于深度学习猛烈的发展,自动驾驶感知系统在近几年有了飞速的提升。尽管如此,单车的感知系统仍有其无法克服的困难。当自动驾驶汽车在遇到严重的遮挡或距离较远的物体时,往往不能有很好的表现。这种情况往往是由单车传感器在遮挡处或是远处信息太稀疏导致的,很难被算法克服。针对这种单车物理上的限制,工业界和学术界开始研究如何利用多车之间的视觉信息传递来彻底解决遮挡问题并增加感知视野。如图一所示,ego汽车(绿色框)正在一个T型的交叉口准备左转,此时正有两辆车向它这个方向快速驶来,但是由于停在路边的汽车,它的激光雷达根本无法感知到这两辆驶来的汽车(如图一中间所示),很可能会造成重大事故。但幸好此时有另外一辆自动驾驶汽车在另一侧经过(图一左被蓝色方框标出的CAV1),它能很好地捕捉到这两辆驶来汽车的信息(图一右所示),并且将该信息传递给ego, 从而避免车祸的发生。
由这个例子便可以看出协同感知能够极大提高自动驾驶在边缘场景的安全性,而本篇文章便提出了首个大型自动驾驶协同感知数据集, 并提供了多达16个模型的综合Benchmark以及一套完整的代码框架,为协同感知这个新领域提供基准。

2. 数据集介绍
本文提出的OPV2V数据集是首个大型公开的V2V协同感知仿真数据集,它主要由最流行的自动驾驶仿真器CARLA以及协同驾驶仿真框架OpenCDA联合收集,主要特点有:
该数据集共有73个不同的场景,每个场景在25s内并且有多辆自动驾驶汽车+趋近真实的交通流出现,在相同的时间戳下包含着多辆自动驾驶汽车的3D点云与相机RGB数据。 本数据集囊括了6种道路类型,9个不同的城市,其中8个是CARLA自带的城市,1个是根据洛杉矶Culver City接近百分百复原的数字城市与真实交通流(如图二所示)。 数据供含有1.2万张点云,4.8万张RGB图像,23万个标注好的3D检测框。 提供了一个包含4种不同点云检测Backbone, 4种不同多智能体信息融合策略,总共16个模型的综合benchmark。

3. Benchmark 介绍
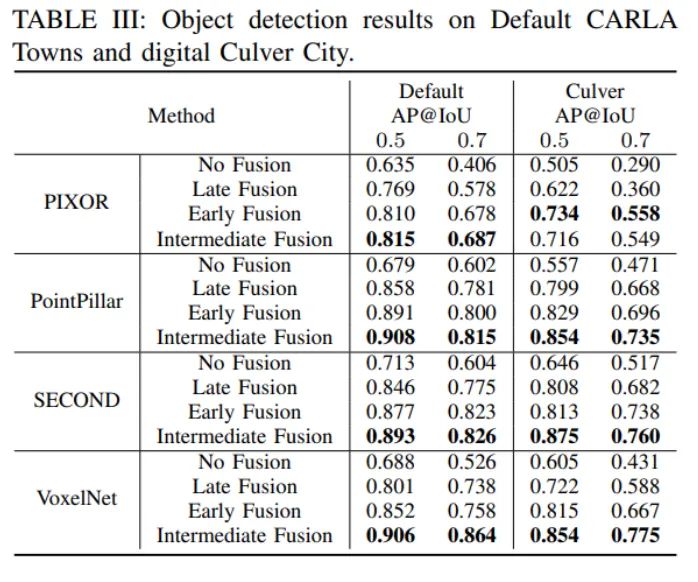
该数据集提供了4种不同点云检测backbone, 4种不同多智能体信息融合的策略。四个点云检测器包含:PointPillar, SECOND, VoxelNet和 Pixor。
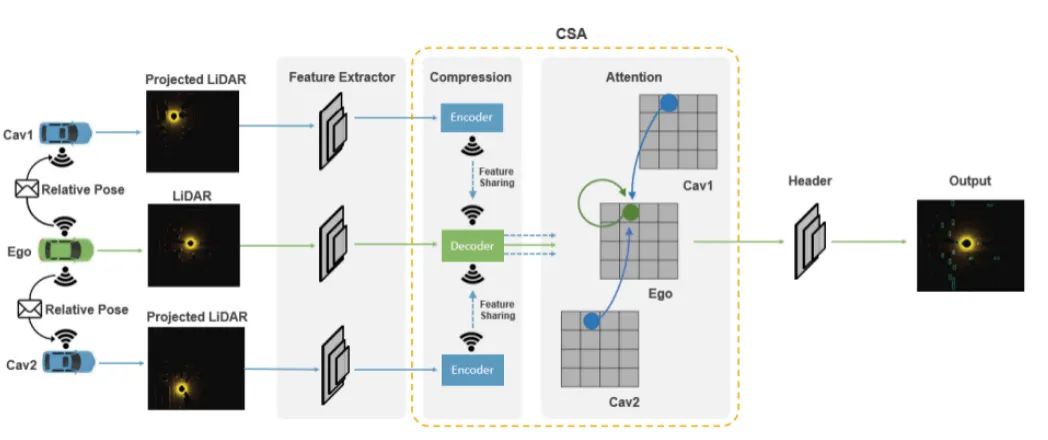
而四种融合方式有:1)单车无融合(基准线); 2)点云融合,即每辆汽车传送最原始的点云给对方; 3)结果融合(后融合),即每辆汽车单独检测,将自己的检测结果包括检测框位置与置信度传给其他汽车; 4)中间层融合,如下图所示,每辆汽车先将自己的点云投射到ego汽车的坐标系下,预处理点云后用3D点云网络提取深度学习特征,这些高维的特征经过压缩以后传到ego汽车上,然后使用注意力机制来进行点对点的多车空间维度上的融合,最后得到检测结果。该文章认为中间层融合是最优方案,因为点云融合要求带宽较高,速率较慢,结果融合并不能最大限度地结合信息,而中间层融合由于深度学习特征对压缩的鲁棒性,可以同时克服另外方案的缺点。
最终的结果如下图:
4. 代码框架介绍
该文章除了数据集与benchmark之外,还开源了首个协同感知代码框架 OpenCOOD (https://github.com/DerrickXuNu/OpenCOOD。该代码框架的主要特征有:
提供了一套简易易用地API,方便用户读取OPV2V数据并转化为相应的格式供pytorch模型直接使用。 提供了多个SOTA 3D点云检测模型代码,包括PointPillar, VoxelNet, Pixor, SECOND 支持多种常见地多智能体融合策略,包括后融合,前融合,中间层融合。 提供多种协同感知SOTA模型,包括Cooper, F-Cooper, Attentive Fusion (本文的中间层融合方法)等,并且作者承诺会持续更新所有市面上的最新算法 提供使用的log replay工具来回放OPV2V数据,并支持用户在不改变原数据的基础上增加新事件。 代码库还提供了详细的文档和tutorial, 方便用户更好理解。
公众号后台回复“开学”获取极市超全CV技术资源~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
