
Java8 HashMap优化、lambda、Stream等详解
共 10527字,需浏览 22分钟
·
2022-05-09 19:51
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
modb.pro
推荐:https://www.xttblog.com/?p=5342

目录
一、概述 二、优化底层数据结构 2.1、优化HashMap 三、Lambda表达式 3.1、概述 3.2、匿名内部类到lambda 3.3、lambda语法 3.4、函数式接口 3.5、方法引用 四、Stream 4.1、概述 4.2、创建Stream 4.3、中间操作 4.3.1、筛选与切片 4.3.2、映射map 4.3.3、排序sorted 4.4、终止操作 4.4.1、查找与匹配 4.4.2、规约 4.4.3、收集collect 4.5、并行流 4.5.1、Fork/Join框架 4.5.2、测试并行流 五、新时间API 5.1、Java.time 5.1、日期 5.2、时间 5.3、时间+日期 5.4、时间戳 5.5、字符串转日期格式化 5.6、时间推移 5.7、时间抽取 5.8、时区 5.9、Date与LocalDateTime互转 六、Optional容器类 七、接口中的默认方法与静态方法 八、重复注解与类型注解 8.1、重复注解 8.2、类型注解 8.3、@NonNull注解
一、概述
❝「Java8 的优势」
❞
速度更快 代码更少 强大的Stream API 便于并行 最大化减少空指针Optional
二、优化底层数据结构
2.1、优化HashMap
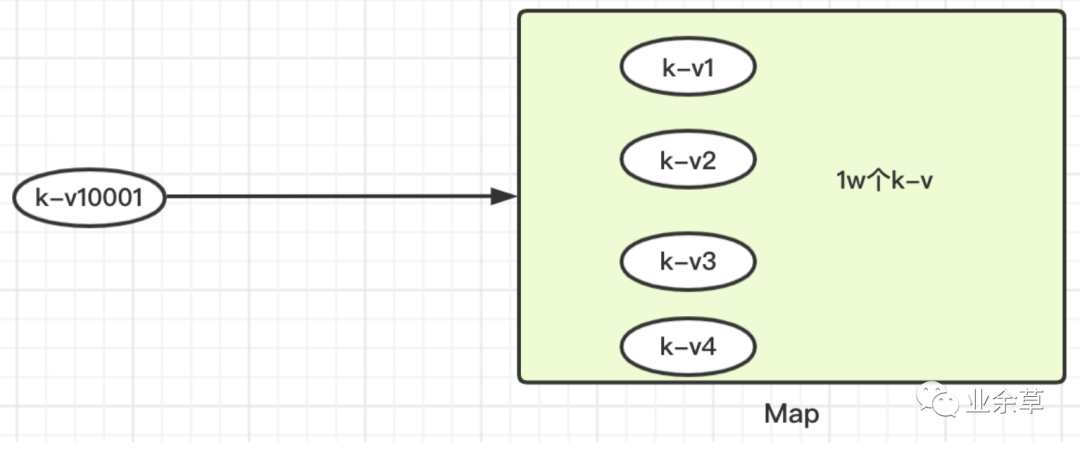
❝「【原始Map】」
第10001个值存入,为避免k值相同,会进行10000次equals,效率非常低
❞
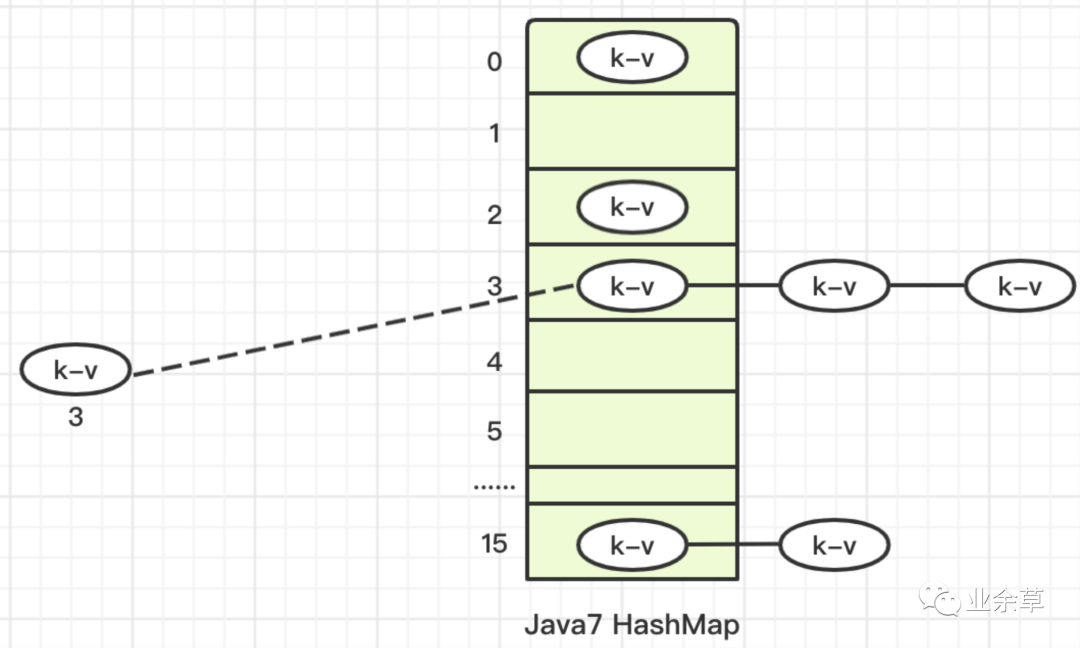
❝「【java7 HashMap】:数组+链表」
HashMap 是 16 个位置的数组,并提供"加载因子",当达到75%时,自动扩容,会对所有元素进行重新运算生成新的数组+链表
当存入值时,会先把值通过 hashcode 生成对应的索引,
确定索引后,会跟该索引下的值进行比较,比较len(链表长度)次,没有重复则形成链表(放链表头)。
效率有所提高,但是如果链表较长有10000个元素,依旧需要比较1000次。
❞
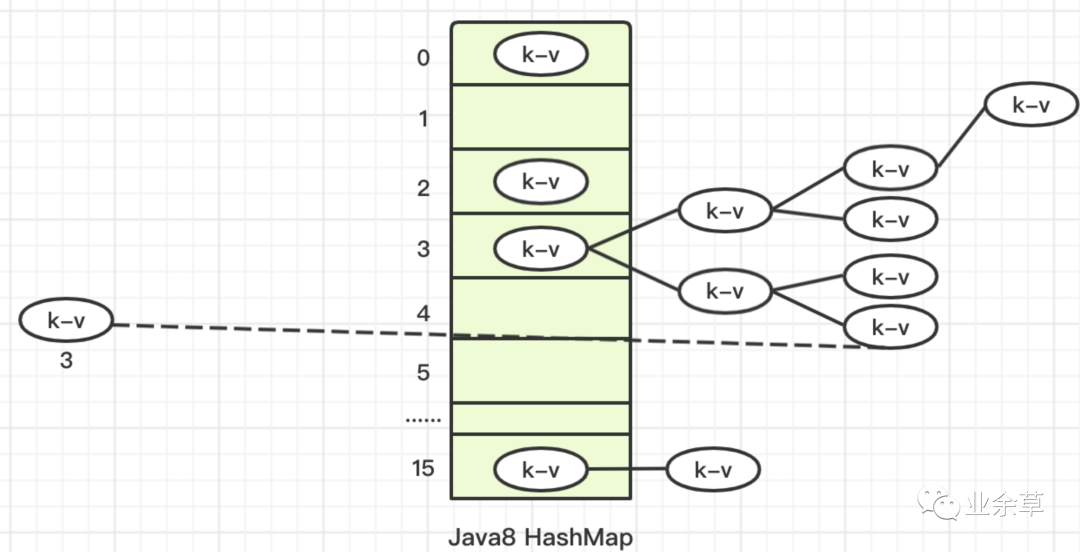
❝「【java8 HashMap】:数组+(链表/红黑树)」
当链表长度大于8,且hashmap总容量大于64,会将链表自动转为红黑树
添加元素比链表慢,其他的都比链表更快速
❞
三、Lambda表达式
3.1、概述
❝【概述】
❞
Lambda是一个匿名函数,可以理解为一段可以传递的代码。
Lambda是特殊的匿名内部类,允许将函数当做方法的参数传递
❝优势
❞
可以写出更简洁、更灵活的代码。
❝经验
❞
Lambda表达式的作用主要是用来简化接口的创建,interface。
需要注意的是:
1.任何需要使用interface的地方都可以使用Lambda表达式来简化;
2.Lambda表达式不能够简化类或者抽象类得创建,如果试图使用Lambda表达式去创建一个类或者抽象类
将会报错如下英文信息 ”Target type of a lambda conversion must be an interface“
这就是为什么Lambda表达式只用用来简化创建接口
3.2、匿名内部类到lambda
「匿名内部类」
// 匿名内部类
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("子线程开始执行。。。。");
}
};
new Thread(runnable).start();
「lambda表达式」
// lambda表达式
Runnable runnable2 = () -> System.out.println("lambda子线程开始执行。。。。");
new Thread(runnable2).start();
3.3、lambda语法
❝参数列表 -> 方法体
❞
「1、无参要写括号」
() -> System.out.println("无参");「2、只有一个参数,可以不写括号」
x -> System.out.println(x);「3、多条语句用{}」
Comparator com = (x, y) -> {
System.out.println("...");
return Integer.compare(x, y);
}
「4、若lambda体中只有一条语句,return和{}都可以不写」
Comparator
「5、lambda参数列表的数据类型可以省略不写(JVM编译器通过上下文做"类型推断")」
Comparator com = (Integer x, Integer y) -> Integer.compare(x, y);
Comparator com = (x, y) -> Integer.compare(x, y);
「6、匿名内部类会单独生成一个单独的.class文件,lambda表达式不会生成。」
3.4、函数式接口
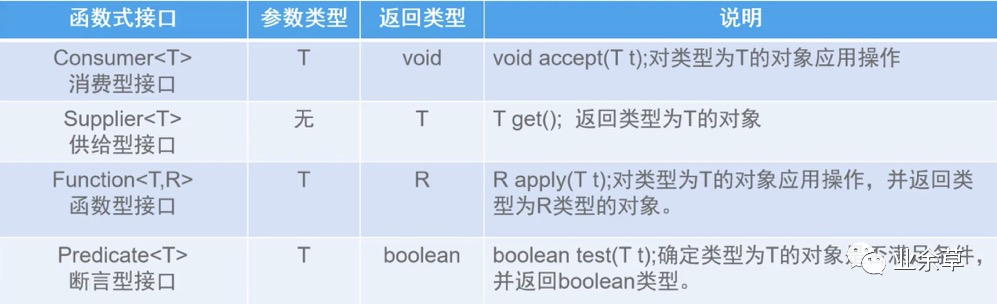
只有函数式接口(只有一个抽象方法的接口@FunctionalInterface)才能使用lambda表达式
❝常见函数式接口
❞
❝常用函数式接口子接口
❞
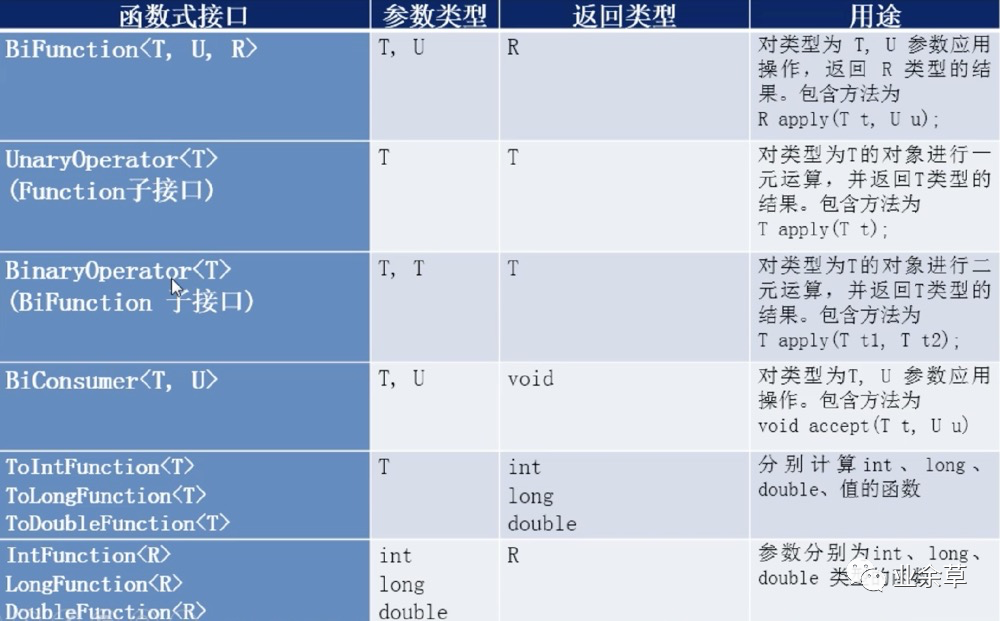
❝使用演示
❞
「Consumer(有参无返回值)」
@Test
public void test(){
// 匿名内部类
Consumer consumer1 = new Consumer(){
@Override
public void accept(Integer n) {
System.out.println(n + 1);
}
};
consumer(consumer1, 100);
// lambda
Consumer consumer = n -> System.out.println(n + 1);
consumer(consumer, 100);
}
public void consumer(Consumer consumer, Integer n) {
consumer.accept(n);
}
「Supplier(无参有返回值)」
@Test
public void test(){
// lambda表达式
int[] arr = getNums(() -> new Random().nextInt(100), 10);
System.out.println(Arrays.toString(arr));
}
public int[] getNums(Supplier supplier, int count){
int[] arr = new int[count];
for(int i=0; i arr[i] = supplier.get();
}
return arr;
}
「Function有参有返回值」
@Test
public void test(){
// lambda表达式
String str = dealStr(s -> s.toUpperCase(), "abc");
System.out.println(str);
}
public String dealStr(Function function, String str) {
return function.apply(str);
}
「Predicate有参,返回布尔值」
@Test
public void test(){
// lambda表达式
List ageList = new ArrayList<>();
ageList.add(10);
ageList.add(19);
List resultList = filterAge(age -> age > 18, ageList);
System.out.println(resultList.toString());
}
public List filterAge(Predicate predicate, List ageList) {
List resultList = new ArrayList<>();
for (Integer i: ageList) {
if(predicate.test(i)){
resultList.add(i);
}
}
return resultList;
}
3.5、方法引用
是Lambda表达式的一种简写
如果lambda表达式中,只是调用一个特定的已存在的方法,则可以使用方法引用
❝「对象::实例方法」
❞
// lambda表达式
Consumer consumer = s -> System.out.println(s);
consumer.accept("hello");
// 对象::实例方法
Consumer consumer2 = System.out::println;
consumer2.accept("world");
❝「对象::静态方法」
❞
// lambda表达式
Comparator comparator = (x, y) -> Integer.compare(x, y);
// 对象::静态方法
Comparator comparator2 = Integer::compare;
❝「类::实例方法」
❞
【注意】
1、Lambda体中参数列表和返回值类型,要与函数式抽象方法中抽象方法的保持一致
2、若Lambda参数列表中,第一个参数是实例方法的调用者,第二个是实例方法的参数,可以使用ClassName::method
// lambda表达式
BiPredicate bp = (x, y) -> x.equals(y);
// 对象::静态方法(ClassName::method)
BiPredicate bp2 = String::equals;
❝「类::new」
❞
「构造器引用」
// lambda表达式
Supplier supplier = () -> new User();
// 对象::静态方法
Supplier supplier2 = User :: new;
「数组引用」
// lambda表达式
Function function = x -> new String[x];
// 对象::静态方法
Function function2 = String[]::new;
四、Stream
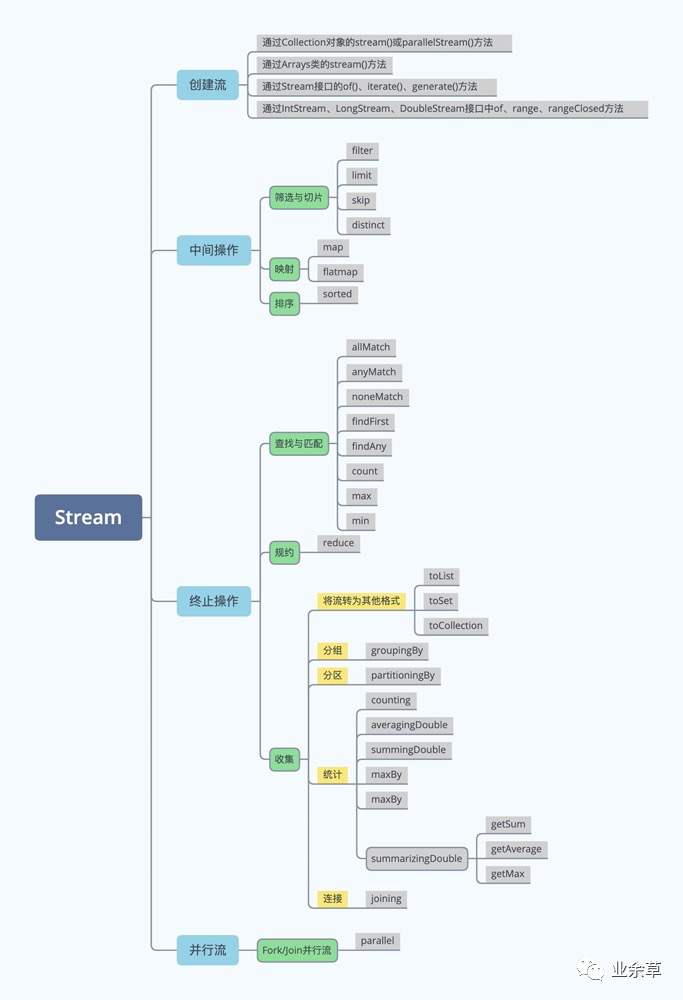
4.1、概述
❝「概述」
❞
【概述】:流(Stream)中保存对集合或数组数据的操作
【特点】:
1、Stream只保存操作,自己不保存数据
2、Stream不会改变原对象
3、Stream操作是延迟执行的(只有执行终止操作,才一次性全部执行,称为"惰性求值")
❝「操作步骤」
❞
「1、创建Stream」
一个数据源(如:集合、数组),获取一个流
「2、中间操作」
一个中间操作链,对数据源的数据进行处理
「3、终止操作」
一个终止操作,执行中间操作链,并产生结果。在这之后,该Stream就不能使用了
4.2、创建Stream
❝「【方式一】:通过Collection对象的stream()或parallelStream()方法」
❞
ArrayList arrayList = new ArrayList<>();
arrayList.add("hello")
// 创建Stream(单线程)
Stream stream = arrayList.stream();
// 创建Stream(并行流,多线程)
Stream stream = arrayList.parallelStream();
stream.forEach(Systerm.out::println);
❝「【方式二】:通过Arrays类的stream()方法」
❞
String[] arr = {"aaa", "bbb", "ccc"};
// 创建Stream
Stream stream = Arrays.stream(arr);
stream.forEach(Systerm.out::println);
❝「【方式三】:通过Stream接口的of()、iterate()、generate()方法」
❞
// 创建Stream(直接把一组数变为流)
Stream stream = Stream.of(10, 20, 30, 40, 50, 60);
// 创建Stream(迭代流,iterate(起始值, 操作方法),配合limit限制)
Stream stream = Stream.iterate(0, x -> x+2);
// 创建Stream(生成流,无参有返回值)
Stream stream = Stream.generate(() -> new Random().nextInt(100));
stream.forEach(Systerm.out::println);
// stream.limit(10).forEach(Systerm.out::println);
❝「【方式四】:IntStream」
❞
// 创建Stream(1, 2, 3)
IntStream stream = IntStream.of(1, 2, 3);
// 创建Stream([1, 10))
IntStream stream = IntStream.range(1, 10)
// 创建Stream([1, 10])
IntStream stream = IntStream.rangeClosed(1, 10)
4.3、中间操作
// 创建一个集合用于测试操作
List employees = Arrays.asList(
new Employee("张三", 18, 9999.99, Status.FREE),
new Employee("李四", 18, 8999.99, Status.FREE),
new Employee("王五", 18, 7999.99, Status.FREE),
new Employee("赵六", 18, 6999.99, Status.BASY),
new Employee("田七", 18, 5999.99, Status.BASY)
);
4.3.1、筛选与切片
❝「【filter】」:接收lambda,从流中排除某些元素
❞
// filter
Stream stream = employees.stream().filter(e -> e.getAge()>18);
stream.forEach(System.out :: println);
❝「【limit】」:截断流
❞
// limit
Stream stream = employees.stream().limit(2);
stream.forEach(System.out :: println);
❝「【skip】」:skip(n)类似于pandas的iloc[n:]
❞
// skip
Stream stream = employees.stream().skip(2);
stream.forEach(System.out :: println);
❝「【distinct】」:去重(根据hashcode和equals去重,因此,类要重写hashcode和equals方法)
❞
// distinct
Stream stream = employees.stream().distinct();
stream.forEach(System.out :: println);
4.3.2、映射map
map和flatmap的区别就相当于python list中append和extend的区别
❝「【map】」:接收函数,把函数应用在所有元素上(多个流相互独立在一个大流中)
❞
// 将元素转为大写
List list = Array.aslist("aaa", "bbb", "ccc");
list.stream().map(str) -> str.toUpperCase().forEach(System.out :: println);
// 提取员工名
employess.stream().map(Employee:getName).forEach(System.out :: println);
❝「【flatmap】」:接收函数,把函数应用在所有元素上(多个流合完全混合成一个大流)
❞
List list = Arrays.aslist("aaa", "bbb", "ccc");
// 编写将字符串拆分为字符的方法,返回一个流
public Stream filterCharacter(String str) {
List list = new ArrayList<>();
for (Character ch : str.toCharArray()){
list.add(ch)
}
return list.stream()
}
// 【方式1】:使用map的方法使用以上方法
Stream> stream = list.stream().map(str) -> filterCharacter(str); //[['a', 'a', 'a'], ['b', 'b', 'b'], ['c', 'c', 'c']]
stream.forEach((sm) -> sm.forEach(System.out :: println));
// 【方式1】:使用flatmap的方法使用以上方法
Stream stream = list.stream().flatmap(str) -> filterCharacter(str); //['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c']
stream.forEach(System.out :: println);
4.3.3、排序sorted
❝【sorted】:排序
❞
// 员工自定义定义排序[sorted(无参)代表默认排序]
employees.stream().sorted(
(e1, e2) -> {
if (e1.getAge().equals(e2.getAge())){
return e1.getName().compareTo(e2.getName()); // 名字正序
}else {
return -e1.getAge().compareTo(e2.getAge()); // 年龄倒序
}
}
).forEach(System.out::println)
4.4、终止操作
4.4.1、查找与匹配
allMatch:检查是否匹配所有元素
anyMatch:检查是否至少匹配一个元素
noneMatch:检查是否没有匹配所有元素
findFirst:返回第一个元素
findAny:返回流中任意一个元素
count:返回流中元素的总个数
max:返回流中最大值
min:返回流中最小值
// 查看员工是不是全是18岁
Booblean b = employees.stream().allMatch((e) -> e.getAge().equals(18));
// 查看工资最高的员工 [Optional避免空指针]
Optional op = employees.stream()
.max((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary());
System.out.println(op.get())
// 查出工资为9999.99的随便一个员工
Optional op = employees.stream()
.filter((e) -> e.getSalary() == 9999.99)
.findAny();
System.out.println(op.get())
4.4.2、规约
❝reduce():将流中元素反复结合起来,得到一个值
❞
// 列表累加
List list = Arrays.asList(1, 2, 3, 4, 5, 6);
Integer sum = list.stream()
.reduce(0, (x, y) -> x + y); // 从索引0开始,累加
System.out.println(sum);
// 所有人工资总和
Optional op = employees.stream()
.map(Emplyee :: getSalary)
.reduce(Double :: sum);
System.out.println(op.get());
4.4.3、收集collect
Collectors实用类提供了很多静态方法,可以方便的创建常见收集器实例
❝将流转为其他格式
❞
// 把所有员工名放到列表
List li = employees.stream()
.map(Employee :: getName)
.collect(Collectors.toList());
// 把所有员工名放到HashSet
HashSet hs = employees.stream()
.map(Employee :: getName)
.collect(Collectors.toCollection(HashSet::new));
❝分组
❞
// 根据状态分组
Map> map = employees.stream()
.collect(Collectors.groupingBy(Employee :: getStatus));
System.out.println(map)
// 多级分组(先根据状态分,再根据年龄分)
Map>> map = employees.stream()
.collect(Collectors.groupingBy(Employee :: getStatus, Collectors.groupingBy(
(e) -> {
if (e.getAge()<18){
return "未成年";
} else{
return "成年";
}
}));
System.out.println(map)
❝分区
❞
Map> map = employees.stream()
.collect(Collectors.partitioningBy((e) -> e.getSalary()>8000));
❝统计
❞
// 公司总人数
Long count = employees.stream()
.collect(Collectors.counting());
// 工资平均值
Double avg = employees.stream()
.collect(Collectors.averagingDouble(Employee :: getSalary));
// 工资总和
Double sum = employees.stream()
.collect(Collectors.summingDouble(Employee :: getSalary));
// 最大值
List li = Arrays.asList(1, 3, 5, 6, 7);
Optional max = li.stream()
.collect(Collectors.maxBy((n1, n2) -> Double.compare(n1, n2)));
System.out.println(max.get());
// 最小值
List li = Arrays.asList(1, 3, 5, 6, 7);
Optional max = li.stream()
.collect(Collectors.maxBy((n1, n2) -> Double.compare(n1, n2)));
System.out.println(max.get());
DoubleSummaryStatistics dss = employees.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary));
System.out.println(dss.getSum()); // 求和
System.out.println(dss.getAverage()); // 求平均数
System.out.println(dss.getMax()); // 求最大值
❝连接
❞
String str = employees.stream()
.map(Employee::getName)
.collect(Collectors.joining(",", "===", "==="));
// ===张三,李四,王五,赵六,田七===
4.5、并行流
❝
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流(Fork/Join框架)java8中Stream API 可以通过
❞parallel()与sequential()在并行流与顺序流之间进行切换
4.5.1、Fork/Join框架
❝
更能充分的利用到cpu性能(各个CPU的利用率基本保持一致)【多线程】:某一核上线程阻塞,这样会造成多核中有的在阻塞有的在空闲,不能很好利用cpu资源
【Fork/Join】:使用工作窃取模式,当某一核上执行完,会帮助别的核执行任务
❞
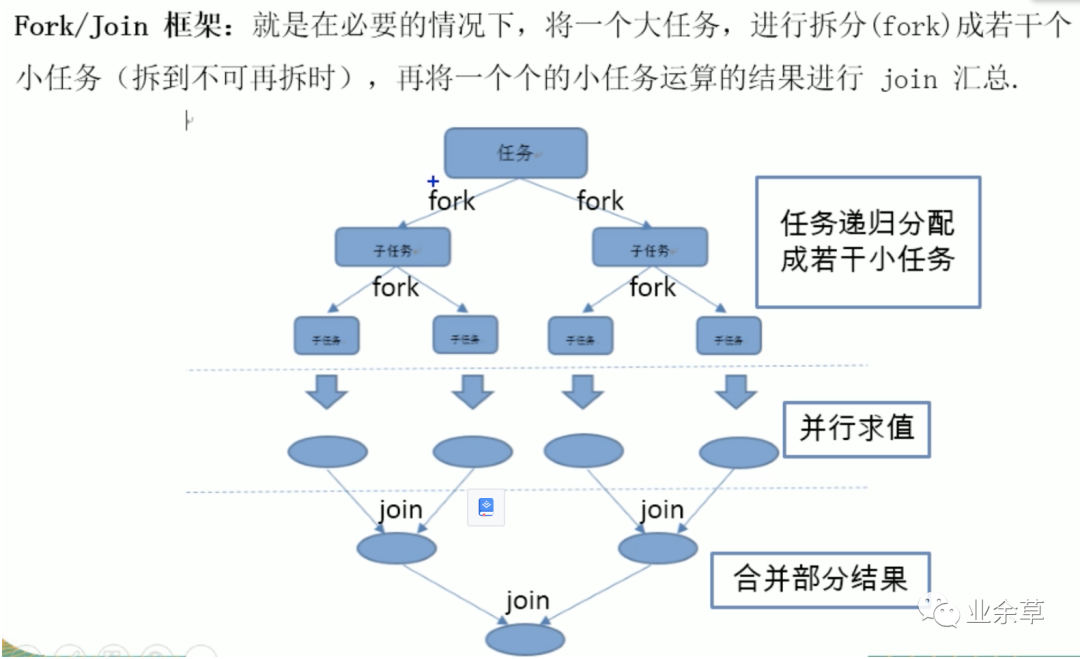
4.5.2、测试并行流
❝测试1000亿累加
❞
「循环累加」
Instant start = Instant.now();
long sum = 0;
for (long num=0; num<=100000000000L; num++){
sum += num;
}
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis()); // 耗时:30827
「Fork/Join并行流」
Instant start = Instant.now();
LongStream.rangeClosed(0, 100000000000L).parallel().reduce(0, Long::sum);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis());// 耗时:27704
五、新时间API
❝【Java.time】
线程安全、使用方便
❞
5.1、Java.time
5.1、日期
LocalDate localDate = LocalDate.now();
LocalDate localDate2 = LocalDate.of(2015, 12, 31);
5.2、时间
LocalTime localTime = LocalTime.now();
LocalTime localTime2 = LocalTime.of(21, 30, 59, 11001);
5.3、时间+日期
LocalDateTime localDateTime = LocalDateTime.now();
LocalDateTime localDateTime2 = LocalDateTime.of(2015, 11, 30, 23, 45, 59, 1234);
LocalDateTime localDateTime3 = LocalDateTime.of(localDate2, localTime2);
5.4、时间戳
//毫秒数时间戳
Long milliSecond = LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli();
//秒数时间戳
Long second = LocalDateTime.now().toEpochSecond(ZoneOffset.of("+8"));
// 时间戳转时间字符串
String result = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(milliSecond);
5.5、字符串转日期格式化
// 指定格式
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 将时间转化为指定格式字符串
String df = dtf.format(LocalDateTime.now());
// LocalDateTime格式字符串转LocalDateTime
LocalDateTime dt1 = LocalDateTime.parse("2016-11-30T15:16:17");
// 将指定格式字符串转化为LocalDateTime
LocalDateTime dt2 = LocalDateTime.parse("2016-11-30 15:16:17", dtf);
5.6、时间推移
// 5天后
LocalDateTime after5days = LocalDateTime.now().plusDays(5);
// 5天前
LocalDateTime before5days = LocalDateTime.now().minusDays(5);
// 加1月减2周
LocalDateTime monthWeek = LocalDateTime.now().plusMonths(1).minusWeeks(2);
5.7、时间抽取
// 年份
Integer year = LocalDate.now().getYear();
// 本年第几天
Integer dayOfYear = LocalDate.now().getDayOfYear();
// 月份
Integer month = LocalDate.now().getMonthValue();
// 几号
Integer dayOfMonth = LocalDate.now().getMonthValue();
// 周几
Integer week = LocalDate.now().getDayOfWeek().getValue();
// 获得本月第1天
LocalDate firstDay = LocalDate.now().with(TemporalAdjusters.firstDayOfMonth());
// 获得本月最后1天
LocalDate lastDay = LocalDate.now().with(TemporalAdjusters.lastDayOfMonth());
// 本月第1个星期天
LocalDate firstSunday = LocalDate.now().with(TemporalAdjusters.firstInMonth(DayOfWeek.SUNDAY));
// 判断那个日期在前
Boolean b = firstSunday.isBefore(LocalDate.now());
//相距多少年月日
Period p = LocalDate.now().until(LocalDate.of(2050, 1, 1));
//相距多少天
Long d = LocalDate.of(2050, 1, 1).toEpochDay() - LocalDate.now().toEpochDay();
5.8、时区
// 获取当前默认时区的日期和时间
ZonedDateTime now = ZonedDateTime.now();
// 获得时区(Asia/Shanghai)
now.getZone();
// 时区为0的时间
Instant ins = now.toInstant();
// 指定时区的时间
ZonedDateTime london = ZonedDateTime.now(ZoneId.of("Europe/London"));
//把伦敦时间转换到纽约时间
ZonedDateTime newYork = london.withZoneSameInstant(ZoneId.of("America/New_York"));
5.9、Date与LocalDateTime互转
// Date转LocalDateTime
LocalDateTime localDateTime = date.toInstant().atOffset(ZoneOffset.of("+8")).toLocalDateTime()
// LocalDateTime转Date
Date date = Date.from(localDateTime.toInstant(ZoneOffset.of("+8")))
六、Optional容器类
❝
使用Optional后,如果空指针一定是创建Optional实例时出现的,更容易定位Optional类(java.util.Optional)是一个容器类,代表一个值存在或不存在,原来用null表示一个值不存在,现在Optional可以更好的表达这个概念。并且可以避免空指针异常。
❞
「常用方法」
| 「函数」 | 「描述」 |
|---|---|
| Optional.of(T t) | 创建一个 Optional 实例 |
| Optional.empty() | 创建一个空的 Optional 实例 |
| Optional.ofNullable(T t) | 若 t 不为 null,创建 Optional 实例,否则创建空实例 |
| isPresent() | 判断是否包含值 |
| orElse(T t) | 如果调用对象包含值,返回该值,否则返回t |
| orElseGet(Supplier s) | 如果调用对象包含值,返回该值,否则返回 s 获取的值 |
| map(Function f) | 如果有值对其处理,并返回处理后的Optional,否则返回 Optional.empty() |
| flatMap(Function mapper) | 与 map 类似,要求返回值必须是Optional |
七、接口中的默认方法与静态方法
❝在java8中允许有实现的静态方法和默认方法
❞
「"类优先"原则」 接口和父类冲突,使用父类的方法。(一个类继承的父类和接口实现了同名的方法,父类的会生效) 接口冲突,需要指定。(一个类实现两个接口,两个接口有同名的实现方法,需要使用接口名.supper.方法名,指定使用哪个) 「示例」
public interface MyInterface {
// 允许有实现的默认方法
default String getName(){
return "接口中的默认方法";
}
// 允许有实现的静态方法
public static String show(){
return "接口中的静态方法";
}
}
八、重复注解与类型注解
8.1、重复注解
❝java8支持方法使用重复注解(同一个注解使用两次)
新的反射API提供了getAnnotationsByType()方法,获得该注解所有的值
❞
「定义注解容器类」
要想定义重复注解,必须要先定义一个该注解的容器
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@interface MyAnnotations{
MyAnnotation[] value();
}
「自定义一个注解」
要用@Repeatable修饰,并指定容器类
// 要用@Repeatable修饰,并指定容器类
@Repeatable(MyAnnotations.class)
// 表示注解的适用范围(TYPE:类, METHOD:方法)
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@interface MyAnnotation{
// 注解的参数:类型 参数名
int time() default 1000;
}
「重复注解」
public class TestAnnotation {
@MyAnnotation(100)
@MyAnnotation(200)
public void show(){
}
}
「使用反射的getAnnotationsByType()获取所有值」
Class clazz = TestAnnotation.class;
Method m1 = clazz.getMethod("show");
MyAnnotation[] mas = m1.getAnnotationsByType(MyAnnotation.class);
for (MyAnnotation myAnnotation : mas){
System.out.println(myAnnotation.value()); // 100、200
}
8.2、类型注解
❝注解的@Target可以使用TYPE_PARAMETER,可以用注解给参数赋默认值
类似于@RequestParam,@RequestParam使用的是PARAMETER,给形参设置默认值
❞
@MyAnnotation(100)
public void show(@MyAnnotation(111) Integer num){
}
8.3、@NonNull注解
❝提供@NonNull注解,如果运行时加了该注解的值是null则运行时则会报错(运行时异常)
但是在java8中并没有内置,不可以直接使用,可以配合框架使用,不如SpringBoot中可以使用
❞
// obj如果为null,运行时会报错 private @NonNull Object obj;