
为什么Pod突然就不见了?
共 9032字,需浏览 19分钟
·
2021-07-28 01:26

最近发生一件很诡异的事情, 某个 ns 下的 pods 会莫名其妙地被删了, 困扰了好一阵子,排查后发现问题的起因还是挺有意思。
问题现象
交代一下背景, 这些 pod 都是由 argo-workflow 发起的 pod, 执行完特定的任务之后就会变成 Succeeded, 如果执行时有问题,状态可能是 Failed。
结果很直接,就是在 ns 下的某些状态为 Failed pod 会被删掉(后来证实 Succeeded 状态的也会被删掉),所以会出现尴尬的情况是想找这个 pod 的时候,发现这个 pod 却没了,之前反映过类似的问题,但一直以为是被别人删了,没有在意,但是第二次出现,感觉不是偶然。
开发同学肯定没权限做这个事,运维侧也可以肯定没有这类操作,排查了一圈几乎可以肯定的是,不是人为的, 那不是人做的,就只能中 k8s 这边的某些机制触发了这个删除的操作,kubernetes 可以管理千千万万的 pod 资源,因此 gc 机制是必不可少的,作者也是第一时间想到了可能是 gc 机制引起的。
在详细追踪 k8s 的 podGC 问题之前,其实还有一个嫌疑犯需要排查,那就是 argo-workflow, argo-workflow 做为一种任务 workflow 的实现方式,argo-workflow 本身也可以通过CRD来检测当 workflow 执行到达什么状态时进行 podGC, 如下图:
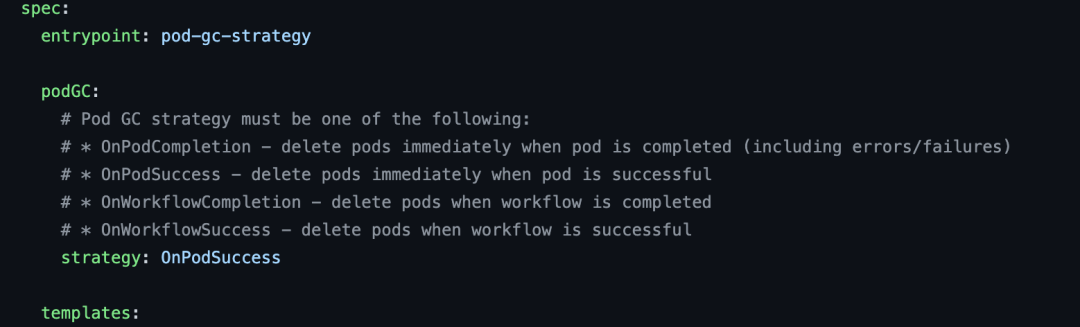
但作者可以肯定的是,那些被删除的 pod 中并未使用 argo-workflow 的 podGC,因此 argo-workflow 的嫌疑可以排除.
那么现在就剩 k8s 本身的机制了
PodGC
k8s 中存在在各种各样的 controller(感兴趣的可以看看 controllermanager.go 中的 NewControllerInitializers 中列出来的 controllers 对象), 每一个 controller 专注于解决一个方面的问题, podGC controller 也是如此,专门回收 pod。
既然 pod 被回收了,是不是可以从 controllermanager 的日志中看到什么呢?果然

从上面的日志也可以证实,pod 确实是 controller 被回收了,但是怎么个回收法呢?依据是什么,时间间隔多久等等一系列问题相继涌出
gc_controller.go
源码能够得到一切答案,大多数都来自于pkg/controller/podgc/gc_controller.go
const (
// gcCheckPeriod defines frequency of running main controller loop
gcCheckPeriod = 20 * time.Second
// quarantineTime defines how long Orphaned GC waits for nodes to show up
// in an informer before issuing a GET call to check if they are truly gone
quarantineTime = 40 * time.Second
)
首先是 gc 的时间间隔,很显然是 20s,而且这个数值不支持从命令参数中配置
quarantineTime 是在删除孤儿 pod 时等待节点 ready 前的时间
那根据什么删除的呢, 同样,在源码中给了答案
pod.status.phase
func (gcc *PodGCController) gcTerminated(pods []*v1.Pod) {
terminatedPods := []*v1.Pod{}
for _, pod := range pods {
if isPodTerminated(pod) {
terminatedPods = append(terminatedPods, pod)
}
}
terminatedPodCount := len(terminatedPods)
deleteCount := terminatedPodCount - gcc.terminatedPodThreshold
if deleteCount > terminatedPodCount {
deleteCount = terminatedPodCount
}
if deleteCount <= 0 {
return
}
klog.Infof("garbage collecting %v pods", deleteCount)
// sort only when necessary
sort.Sort(byCreationTimestamp(terminatedPods))
var wait sync.WaitGroup
for i := 0; i < deleteCount; i++ {
wait.Add(1)
go func(namespace string, name string) {
defer wait.Done()
if err := gcc.deletePod(namespace, name); err != nil {
// ignore not founds
defer utilruntime.HandleError(err)
}
}(terminatedPods[i].Namespace, terminatedPods[i].Name)
}
wait.Wait()
}
这里的日志输出刚好也是 controllermanager.go 中的日志输出,主要的逻辑在如何判定一个 pod 是否需要被删除
func isPodTerminated(pod *v1.Pod) bool {
if phase := pod.Status.Phase; phase != v1.PodPending && phase != v1.PodRunning && phase != v1.PodUnknown {
return true
}
return false
}
判断一个 pod 是否需要被删除,主要看一个 pod 的状态,在 k8s,一个 pod 大概会有以下的状态(phases)
Pending Running Succeeded Failed Unknown
得到所有的 pods 实例,对于 status.phase 不等于 Pending、Running、Unknown 的且与 terminatedPodThreshold 的差值的部分的 pod 进行清除,会对要删除的 pod 的创建时间戳进行排序后删除差值个数的 pod,注意这里也会把 succeeded 的状态 pod 给删除,作者对这个把 succeeded 状态的 pod 给 gc 了还是比较奇怪的
gcOrphaned
另外,回收那些 Binded 的 Nodes 已经不存在的 pods,这个没什么好说的,node 都不存在了,pod 也没存在的必要了
逻辑是调用 apiserver 接口,获取所有的 Nodes,然后遍历所有 pods,如果 pod bind 的 NodeName 不为空且不包含在刚刚获取的所有 Nodes 中,最后串行逐个调用 gcc.deletePod 删除对应的 pod
func (gcc *PodGCController) gcOrphaned(pods []*v1.Pod, nodes []*v1.Node) {
klog.V(4).Infof("GC'ing orphaned")
existingNodeNames := sets.NewString()
for _, node := range nodes {
existingNodeNames.Insert(node.Name)
}
// Add newly found unknown nodes to quarantine
for _, pod := range pods {
if pod.Spec.NodeName != "" && !existingNodeNames.Has(pod.Spec.NodeName) {
gcc.nodeQueue.AddAfter(pod.Spec.NodeName, quarantineTime)
}
}
// Check if nodes are still missing after quarantine period
deletedNodesNames, quit := gcc.discoverDeletedNodes(existingNodeNames)
if quit {
return
}
// Delete orphaned pods
for _, pod := range pods {
if !deletedNodesNames.Has(pod.Spec.NodeName) {
continue
}
klog.V(2).Infof("Found orphaned Pod %v/%v assigned to the Node %v. Deleting.", pod.Namespace, pod.Name, pod.Spec.NodeName)
if err := gcc.deletePod(pod.Namespace, pod.Name); err != nil {
utilruntime.HandleError(err)
} else {
klog.V(0).Infof("Forced deletion of orphaned Pod %v/%v succeeded", pod.Namespace, pod.Name)
}
}
}
gcUnscheduledTerminating
另外,回收 Unscheduled 并且 Terminating 的 pods,逻辑是遍历所有 pods,过滤那些 terminating(pod.DeletionTimestamp != nil)并且未调度成功的(pod.Spec.NodeName 为空)的 pods, 然后串行逐个调用 gcc.deletePod 删除对应的 pod
func (gcc *PodGCController) gcUnscheduledTerminating(pods []*v1.Pod) {
klog.V(4).Infof("GC'ing unscheduled pods which are terminating.")
for _, pod := range pods {
if pod.DeletionTimestamp == nil || len(pod.Spec.NodeName) > 0 {
continue
}
klog.V(2).Infof("Found unscheduled terminating Pod %v/%v not assigned to any Node. Deleting.", pod.Namespace, pod.Name)
if err := gcc.deletePod(pod.Namespace, pod.Name); err != nil {
utilruntime.HandleError(err)
} else {
klog.V(0).Infof("Forced deletion of unscheduled terminating Pod %v/%v succeeded", pod.Namespace, pod.Name)
}
}
}
disable podGC controller
Podgc 是不是可以配置呢?
很遗憾的是,配置项不是很多,可以定义是否开启 podgc controller
controller-manager 的启动参数中有个参数:
--terminated-pod-gc-threshold int32 Default: 12500
Number of terminated pods that can exist before the terminated pod garbage collector starts deleting terminated pods. If <= 0, the terminated pod garbage collector is disabled.
这个参数指的是在 pod gc 前可以保留多少个 terminated pods, 默认是 12500 个,这个数值还是挺大的,一般集群怕是很难能到,作者由于是训练集群,存在着大量的短时间任务,因此会出现大于该值的 pod,当该值小于等于 0 时,相当于不对 terminated pods 进行删除,但还是会对孤儿 pod 及处于 terminating 状态且没有绑定到 node 的 pod 进行清除.
参考: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/[1]
作者只查到这一个跟 podgc 相关的参数,目测好像在不修改 controllermanager 的情况下是没办法直接禁用 podgc
到此,真相大白:
同时也给作者纠正了一个错误, 不是只有 Failed 状态的 pod 才会被 gc,Successed 状态的 pod 也会被 gc 掉,这个出乎作者意料之外
最后,想说的是,podgc 跟 k8s 中的垃圾回收还不是一回事,虽然他们都是以 controller 运行,
podgc 解决的是 pod 到达 gc 的条件后会被 delete 掉.
而 garbage 则解决的是对节点上的无用镜像和容器的清除
从 k8s 的源码也能够看出来这两者的不同.
参考文章
https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/[2] https://cloud.tencent.com/developer/article/1097385[3]
脚注
https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/
[2]https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/
[3]https://cloud.tencent.com/developer/article/1097385: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/
原文链接:https://izsk.me/2021/07/26/Kubernetes-podGC/


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
