
改进YOLOX | Push-IOU+Dynamic Anchor进一步提升YOLOX性能
点击下方卡片,关注「集智书童」公众号

道路目标检测是自动驾驶技术中的一个重要分支,检测精度越高的模型越有利于车辆的安全驾 驶。在道路目标检测中,小目标和遮挡目标的漏检是一个重要的难题,降低目标的漏检率对于安全驾驶具有重要意义。
在本文的工作中,基于 YOLOX 目标检测算法进行改进,提出了 DecIoU 边界框回归损失函数来提高预测框和真实框的形状一致性,并引入 Push Loss 来进一步优化边界框回归损失函数,以检测出更多的遮挡目标。此外,还使用了动态锚框机制来提升置信度标签的准确性,改善了无锚框目标检测模型的标签不准确的问题。
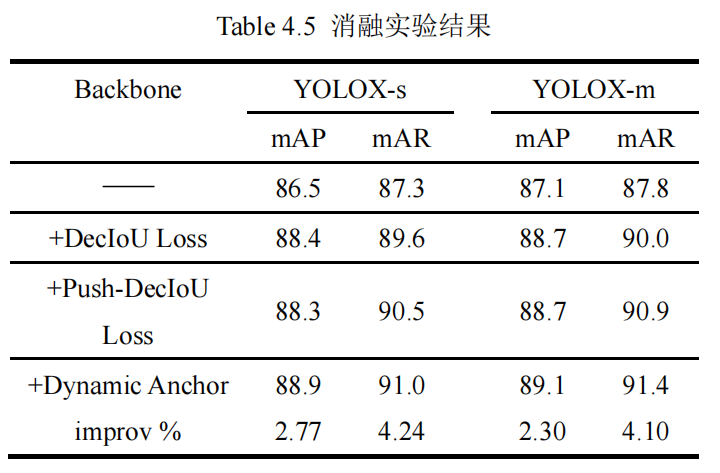
在 KITTI 数据集上的大量实验证明了所提出的方法的有效性,改进的 YOLOX-s 在 KITTI 数据集上的 mAP 和 mAR 分别达到 88.9%和 91.0%,相比基线版本提升 2.77%和 4.24%;改进的 YOLOX-m 的 mAP 和 mAR 分别达到 89.1%和 91.4%,提升了 2.30%和 4.10%。
1、介绍
近年来,自动驾驶汽车不断走进我们的视野中,面向自动驾驶的目标检测算法也成为了国内外的研究热点之一。安全可靠的自动驾驶汽车依赖于对周围环境的准确感知,以便及时做出正确的决策。目标检测是自动驾驶系统的关键任务之一,其主要的功能是检测前方道路上出现的目标的空间位置和目标类别。
传统目标检测算法依赖于手工设计好的特征来对目标进行特征提取,以实现分类和检测的目的,常见的目标特征包括 Scale Invariant Feature Transform (SIFT)、 Speeded up robust features (SURF)、histogram of oriented gradient (HOG) et al. 该类方法设计出的特征泛化能力弱、鲁棒性较差。2012 年,Krizhevsky et al.提出了以 Convolutional Neural Networks (CNN)为基础的 AlexNet 算法框架,极大的提升了算法的速度和准确度。
相比于传统目标检测算法,以CNN 为核心的目标检测算法具有准确率高、检测速度快等优点,发展潜力巨大。根据神经网络的结构不同,可以将目标检测算法分为两阶段目标检测算法和一阶段目标检测算法。2014年,Girshick et al.提出了 RCNN 目标检测算法,在目标检测数据集 VOC2012 上取得了30%以上的精度提升。2015年,基于 RCNN 改进的 Fast R-CNN、Faster R-CNN 等在检 测速度和精度上获得进一步提升,逐渐成为了目标检测的首选方法。R-CNN 系列目标检测算法是典型的两阶段目标检测算法,第一阶段通过算法生成候选区域,第二阶段利用 CNN 网络对候选区域进行 特征提取并根据提取的特征进行分类工作,得到最终的检测结果。
R-CNN 系列目标检测算法以较慢的速度换取了较高的检测精度,在自动驾驶、智慧交通等实时 检测场景中无法满足需求。2016 年,Redmon et al. 提出了 You Only Look Once(YOLO) 有效的改善了这一问题。YOLO 网络只需要“看”一次输入图片,即可输出最终的检测结果,是典型的一阶段目标检测算法,具有网络结构简单、检测速度快等优点。随后,YOLO v2~v5 相继提出,较好的平衡了精度和速度的,YOLO 算法的优异性能表现将一阶段目标检测算法推向了主流。
2021年,旷视科技的 Ge et al.进一步研究了 YOLO 系列目标检测算法,并融合了解耦头、AnchorFree、SimOTA 和多正例等技术,提出了 YOLOX 目标检测算法,在满足实时性的前提下,进一步提升了近两个百分点的精度。
在本文的研究中,基于 YOLOX 目标检测算法 进行损失函数的优化,以改善遮挡目标和小目标等困难目标检测精度较低的问题。简而言之,本文的主要贡献如下:
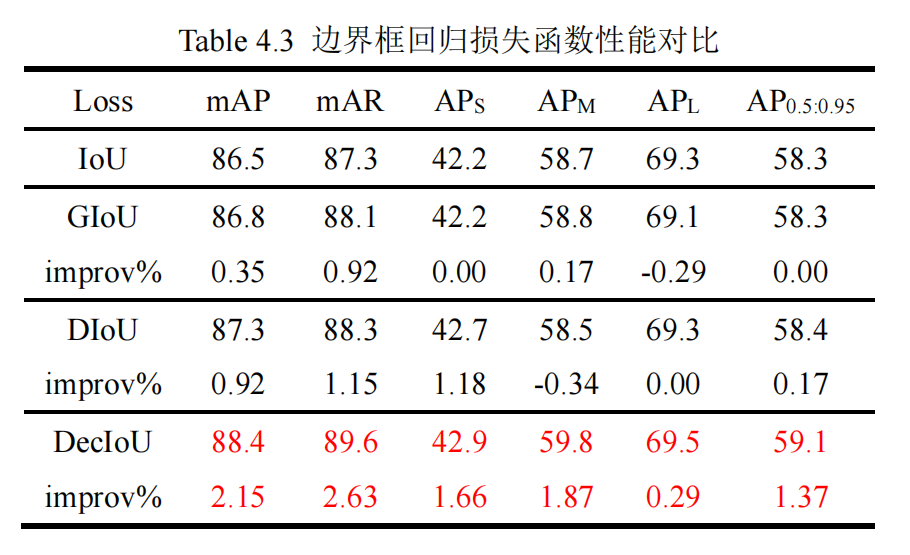
提出 DecIoU,通过对面积进行解耦来优化预测框的形状,提高预测框和真实框的形状一致性,并与 IoU、GIoU、DIoU 等其他损失函数对比,证明了 DecIoU 的有效性; 采用 Push Loss 并应用于边界框回归损失中,提高了 YOLOX 在 KITTI 数据集上的检测精度,检测出更多的遮挡目标; 采用动态锚框来优化置信度标签分配,生成更准确的标签值以优化模型训练,最终得到检测性能更好的模型。
2、本文方法
2.1、 解耦 IoU 损失
目标检测任务可分为目标分类和目标定位两个任务。目标分类是要对检测到的目标进行分类以确定其属于哪一个类别。目标定位是要在图像中确定待检测目标的位置信息,输出其在图像中的坐标。目标定位依赖于边界框回归去定位目标,通过在模型训练过程中最小化边界框回归损失,以优化所预测边界框的位置,达到定位目标的目的。传统的边界框回归损失一般通过 L1 或 L2 距离范数来定义,忽视了坐标间的关联性。2016 年,Yu et al.在人脸检测任务中提出了 Intersection over Union(IoU)损失函数以建立坐标之间的关联性,提升边界框回归性能。IoU 是比较两个形状之间相似性的最常用度量,是目标检测任务中的主要评价指标之一,将度量本身作为优化的目标是更佳的选择,IoU 损失已经在检测、跟踪和分隔等任务中广泛应用,成为边界框回归任务的最佳损失函数之一,IoU 和基于 IoU 的损失定义如下:
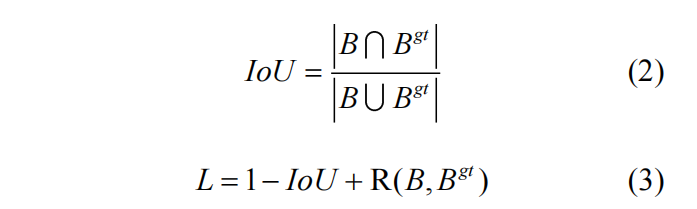
式中 表示预测框, 表示真实框。然而当预测框和真实框不重合时 IoU 为 0,使用 IoU 损失将无法度量预测框和真实框的远近,无法进一步优化预测框。为了改善该问题,斯坦福学者 Rezatofighi et al.在 2019 年提出了 GIoU,随后 Zheng et al.提出 DIoU 再一次优化了边界框回归损失函数,GIoU 和 DIoU 定义如下:
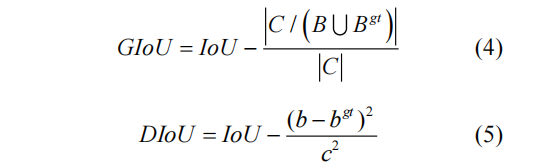
式中 表示能包含 和 的最小外接矩形框, 和 分别表示 和 的中心点, 表示 的对角线长度。
IoU 等损失函数主要从边界框面积之间的差距进行优化,在优化过程中无法保证预测框和真实框形状的相似性。受 L1 和 L2 损失函数的启发,我们在 IoU 损失基础上对边界框面积进行解耦,添加宽和高惩罚项,在最小化预测框和真实框面积差距的 同时优化其形状相似性,这对于遮挡目标和小目标 等困难目标检测有重要意义,更合理的检测框形状 将减小该框在后处理过程中被过滤掉的概率,提升 目标检测的召回率。本文将解耦 IoU 定义如下:
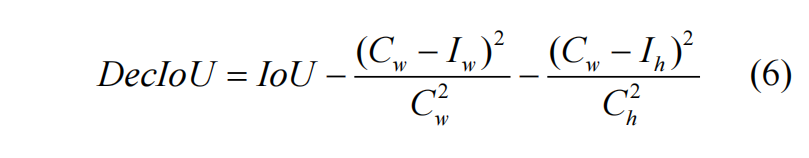
式中, 、 分别表示 和 重叠部分的宽和高, 、 分别表示 的宽和高。由此可得如算法 1 所示的 DecIoU 损失函数,以优化边界框回归。


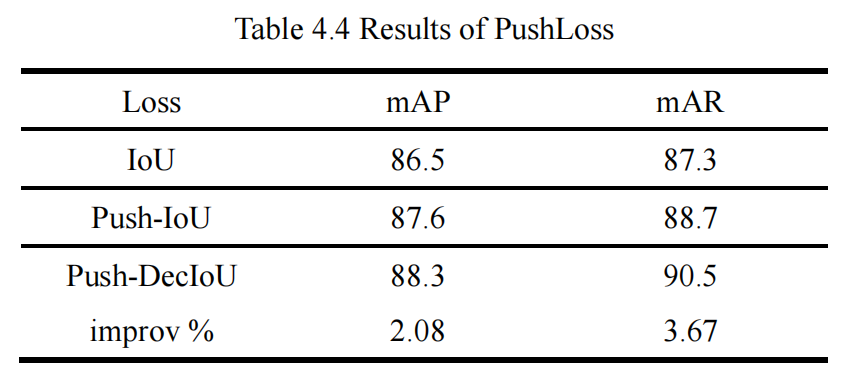
2.2、Push-IoU 和 Push-DecIoU 损失
目标遮挡是目标检测任务的难题之一,Luo et al.提出 Pull loss 和 Push loss 应用于模型训练中,较好的改善了遮挡目标的漏检问题。在目标检测算法训练的过程中,我们把预测框和真实框(Groundtruth)进行匹配,当一个预测框和 Ground-truth 匹配后,则该框为正样本;反之,未成功匹配的预测框为负样本。在 YOLOX 中,每个预测框最多匹配一个 Ground-truth,当道路上两个目标之间的发生遮挡时,相应的真实框之间出现部分重叠,这将使得两个目标最终的预测框之间出现重叠,在算法的后处理过程中有可能将重叠的预测框过滤掉,从而产生目标的漏检,每一个漏检的目标都关乎着车辆的行驶安全。为了进一步减小漏检情况的发生,我们对 IoU 损失进行了优化,改进后的 Push-IoU 损失 函数包含 IoU 损失和 Push 损失两部分,如算法 2 所示。


在 Push 损失中,我们提出了“Second Groundtruth”,如图 3.1 所示,对于一个已经匹配了真实框的正样本预测框,将进一步在该预测框周围的所有真实框中寻找一个与之 IoU 最大的真实框作为 “Second Ground-truth”(如图 3.1 中 )。在训练的过程中,最大化该正样本预测框和 框的 IoU,最小化该框和 的 IoU,尽可能的将两个遮挡目标对应的预测框推开,减小重叠部分,降低在后处理过程中被过滤掉的可能性。此外,我们为 Push 损失设置了超参数 来调节 IoU 损失和 Push 损失的比例,以控制推开预测框的力度,避免预测框偏移过多而成为低质量预测框。

2.3、动态锚框
置信度损失是目标检测损失函数中的重要损失之一,置信度是指边界框中包含目标的可能性以及包含目标情况下边界框准确度的乘积,计算公式如下:
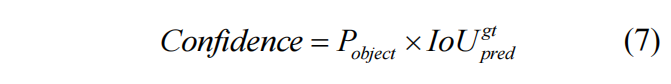
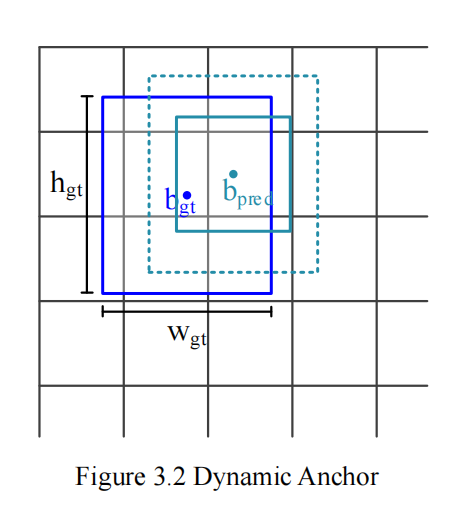
预测框置信度的大小反应了该预测框中包含待检测目标的概率。在目标检测算法中,通常将输入图片分割成 个格子,如果一个格子中包含待检测目标,则 ,反之 。对于基于锚框的目标检测算法,先验锚框通过训练集统计得出,可以较好的反应数据集中目标宽高的分布,在训练早期能够得到更加准确的预测框。YOLOX 是无锚框的目标检测算法,训练早期的预测框随机性较大, 较小,这将使得包含目标的单元格的置信度标签 偏小,无法准确反应该单元格包含目标的概率。神经网络的训练是追求预测值和标签值的不断靠近,标签值的准确性对于目标检测模型的训练至关重要。本文引入了动态锚框来辅助 的计算,以生成更加准确的置信度标签值。如图 3.2 所示, 和 分别为预测框和真实框的中心点,预测框的中心点已经较好的贴合真实框中心点,具有成为高质量预测框的潜力,然而由于宽和高的差距,最终 和 较小,该预测框在后续迭代训练过程中可能会被逐渐忽略。本文以预测框的中心点 作为中心点,构建一个宽和高分别为 、 的动态锚框(中心点随着预测框的动态变化而不断更新),以生成宽和高更加准确的辅助框用于计算置信度标签值,推动该预测框优化成为高质量预测框。
3、实验
3.1、实验环境
3.2、实验结果与分析
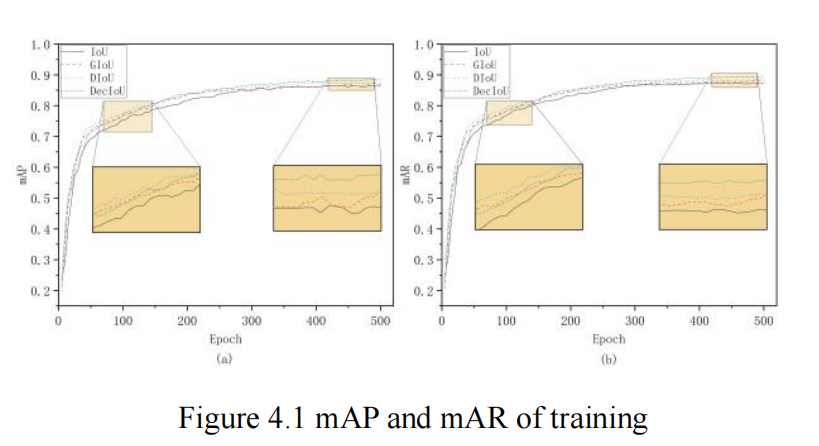
3.2.1、与基线版本对比

3.2.2、消融实验
4、参考
[1].基于改进 YOLOX 的道路目标检测算法研究.
5、推荐阅读

即插即用 | CFNet提出全新多尺度融合方法!显著提升检测和分割精度!

一文全览 | 自动驾驶Cornor-Case检测数据集

EdgeYOLO来袭 | Xaiver超实时,精度和速度完美超越YOLOX、v4、v5、v6

扫码加入👉「集智书童-目标检测」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!