
YOLOR 与 YOLOX的battle
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


前言
目标检测技术有两种广泛的范式——单级检测器和两级检测器。像 R-CNN 这样的两阶段模型有一个初始阶段的区域提议网络 (RPN),它全权负责在图像中寻找候选区域及其近似边界框。第二阶段网络使用 RPN 提出的局部特征来确定类别并创建更精细的边界框。这种任务分离允许第二阶段网络专注于学习与 RPN 提出的感兴趣区域隔离的特征,从而提高性能。
另一方面,像 YOLO 这样的单阶段方法具有映射到图像不同部分的网格单元,每个网格单元都与几个锚框相关联。其中每个锚框预测对象概率(目标存在的概率)、条件类概率和边界框坐标。大多数网格单元和锚点看到“背景”或无目标区域,少数看到ground truth。这阻碍了 CNN 的学习能力。
从历史上看,这是单级检测器与两级方法相比精度较低的主要原因之一。然而,近年来,新的单阶段检测模型的表现优于其两阶段对应模型。让我们来看看今年推出的两个最新的 YOLO 变体——YOLOR 和 YOLOX。
YOLOR

从不同角度查看相同的数据特征可以让人类回答大量的问题,这对于 CNN 来说目前是不可行的
人类通过刻意学习(显性知识)或潜意识(隐性知识)获得知识。这两种类型的结合使人类能够有效地处理数据,甚至是看不见的数据。此外,人类可以针对不同的目标从不同的角度分析相同的数据点。
然而,卷积神经网络只能从单一角度看数据。并且 CNN 输出的特征不适用于其他目标。该问题的主要原因是 CNN 仅利用来自神经元的特征,即显性知识。所有这些都没有利用丰富的隐性知识。
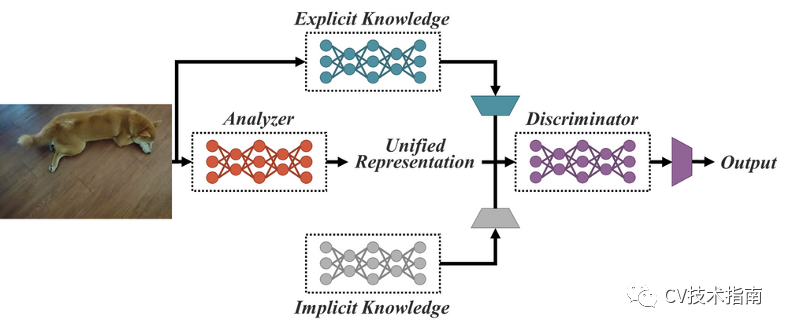
YOLOR’s unified network:结合显性知识和隐性知识为多个任务服务
YOLOR(You Only Learn One Representation)是一个融合了隐性知识和显性知识的统一网络。它使用 COCO 数据集中存在的所有任务预训练一个隐式知识网络,以学习一般表示,即隐式知识。为了针对特定任务进行优化,YOLOR 训练另一组代表显性知识的参数。隐性知识和显性知识都用于推理。
YOLOX
正如前面提到的 YOLO 模型获取图像并绘制一个由不同小方块组成的网格。然后从这些小方块中,他们从方块中回归以预测他们应该预测边界框的偏移量。仅这些网格单元就为我们提供了数万个可能的框,但 YOLO 模型在网格顶部有锚框。锚框具有不同的比例,使模型能够检测不同方向上不同大小的对象。
例如,如果数据集中有鲨鱼和长颈鹿,则长颈鹿需要瘦高的锚盒,鲨鱼需要宽而扁平的锚盒。虽然这两者的结合使模型能够检测范围广泛的对象,但它们也带来了计算成本和推理速度增加的问题。
YOLO 模型的另一个限制方面是边界框回归和对象检测任务的耦合,这会导致一些权衡。
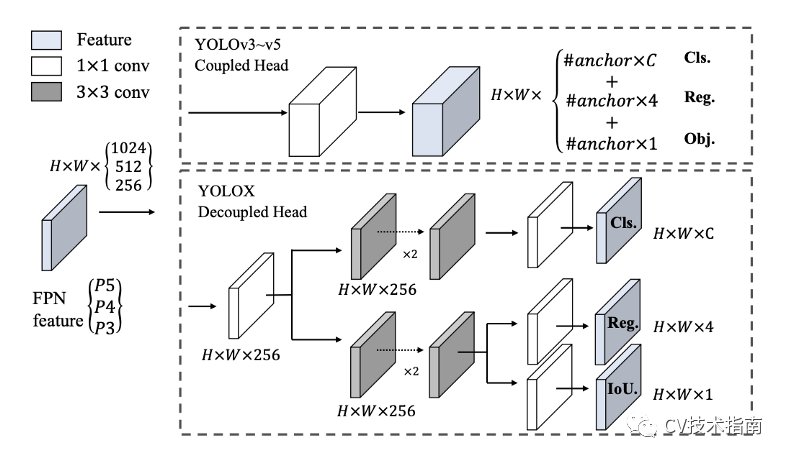
YOLOv3头和YOLOX使用的解耦头的区别
YOLOX 解决了这两个限制,它完全丢弃了框锚,从而提高了计算成本和推理速度。YOLOX 还将 YOLO 检测头解耦为单独的特征通道,用于框坐标回归和对象分类。这导致改进的收敛速度和模型精度。
YOLOR vs YOLOX
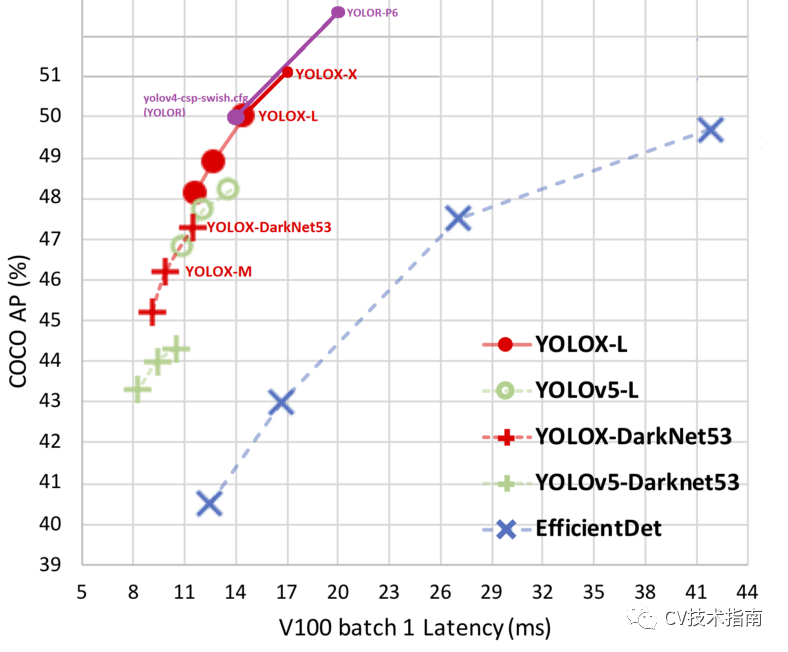
SOTA单级检测器的准确度与延迟图
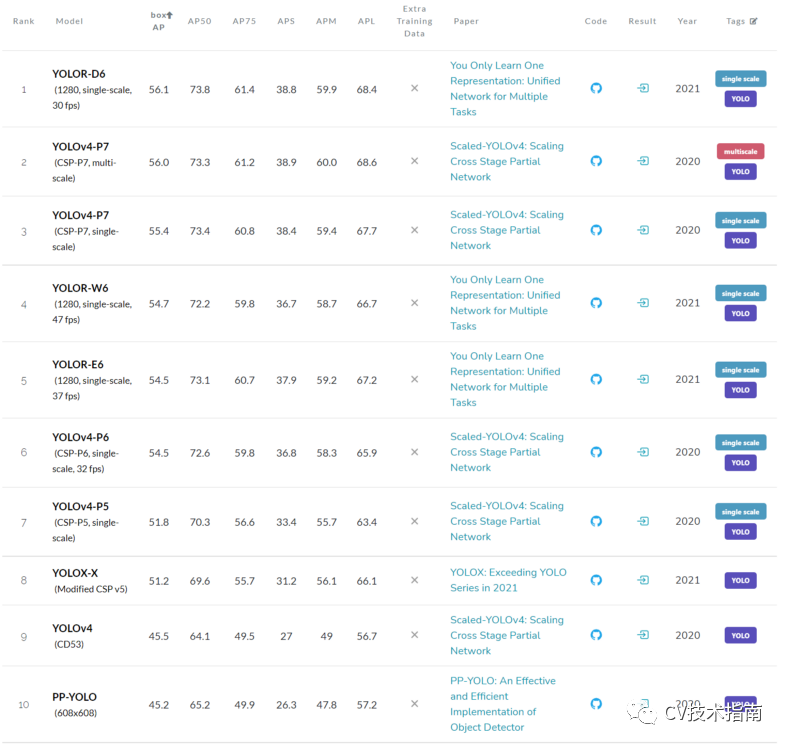
COCO test-dev 数据集上所有用于目标检测的 YOLO 模型的排行榜
在 COCO 数据集的目标检测排行榜上,唯一接近 YOLOR 的 YOLO 变体是 Scaled-YOLOv4,而 YOLOR 比它快了 88%!
除了在目标检测任务中提高性能外,YOLOR 的统一网络对于多任务学习非常有效。这意味着可以利用模型学习的隐式知识来执行目标检测之外的广泛任务,例如关键点检测、图像字幕、姿势估计等等。
此外,YOLOR 可以扩展到像 CLIP 这样的多模态学习,使其能够进一步扩展其隐性知识库,并利用其他形式的数据,例如文本和音频。
原文链接:
https://medium.com/augmented-startups/yolor-vs-yolox-battle-of-the-object-detection-prodigies-ae004a5ac8d2
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!