
复习社招面试整体思路
今天也像往常一样,早早起床来到公司,浏览了一下西安和太原的房价之后,心理不由自主地躁动了起来,躺平是不可能躺平的,这辈子都不可能躺平。创业又不会创,也就是卷这种东西,才能维持得了生活这样。进入程序员行业感觉就像回家一样,这里个个都是人才,说话又都好听,我超喜欢这里!
如何准备社招。参考了几个大佬的文章和视频之后,今天围绕这个问题来捋一捋思路,同时让自己也顺这个方向继续学下去。争取未来获得更多的加速度来尽可能地削弱前段时间的谜之操作对我自己后续人生产生的负面影响。整体的思路图如下所示,后续文章都围绕这张图展开。
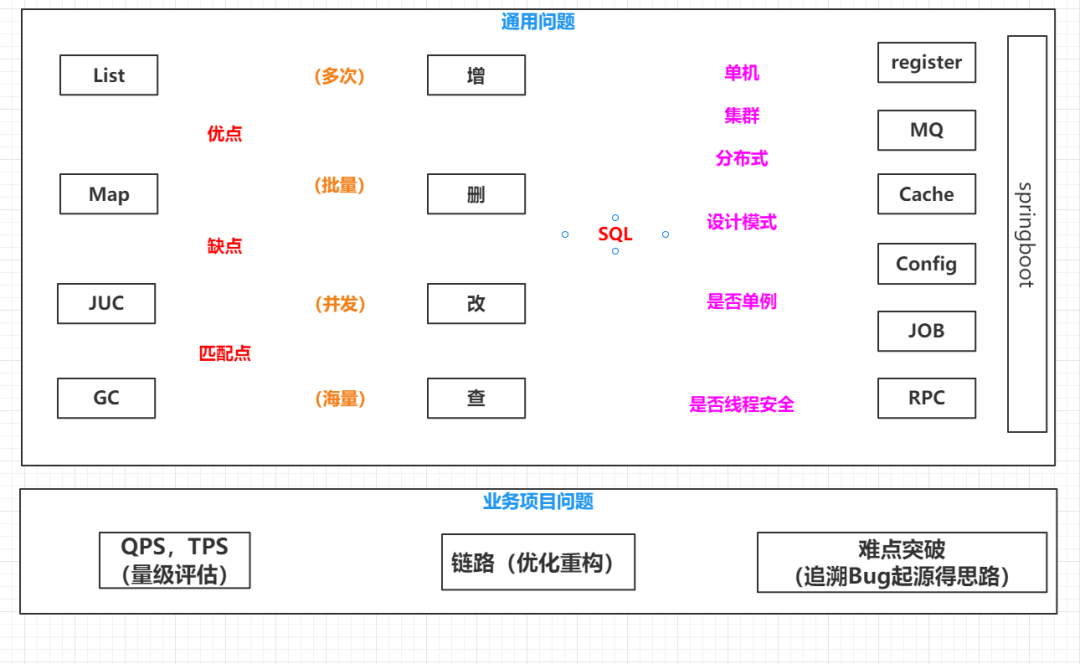
通用技术问题
每个技术点都有优点,缺点,匹配点。任何一个技术点,我们遇到之后都必须从这三个点进行分析整理。
Java是面向对象,面向接口编程的。一个接口有多个实现类,每一个实现类他的功能不一样,特性不一样。例如List,有ArrayList和LinkedList,所以很多面试问题都会有,ArrayList有什么优点,有什么缺点,你的项目中为什么使用ArrayList,而不用LinkedList。同样对于Map来说,有HashMap,LinkedHashMap,
TreeMap,ConCurrentHashMap。他们各自有什么优点,有什么缺点,你的项目中为什么要用HashMap,为什么要使用ConcurrentHashMap。所以每一个技术点都可以从这三个点去想。
除了Java基础之外,我们还会被问到很多框架,中间件之类的问题,而且占比一般都会超过Java基础。这里通过抽象,一般我们都要了解这几个东西,Cache缓存,MQ消息队列,RPC框架,JOB定时任务,Register组件,Config配置文件。
例如MQ来说,我们一般了解有三种实现,RabbitMQ,RocketMQ,Kafka。他们各自有什么优缺点,你为什么要在你的项目中用到它。你的项目为什么要用到RabbitMQ,为什么不用Kafka。这个问题确实也被问到过,而且我们大部分人回答的都是,因为架构师选择的是这个,然而这个回答肯定是不行的,明显是个敷衍的回答。
然后是SQL语句的面试,一般我们拧螺丝肯定就是增删改查了,大部分人的工作都是CRUD。但是造航母的话,就要在拧螺丝的任务上加上前缀。多次新增,批量修改,不批量删除,并发修改,海量查询。然后他们各自对应的什么场景。
批量新增的时候,你怎么能够保证新增是唯一的,如果说来了个业务数据他调用两次新增,你给他生成两条数据,那肯定是有问题的,如何去保证幂等,如何保证唯一。
批量删除的时候,怎么保证这个时候你的表可能有100万条数据,1千万条数据或者1亿条数据,这个时候你要怎么删除,直接delete一把删掉吗。如果要求你跑个一万条然后停顿个0.5秒之类的。
并发修改,如何去保证数据的准确,就是你改的确实是你想改的,或者你现在改的,就是你想改的那个数据。如果有两个的话,第一个过来先把它改成1,第二个想把它改成3,你怎么保证你改的是正确的,不会造成数据的一个缺失,对账错误之类的。
海量查询,当数据级达到一定量度的时候,最开始,假如数据库就那么10条数据,你随便select *也好,想怎么玩,就怎么玩。当数据量大的时候,就要考虑怎么去建立索引,你的Sql怎么写是满足索引的。
然后再往后面一块是各个中间件,我们学习得时候,可能都用的单机模式,就我们在自己的电脑上,去启动一个单机的redis,然后往里面去插数据,取数据,我们起一个单机的apollo,去往里面写配置,取配置。
但是实际上,基本上现在我们用的中间件,他们都是支持集群和分布式的,这个时候,它就有集群的特性,也有分布式的特性。分布式有什么特性,经典的CAP理论,你要知道哪个中间件它是符合CAP中的什么的,然后他是有什么特性。最后是这个中间件是怎么能够在我们的项目中用出来。
我们现在大部分项目都是Springboot,那么Springboot怎么跟他们去相结合呢,然后能够为你的项目进行助力,然后对Spring,还有本身的以及每个中间件,除了单机集群分布式,这些运行模式之外,还会有些知识点,就是他们这边用的什么设计模式,设计模式这一块,基本上社招的时候都会问到,像Spring中的一些设计模式啊,单例工厂组合模板,这个是必须要非常熟练的背下来的。
然后是否是单例,当你在看源码的时候,就是面试官喜欢考察你什么呢,就是非常典型的题目,就是一些非常典型的类,他会问你这个类,在这个中间件加载的时候,他是否是单例的,一般来说只要是配置类的话,基本上都是单例的,那么其他的典型类呢,这个就要具体问题具体分析了,去看源码。
然后第三个问题是是否是线程安全的,就比如Spring中,他哪些关键的方法是加了锁的,他为什么在这里加锁。如果这些随便一个问题,我们对这个没有概念的话,就会感觉到面试官又在瞎问了。
业务项目问题
程序员这行跳槽,其实并没有太受行业的限制,你可能上一家是在一个房地产公司做开发,那么下一次呢可能是在一个金融公司做开发,在下一次呢,很可能在一个医疗领域开发,在哪儿不都是写代码,在哪儿都是增删改查。你很有可能和你的面试官不是一个行业的。所以这个时候业务上问题,就根据你简历上写的项目,也会去问一些项目相关的问题。
第一个问题必问的是你现在做的一个业务是多大的一个量级。他的qps,或者tps是多少。这个时候你就要估计一下了。我们举个例子,比如说一个电商网站,一天又100万的UV,那么我们除以,比如他平均分布在10个小时上,我们除以10,那就是每个小时大概会有10万的UV,就是网站访问量。然后我们假设某个特定的时间段,比如说下午中午那一块,还有是访问量比较多的乘以2,那就等于一个小时有20万的UV。然后再除以3600s。最后得到的这个数字就是你的qps。所以在估计的时候,一定要根据自己的业务量估,不要瞎估就随口就报。一个qps 10000,我们qps20000,面试官都直接惊掉了下巴。
然后当你报出了自己的qps之后,面试官往往都会问一句说,假如你现在业务量翻了10倍,以后就qps乘以10,或者说qps乘以100,这个时候你怎么办。如何搭建一个高并发的系统,你就顺着你看的思路,如何去做页面缓存,怎么去做nginx缓存,然后nginx如何转发,如何负载均衡。然后怎么到服务器上来,然后继续做本地缓存,redis,然后数据库这里做个读写分离。读写分库,最后再搞个分库分表这些玩意儿。你就一步分析他到什么量级的时候,他的瓶颈是哪里,然后有了这个瓶颈之后,我们怎么去解决这个问题。一步一步过来就可以了。
然后第二个问题,200%会问到,你的业务链路是什么。所谓的链路就是你负责的这个模块,他的上游是什么,你的下游是什么。你的上游就是谁给你数据,你的下游就是谁会消费你的数据。然后你把这个链路描述清楚之后,后面就是问你怎么去优化他,怎么去重构他。所有的技术方案和业务背景是分不开的,当你在谈某个技术方案的时候,一定是跟他业务背景是强相关强绑定的,所以这个时候在说优化或者重构的时候,不要直接这样泛泛而谈。一定要先说,我们现在是在做一个什么业务,然后这个业务有什么特点,比如说这个业务还是读多写少,写多读少,比如说这个业务对实时性要求不高,那么在这个前提下,我们再去优化我们的技术方案或者重构方案。比如说如果是一个读多写少的一个业务场景的话,我们就把读库写库拆开,或者我们就多做缓存。如果说对实时性要求非常高的话,那用强一致性的数据是吧,一定是有业务场景的。
第三点,这个是1000%会问的一个点。你在项目中遇到哪些难点,或者你在做项目中最自豪的,最骄傲最有成就感的一点是哪里。这个呢,你可以说遇到一个源码级别的bug,或者源码级别的参数,然后你通过百度谷歌博客各种方式,发现博客写错了,然后自己跟着搞了半天,没搞定,然后呢点进了源码,再debug,然后怎么配置参数,传递参数,模拟啊各种操作,最终找到了是某个参数错了,然后感觉好开心,好激动。所以呢这个是纯技术方面的,这个时候要注意你的思路。
然后我们还要注意一个词叫影响力,比如在gitHub上拥有一个star很多的项目,在某个博客上有很多技术文章,记录自己做开发以来遇到的bug以及解决方式,还有自己对很多新技术的分析与学习笔记等。这个算是一张个人名片了,有时候甚至要比学历管用。