
[ACM MM 2023] 基于残差扩散模型的文档增强

本文简要介绍被ACM MM 2023录用的论文《DocDiff: Document Enhancement via Residual Diffusion Models》。本文注意到基于回归的文档图像增强方法易受“回归至均值”问题影响[1],导致生成的文本边缘模糊。同时,直接应用面向自然图像的扩散模型进行文档增强也面临训练代价高、采样步数长等困难。基于这些观察,本文重点关注文档图像增强的三大任务:文档去模糊、文档去噪与二值化以及水印与印章的去除,并提出DocDiff,首个应用扩散模型进行文档增强的模型,并引入高频残差精炼模块(High-Frequency Residual Refinement module,HRR)以及频率分离训练机制,在保持字符一致性的同时提升文档图像的可读性与OCR识别性能。实验表明:本文方法可以在不同文档增强任务上取得竞争性甚至SOTA的性能,同时也展现出了较强的推广性和鲁棒性。在模型参数上,基础版本的DocDiff仅有8M,在128*128分辨率上以Batchsize=64训练只需要12GB显存。如图1所示,提出的HRR模块是可插拔的,并且可以在不与Baseline模型进行任何联合训练的基础上,直接串联推理来大幅锐化Baseline生成的文本边缘。并且,DocDiff仅需要采样5步就可以得到较好的效果。总体而言,本文设计了一个基于扩散模型的小巧高效的框架用于文档增强,平衡了创新性和实用性。代码及数据集已开源:https://github.com/Royalvice/DocDiff
 图1 DocDiff效果图。与DE-GAN [1]和HINet [2]相比,DocDiff生成更清晰的文本边缘。我们提出的HRR模块能够有效缓解基于回归的方法生成的失真和模糊字符的问题,无论这些方法是设计用于自然场景还是文档场景。需要注意的是,HRR模块不需要与DE-GAN 和HINet进行额外的联合训练,其权重是从预训练的DocDiff中得出的。DocDiff-n代表推理时进行n次采样。
图1 DocDiff效果图。与DE-GAN [1]和HINet [2]相比,DocDiff生成更清晰的文本边缘。我们提出的HRR模块能够有效缓解基于回归的方法生成的失真和模糊字符的问题,无论这些方法是设计用于自然场景还是文档场景。需要注意的是,HRR模块不需要与DE-GAN 和HINet进行额外的联合训练,其权重是从预训练的DocDiff中得出的。DocDiff-n代表推理时进行n次采样。
一.研究背景

-
文档图像中存在的多种噪声类型,包括整体的模糊以及局部的墨迹、透印等,以及它们的各种组合,对去噪提出了挑战。 -
文本像素生成是一个困难的任务。与自然场景图像不同,文本图像的高频信息主要集中在文字边缘。对文本边缘像素的轻微错误修改都可能改变字符的语义含义,使其对OCR系统不可读或不可识别。 -
实际文档图像分辨率往往超过1k,为保证整个文档分析系统的效率,图像增强预处理的速度至关重要,这要求模型尽可能轻量化。
当前,文档增强方法主要基于深度学习中的回归框架[2,4,5],直接优化像素级别的损失函数。由于“回归至均值”的问题,这些方法生成的图像文字边缘存在模糊失真的问题,如图1所示。此外,由于高分辨率文档图像中存在大量非文本区域,基于GAN的方法容易在局部Patch上出现模式坍塌[2]。近年来,许多基于扩散模型的方法试图为自然图像恢复更丰富的细节。但是,直接将这些方法应用于文档图像存在一定困难:训练成本过高,采样步数过长使其难以在文档分析系统中实际应用;生成多样性可能导致条件图像与采样图像之间的字符不一致。文档增强任务不追求生成多样性,基于此我们可以对网络结构进行压缩,对优化目标进行改进。
二、方法概述
 图3 DocDiff结构图
图3 DocDiff结构图
如图3所示,DocDiff由两个模块组成:粗预测器(Coarse Predictor, CP)和高频残差精炼(High-Frequency Residual Refinement, HRR)模块。
粗预测器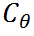 的目标是在像素级别粗略恢复退化文档图像y为其干净版本
的目标是在像素级别粗略恢复退化文档图像y为其干净版本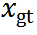 。其优化目标为最小化预测
。其优化目标为最小化预测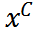 与GT 的均方误差:
与GT 的均方误差:

在文本像素生成中,粗预测器可以有效恢复文本的主要内容,但可能无法准确捕捉文字边缘的高频信息,导致文本边缘明显模糊。这是基于CNN的回归方法由于“回归至均值”问题的普遍局限,仅叠加更多卷积层难以解决此问题。
为解决上述问题,我们引入了高频残差精炼(HRR)模块,它能从可学习的后验分布中生成样本。HRR模块的核心是一个Denoiser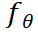 ,利用扩散概率模型(DPM)[6,7]来估计Ground-truth图像与CP生成图像之间的残差分布。与之前的工作[8-10]不同,我们设计HRR模块不仅可以弥补单个回归模型(此处为CP)的“回归至均值”缺陷,还可以普适地增强各类基于回归的方法的生成效果,不需要联合训练。为此,我们对CP与HRR模块进行端到端联合训练,而不是分别训练。通过这种方式,HRR模块可以动态调整并捕捉更多模式。大量实验表明,这种训练策略可以在不存在任何额外联合训练的情况下,直接且显著增强不同回归去模糊方法生成的文字边缘清晰度。
,利用扩散概率模型(DPM)[6,7]来估计Ground-truth图像与CP生成图像之间的残差分布。与之前的工作[8-10]不同,我们设计HRR模块不仅可以弥补单个回归模型(此处为CP)的“回归至均值”缺陷,还可以普适地增强各类基于回归的方法的生成效果,不需要联合训练。为此,我们对CP与HRR模块进行端到端联合训练,而不是分别训练。通过这种方式,HRR模块可以动态调整并捕捉更多模式。大量实验表明,这种训练策略可以在不存在任何额外联合训练的情况下,直接且显著增强不同回归去模糊方法生成的文字边缘清晰度。
HRR模块执行正向加噪过程和反向去噪过程来建模残差分布,参考[6,7]。
正向加噪过程:给定干净文档图像和其粗略估计,计算它们的残差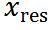 。将
。将 设为
设为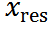 ,然后依次引入基于时间步长t的高斯噪声,如下:
,然后依次引入基于时间步长t的高斯噪声,如下:
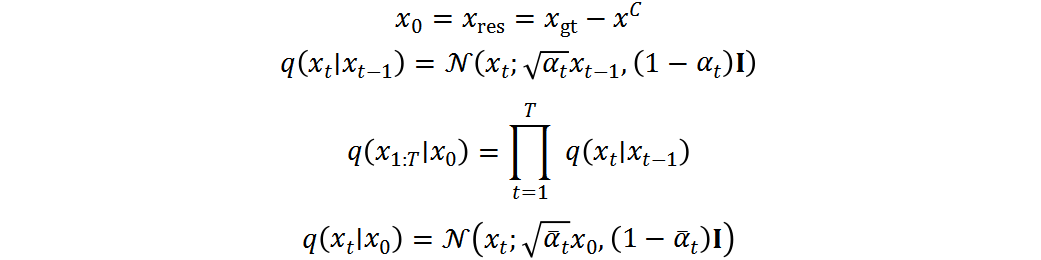
其中,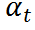 是控制每步添加高斯噪声方差的超参数。正向过程中没有可学习的参数,生成的
是控制每步添加高斯噪声方差的超参数。正向过程中没有可学习的参数,生成的 与大小相同。通过重参数技巧,可以将
与大小相同。通过重参数技巧,可以将 写为:
写为:
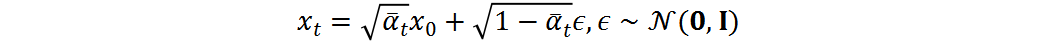
反向去噪过程:反向过程将高斯噪声转化回残差分布,在给定条件下进行。反向扩散步骤可以写为:
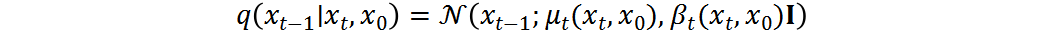
其中, 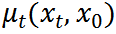 和
和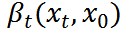 分别是均值和方差。参考[7],我们执行确定性反向过程
分别是均值和方差。参考[7],我们执行确定性反向过程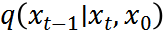 ,方差为零,均值可计算为:
,方差为零,均值可计算为:

给定Denoiser ,可参数化后验分布 :
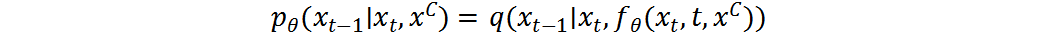
条件在条件分布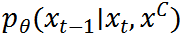 中非常重要。在每个时间步,需要采样与在像素级字符上高度相关的残差。
中非常重要。在每个时间步,需要采样与在像素级字符上高度相关的残差。
可以训练Denoiser 来预测原数据或者添加的噪声 。为增加生成图像的多样性,现有方法[6,11-13]通常预测添加的噪声。与的预测在无条件生成中是等价的,可以通过等式相互转化。但是,在条件生成中,在采用Concat的条件输入方式[11-13]的前提下,预测与预测是不等价的。预测时,Denoiser只能从噪声数据中学习;而预测时,还可以利用条件进行监督,这牺牲了多样性但可以显著提升反向过程前几步的生成质量。为此,我们训练Denoiser 直接预测,这更符合文档增强的目标。训练目标是最小化与真实后验分布之间的距离:
。为增加生成图像的多样性,现有方法[6,11-13]通常预测添加的噪声。与的预测在无条件生成中是等价的,可以通过等式相互转化。但是,在条件生成中,在采用Concat的条件输入方式[11-13]的前提下,预测与预测是不等价的。预测时,Denoiser只能从噪声数据中学习;而预测时,还可以利用条件进行监督,这牺牲了多样性但可以显著提升反向过程前几步的生成质量。为此,我们训练Denoiser 直接预测,这更符合文档增强的目标。训练目标是最小化与真实后验分布之间的距离:

其中,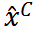 是在内存中的克隆,不参与梯度计算。损失仅从通过反向传播至
是在内存中的克隆,不参与梯度计算。损失仅从通过反向传播至 。
。
给定训练好的和,整合上式可得到确定性反向过程:
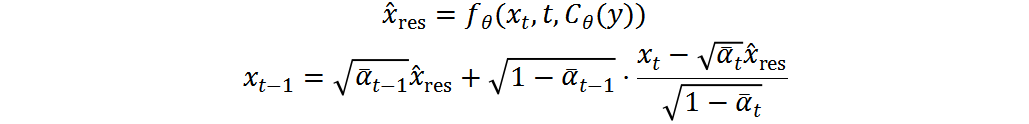
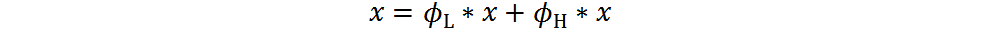
其中, 是低通滤波器,
是低通滤波器,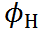 是高通滤波器。通常,为提取文字边缘的残差,我们将设置为拉普拉斯核。根据上式可得到低频信息。与[10,14]不同,我们的方法不需要执行FFT,也不需要在频域参数化频率分离,直接使用拉普拉斯核作为高通滤波器不仅简化了训练时间,也证明了非常有效。
是高通滤波器。通常,为提取文字边缘的残差,我们将设置为拉普拉斯核。根据上式可得到低频信息。与[10,14]不同,我们的方法不需要执行FFT,也不需要在频域参数化频率分离,直接使用拉普拉斯核作为高通滤波器不仅简化了训练时间,也证明了非常有效。
我们的目标是最大化Denoiser 恢复CP预测中缺失的高频信息的能力,同时通过的支持最小化的任务负担。从这个角度看,和都需要恢复不同的高低频信息,但它们展现了不同的专长。具体来说,主要重建低频信息,而专门恢复高频细节:
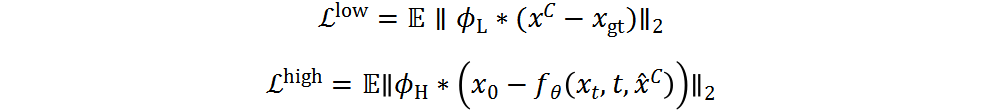
因此,和的综合损失,以及DocDiff的总体损失为:

算法流程如下图4

三、实验结果
论文在多个文档增强数据集上进行了全面评估。
在文档去模糊任务上,论文在文档去模糊数据集上报告定量和定性结果。定量结果显示,DocDiff取得了最佳的感知指标和优秀的的失真指标,明显优于当前最先进的面向自然场景和文档场景的基于回归方法。即使在非原始分辨率下,DocDiff只需要5步采样也能达到竞争性的性能。定性结果也证明相比其他方法,DocDiff能够更清晰准确地恢复文字边缘。
在文档去噪与二值化任务上,论文在H-DIBCO'18和DIBCO'19两个数据集上进行评估。尽管在H-DIBCO'18上没有取得最佳,但F-Measure比SOTA方法DE-GAN提升了10.52%。而在DIBCO'19上,DocDiff的F-Measure比当前最好的方法提升了5.75%,参数量只有对方的1/23。定性结果也证明DocDiff能更准确地分类文本像素。
在水印与印章去除任务上,由于缺乏公开数据集,论文合成了含水印和印章的文档图像进行训练和测试。结果表明DocDiff可以高效去除水印与印章,同时保留覆盖的字符内容。尤其是在真实发票场景中,仅在合成印章数据上训练的DocDiff模型也展现出很强的泛化能力。
论文还使用Tesseract OCR对增强前后的文档图像进行了识别评估。结果证明文档增强可以显著降低OCR的字符错误率。
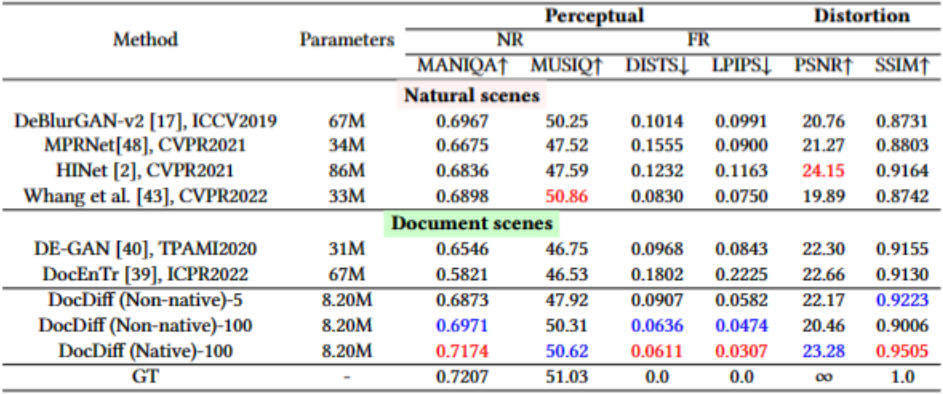
 图5 文档去模糊结果
图5 文档去模糊结果
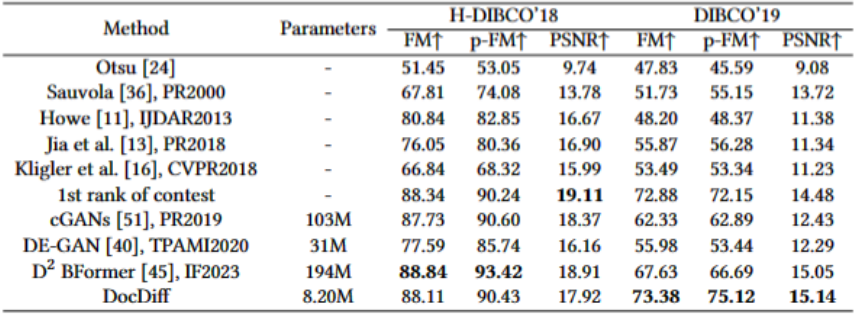


 图8 OCR识别结果
图8 OCR识别结果
四、总结
本文针对当前基于回归的文档图像增强方法易造成文本边缘模糊,以及直接应用面向自然图像的扩散模型存在困难的问题,提出了名为DocDiff的新颖高效框架。主要结论和贡献总结如下:
DocDiff是第一个专门设计用于各种文档图像增强任务的基于残差扩散模型的框架。
插即用的高频残差精炼模块可以直接增强各类基于回归方法重建的文字边缘质量,无需额外的联合训练。这具有很好的普适性。
DocDiff是一个小巧、灵活、高效且训练稳定的生成模型。实验验证其只需要5步采样就能达到竞争性的性能。
-
实验结果全面证明了DocDiff在文档去模糊、去噪与二值化以及水印和印章去除任务上的有效性和泛化性。
五、相关资源
https://zhuanlan.zhihu.com/p/654282220?utm_psn=1702345120874299392
参考文献
[1]Anvari Z, Athitsos V. A survey on deep learning based document image enhancement[J]. arXiv preprint arXiv:2112.02719, 2021.
[2]Souibgui M A, Kessentini Y. De-gan: A conditional generative adversarial network for document enhancement[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 44(3): 1180-1191.
[3]Chen L, Lu X, Zhang J, et al. Hinet: Half instance normalization network for image restoration[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 182-192.
[4]Souibgui M A, Biswas S, Jemni S K, et al. DocEnTr: An end-to-end document image enhancement transformer[C]//2022 26th International Conference on Pattern Recognition (ICPR). IEEE, 2022: 1699-1705.
[5]Jemni S K, Souibgui M A, Kessentini Y, et al. Enhance to read better: a multi-task adversarial network for handwritten document image enhancement[J]. Pattern Recognition, 2022, 123: 108370.
[6]Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in neural information processing systems, 2020, 33: 6840-6851.
[7]Song J, Meng C, Ermon S. Denoising diffusion implicit models[J]. arXiv preprint arXiv:2010.02502, 2020.
[8]Li H, Yang Y, Chang M, et al. Srdiff: Single image super-resolution with diffusion probabilistic models[J]. Neurocomputing, 2022, 479: 47-59.
[9]Niu A, Zhang K, Pham T X, et al. CDPMSR: Conditional Diffusion Probabilistic Models for Single Image Super-Resolution[J]. arXiv preprint arXiv:2302.12831, 2023.
[10]Shang S, Shan Z, Liu G, et al. Resdiff: Combining cnn and diffusion model for image super-resolution[J]. arXiv preprint arXiv:2303.08714, 2023.
[11]Whang J, Delbracio M, Talebi H, et al. Deblurring via stochastic refinement[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 16293-16303.
[12]Saharia C, Chan W, Chang H, et al. Palette: Image-to-image diffusion models[C]//ACM SIGGRAPH 2022 Conference Proceedings. 2022: 1-10.
[13]Saharia C, Ho J, Chan W, et al. Image super-resolution via iterative refinement[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(4): 4713-4726.
[14]Wu J, Fang H, Zhang Y, et al. Medsegdiff: Medical image segmentation with diffusion probabilistic model[J]. arXiv preprint arXiv:2211.00611, 2022.
原文作者: Zongyuan Yang, Baolin Liu, Yongping Xiong, Lan Yi, Guibin Wu, Xiaojun Tang, Ziqi Liu, Junjie Zhou, Xing Zhang
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。