
文生图prompt不再又臭又长!LLM增强扩散模型,简单句就能生成高质量图像|ACM MM'23

新智元报道
新智元报道
【新智元导读】参数高效的微调方法SUR-adapter,可以增强text-to-image扩散模型理解关键词的能力。


背景介绍


方法概述
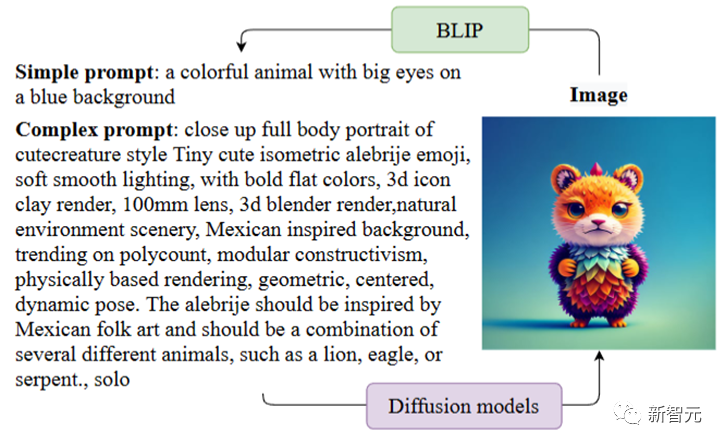
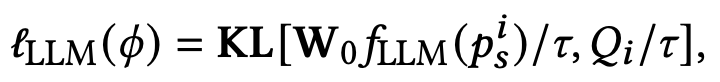
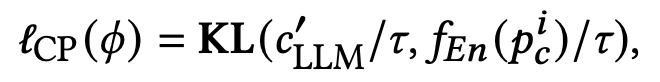
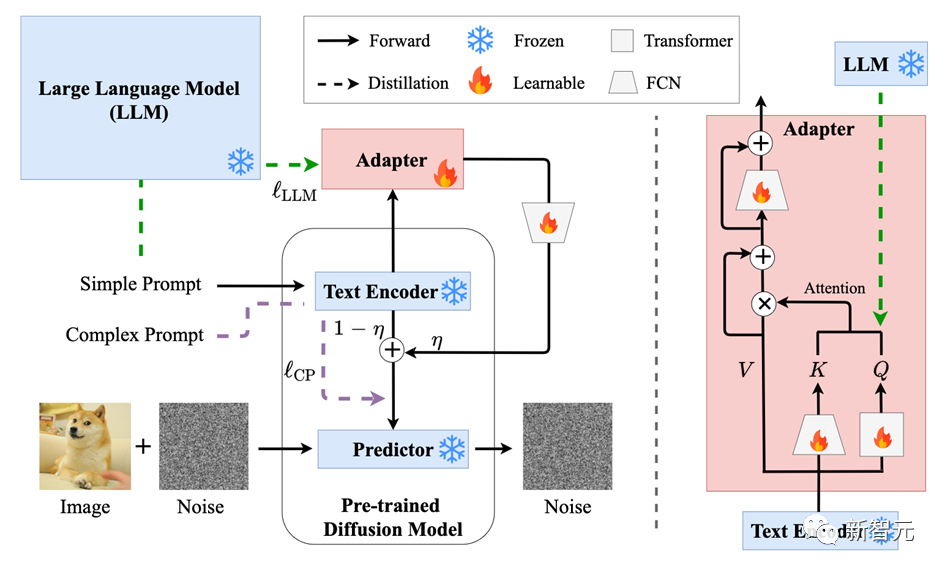
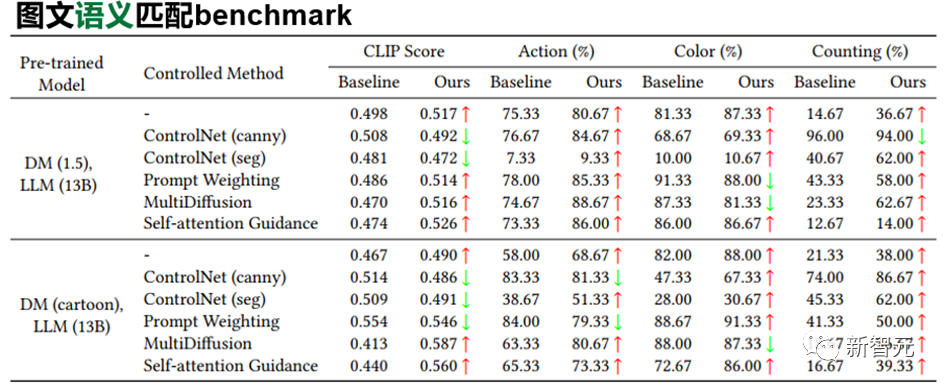
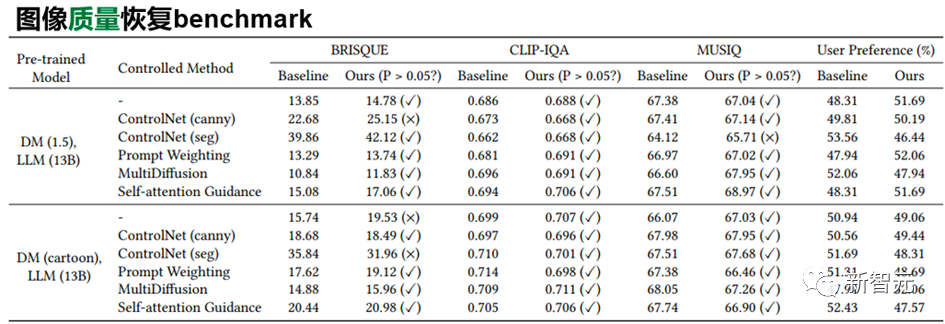
实验结果


中山大学人机物智能融合实验室 (HCP Lab) 由林倞教授于 2010 年创办,近年来在多模态内容理解、因果及认知推理、具身智能等方面取得丰富学术成果,数次获得国内外科技奖项及最佳论文奖,并致力于打造产品级的AI技术及平台。



评论