
人脸随意编辑!Adobe祭出新一代GAN神器:最多支持35个人脸属性变化
新智元报道
新智元报道
编辑:LRS
【新智元导读】用GAN模型进行图像合成有一个显著缺点,就是生成的图像不可控制,经常是摘个眼睛把性别都变了。最近Adobe提出新一代GAN模型,能够自由控制35个人脸属性的变化,而不会互相干扰。
图像合成中的一个重要问题就是图像内的纠缠(entanglement)问题。
比如把一个人脸上的胡子全都自动去掉,或者完美地贴上胡子,最后生成的图片或多或少都有违和感,因为胡子和人脸存在某种纠缠的关系。

并且不同物体间的合成、去除的难度也不尽相同。
举几个生活中的例子就很好理解了,从牛肉面里挑出来香菜,和挑牛肉出来的难度相差很大;想从咖啡里面把糖都挑出来,那就简直是不可能完成的任务了。

有些东西天生就是捆绑在一起的,想要完美的新建、合成一张新图像,机器学习模型必须能够学会创建各种各样的物体,并且最好能够分离出不同的特征和概念。
如果模型能把年龄、性别、头发颜色、肤色、情绪等分出来,那你就可以在一个框架中随意修改这些组件,更加灵活地控制生成图像,在更加细化的水平上创建和编辑人脸等图像,能够完美避开图像的纠缠关系。

在所有实体最大纠缠的情况下,图像实际上进行的就是分类任务,例如模型识别出是Lady Gaga的一张照片。
中等纠缠情况下,模型可以进一步分解照片,发现她是金头发、微笑的表情等等,GAN模型就可以根据这些信息进行修改,并生成新图像。
完全解纠缠的状态下,模型能够进一步识别出特征,比如年龄,微笑程度等等。

在过去的几年中,已经有很多人尝试创建交互式脸部编辑模型,用户可以通过滑块或者其他传统的用户界面交互来改变图片的脸部特征,并且在进行添加或改变面部特征时保持目标人脸的核心特征不变。
然而,由于GAN潜空间中的潜特征和风格纠缠现象,所以想要任意编辑人脸特征,技术还不成熟。
例如,眼镜特征经常与老年人的特征纠缠在一起,这意味着增加眼镜可能也会使脸部「老化」,而想要让脸部老化,可能也会为面部增加一个眼镜,具体取决于高层特征的应用分离程度。
最难的是改变头发的颜色和发型,几乎不可能在不重新计算发丝和面部布局的情况下给人物「理发」。

一次训练,随意换脸
一次训练,随意换脸
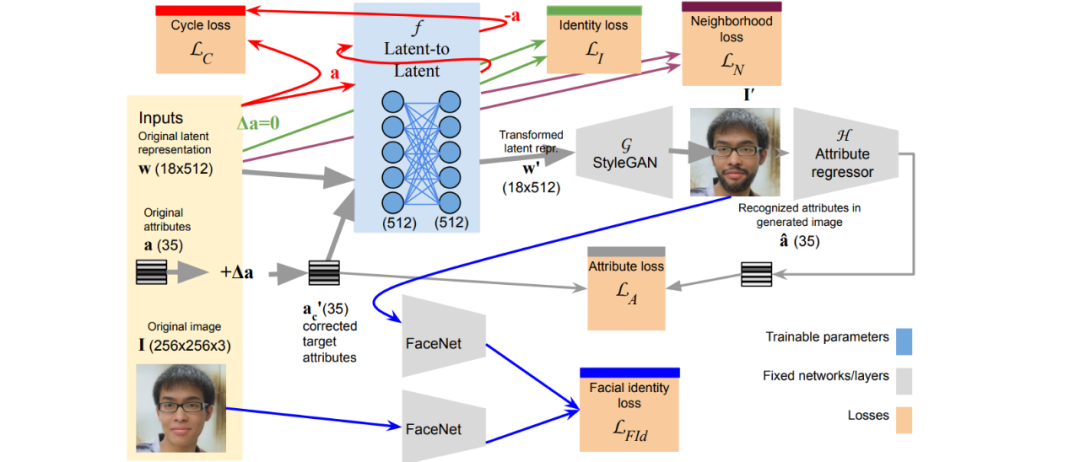
最近,Adobe在WACV2022会议上发表了一篇新论文,提供了一个解决这些基本问题的新方法。在StyleGAN生成的图像中,用于保护身份的多重面部属性编辑的学习映射器。

论文地址:
https://openaccess.thecvf.com/content/WACV2022/papers/Khodadadeh_Latent_to_Latent_A_Learned_Mapper_for_Identity_Preserving_Editing_WACV_2022_paper.pdf
论文的主要作者是Adobe的应用科学家Siavash Khodadadeh,同时还有其他四位Adobe研究人员,以及中佛罗里达大学计算机科学系的一位研究人员。

这篇论文很有意思,部分原因是Adobe已经在图像合成领域研发了一段时间,而且和Adobe公司的产品很契合,这种功能在未来几年内很有可能包装进Adobe Creative Suite项目;但主要还是因为为这个项目提出的架构采取了不同的方法,在应用变化的同时保持GAN面部编辑器的视觉完整性。
作者宣称他们训练一个神经网络来执行潜意识到潜意识的转换,找到与属性改变的图像相对应的潜编码。由于该技术是one-shot的,它不依赖于属性逐渐变化的线性或非线性轨迹。
通过在整个生成pipeline上端对端训练网络,该系统可以适应现有的生成器架构的潜空间,并能够保护属性(Conservation properties),如人的身份特征可以在训练损失中进行编码。
一旦latent-to-latent网络训练完,就可以用于任意的图像输入,而不需要微调。

这个特性也意味着文中提出的架构可以把模型一次性部署到用户终端,但它仍然需要本地资源运行一个神经网络,但新的图像可以直接丢到模型里去,并可以随意变化。因为框架是解耦的,也不需要进一步的特定图像训练。
这项工作的主要成果之一就是网络可以通过只改变目标向量中的属性来「冻结」潜空间中的身份特征。
从本质上讲,网络被嵌入到一个更通用的架构中,可以协调所有的处理元素,这些元素通过预先训练好的具有冻结权重的组件,不会对转换产生不必要的横向影响。
由于训练过程依赖于可以由种子图像(GAN inversion)或现有的初始潜编码产生的triplets,所以整个训练过程是无监督的,这类系统中习惯性的一系列标签和curation系统的能够得到有效处理。系统中使用的是现成的属性回归器(attribute regressors)。

作者在文中表示,该网络能够独立控制的属性数量只受到识别器能力的限制,如果你有一个属性的识别器,就可以把它添加到任意的面孔上。在文中实验,研究人员直接训练了一个能调整35个不同的面部属性的latent-to-latent网络,比以前的任何方法都要多。
该系统还纳入了一个额外的保障措施,以防止不想要的「副作用」转换:在没有要求改变属性的情况下,latent-to-latent网络会将一个latent向量映射到自己身上,进一步增加目标身份的稳定持久性。
在过去几年里,基于GAN和编码器/解码器的人脸编辑器的l另一个反复出现的问题是,使用的变换方法往往会降低脸部相似度。
为了解决这个问题,Adobe项目使用了一个名为FaceNet的嵌入式面部识别网络作为判别器,可以将标准的面部识别甚至表情识别系统整合到生成网络中。
该框架的另一个主要特点是能够在潜空间任意转换。通过提高GAN的空间意识,可以在潜过渡点范围内(range of potential transition points)进行图像修改,但如EQGAN等模型在面对不同材质、纹理的修改时,都需要重新训练模型。

除了可以接受全新的用户图像外,用户还可以手动「冻结」他们希望在转换过程中保留的元素。通过这种方式,用户可以确保背景等无关因素不发生变化、
属性回归网络由三个网络组成:FFHQ、CelebAMask-HQ和一个由StyleGAN-V2的Z空间采样40万个向量而产生的局部GAN网络。
分布外(Out-of-distribution, OOD)的图像被过滤掉,并使用微软的人脸API提取属性,所得的图像集被分成90/10,剩下72万张训练图像和7.2万张测试图像进行对比。

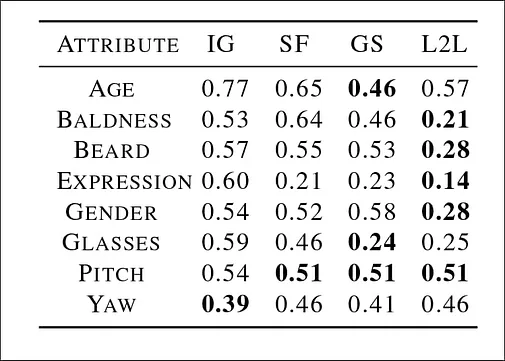
实验网络的初始配置可以容纳35个潜变换的方式,但为了对类似的框架InterFaceGAN、GANSpace和StyleFlow进行类似的测试,转换数简化为8个,分别为年龄、秃头、胡须、表情、性别、眼镜、音高和偏角(Yaw).
实验结果和预期相符,在其他竞争的模型架构中,图像合成的结果出现了更大程度的纠缠。例如,在一个测试中,当用户要求改变人物年龄时,InterFaceGAN和StyleFlow甚至把主体的性别都给变了。
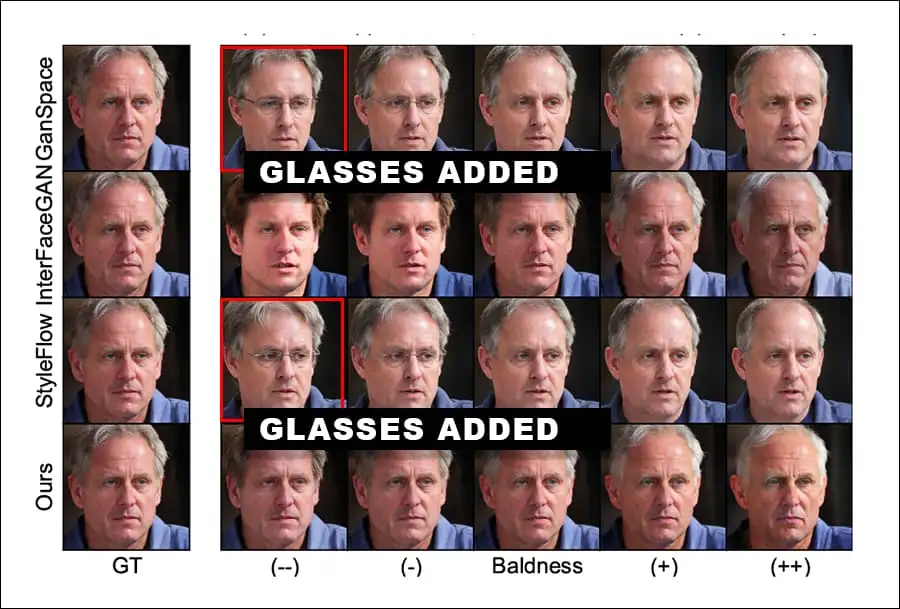
最后量化的实验结果中可以看到,除了在Yaw(头部角度)的实验中,Latent-to-Latent的效果并不理想,其余七个属性的性能基本都处于sota序列。而GANSpace对于年龄和眼镜变化的效果则更优。
参考资料:
https://www.unite.ai/adobe-research-extends-disentangled-gan-face-editing/
