
CV(目标检测)中的IOU计算,附代码
1. 目标检测中的IOU
假设,我们有两个框,与,我们要计算其。其中的计算公式为,其交叉面积除以其并集。
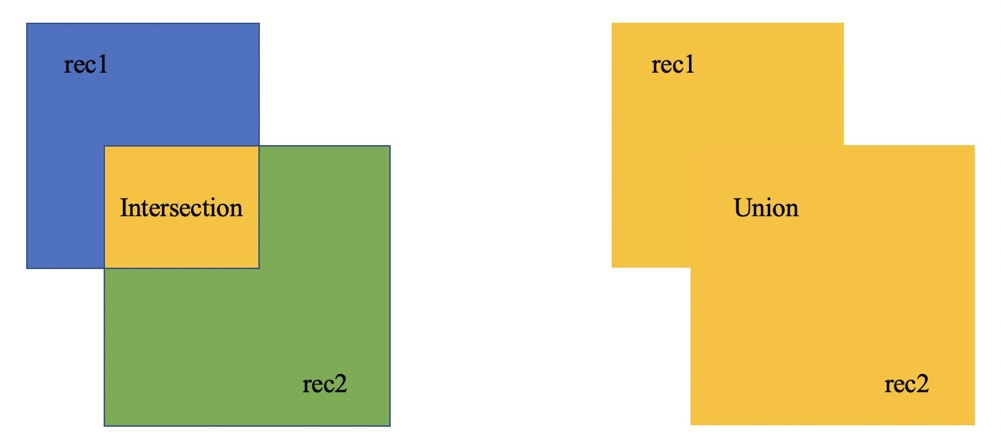
的数学公式为:
上代码:
def compute_iou(rec1, rec2):
"""
computing IoU
param rec1: (y0, x0, y1, x1) , which reflects (top, left, bottom, right)
param rec2: (y0, x0, y1, x1) , which reflects (top, left, bottom, right)
return : scale value of IoU
"""
S_rec1 =(rec1[2] -rec1[0]) *(rec1[3] -rec1[1])
S_rec2 =(rec2[2] -rec2[0]) *(rec2[3] -rec2[1])
#computing the sum area
sum_area =S_rec1 +S_rec2
#find the each edge of interest rectangle
left_line =max(rec1[1], rec2[1])
right_line =min(rec1[3], rec2[3])
top_line =max(rec1[0], rec2[0])
bottom_line =min(rec1[2], rec2[2])
#judge if there is an intersect
if left_line >=right_line or top_line >=bottom_line:
return 0
else:
intersect =(right_line -left_line) *(bottom_line -top_line)
return intersect /(sum_area -intersect)
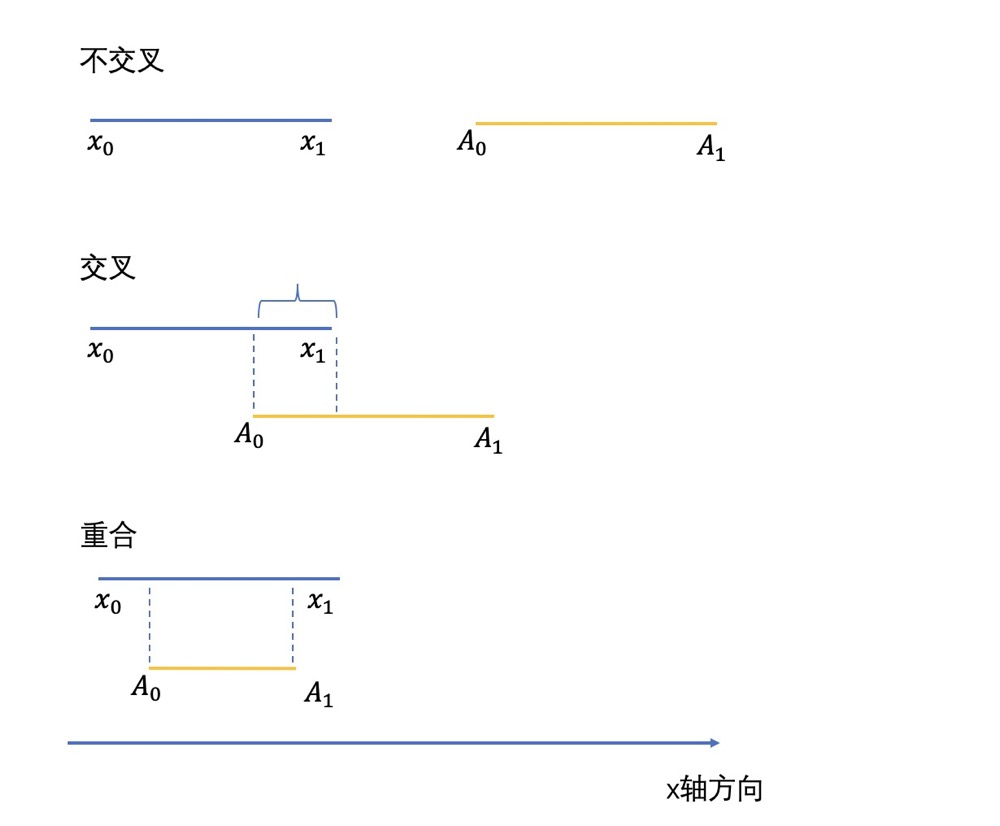
这里我们主要讨论下这个判断,我们以横轴方向为例,其中对纵轴方向是一样的,我们来判断两个框重合与否。其中为左上角的坐标,是右下角的坐标。为的左上角坐标,是的右下角坐标。
2. 语义分割中的IOU
先回顾下一些基础知识:
常常将预测出来的结果分为四个部分: , , , ,其中就是指非物体标签的部分(可以直接理解为背景),positive$就是指有标签的部分。下图显示了四个部分的区别:

图被分成四个部分,其中大块的白色斜线标记的是 (TN,预测中真实的背景部分),红色线部分标记是 (,预测中被预测为背景,但实际上并不是背景的部分),蓝色的斜线是 (,预测中分割为某标签的部分,但是实际上并不是该标签所属的部分),中间荧光黄色块就是 (,预测的某标签部分,符合真值)。
同样的,计算公式:

def compute_ious(pred, label, classes):
'''computes iou for one ground truth mask and predicted mask'''
ious = [] # 记录每一类的iou
for c in classes:
label_c = (label == c) # label_c为true/false矩阵
pred_c = (pred == c)
intersection = np.logical_and(pred_c, label_c).sum()
union = np.logical_or(pred_c, label_c).sum()
if union == 0:
ious.append(float('nan'))
else
ious.append(intersection / union)
return np.nanmean(ious) #返回当前图片里所有类的mean iou
其中,对于与有多种形式。
如识别目标为4类,那么的形式可以是一张图片对应一份,其中 为背景,我们省略,则可以为。也可以是对应四份二进制 , 这四层的取值为。为了。
总结
对于目标检测,写那就是必考题,但是我们也要回顾下图像分割的怎么计算的。
引用
https://blog.csdn.net/weixin_42135399/article/details/101025941 https://blog.csdn.net/lingzhou33/article/details/87901365 https://blog.csdn.net/lingzhou33/article/details/87901365
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!
评论