
【CV】一文读懂目标检测

编者荐语
目标检测(Object Detection)是计算机视觉(Computer Vision,CV)领域的一个热门方向,广泛应用于自动驾驶,工业检测,视频监控及航空航天等领域,其基本流程是在给定图像中找到关注目标,确定目标类别并输出相应的坐标位置(常使用矩形框)。
图像分类、目标检测、分割是计算机视觉领域的三大任务:
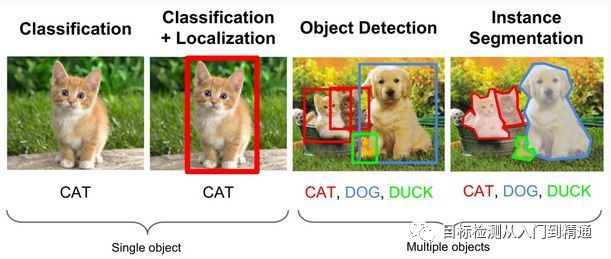 图像理解的三个层次
图像理解的三个层次
1.分类(Classification),对输入的图像进行描述,从已有的类标签集合中找出最符合的标签分配给该图像。分类虽然是最简单、最基础的图像理解任务,但却为其他复杂任务奠定了基础。
2.检测(Detection),相对于分类任务关心整体,给出整幅图像的内容描述,检测更加关注目标,需要同时获得目标的类别及位置信息(Classification+Localization)。
3.分割(Segmentation),分割包括语义分割(Semantic Segmentation)和实例分割(Instance Segmentation),前者是对前背景分离任务的拓展,要求将图中每一点像素标注为某个物体类别,同一物体的不同实例不需要单独分割; 而后者是检测任务的拓展,是目标检测+语义分割的综合体,要求精确到物体的边缘(相比目标识别框更为精细),相比语义分割,实例分割可以标注出图像中的不同个体。

语义分割与实例分割对比
图像分类是将图像划分为单个类别(一般对应特征最为明显的物体),但现实世界中的大部分图像通常包含不只一个物体,如果强行使用分类模型进行分类,得到的结果也并不一定准确。诸如此类的情况,就需要使用目标检测算法,目前学术和工业界主要将目标检测算法分成三类:
1.传统的目标检测框架
(1)候选区域选择(采用不同尺寸、比例的滑动窗口对图像进行遍历);
(2)对不同的候选区域进行特征提取(SIFT、HOG等);
(3)使用分类器进行分类(SVM、Adaboost等)。
2.基于深度学习的Two Stages目标检测框架(准确度有优势)
此类算法将检测问题分为两个阶段,第一阶段生成大量可能含有目标的候选区域(Region Proposal),并附加大概的位置信息;第二个阶段对其进行分类,选出包含目标的候选区域并对其位置进行修正(常使用R-CNN、Fast R-CNN、Faster R-CNN等算法)。
3.基于深度学习的One Stage目标检测框架(速度有优势)
此类检测算法属于端到端(End-to-End),不需要生成大量候选区域的阶段,而是将问题转化为回归(Regression)问题处理,使用完整图像作为输入,直接在图像的多个位置上回归出该位置的目标边框及所属类别(常使用Yolo、SSD、CornerNet等算法)。
总结
未来的工作主要集中在速度与准确度的博弈之中。
各种目标检测算法的详细介绍请参考公众号的其他文章。
—THE END—
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: