
图解机器学习:演化史、方法、应用场景与发展趋势
来源:机器学习杂货店
本文约5000字,建议阅读10分钟
本文通过图示将机器学习的发展历史、关键方法以及未来会如何影响社会生活展现了出来。
[ 导读 ] 本文通过一系列机器学习信息图示,很好地将机器学习的发展历史、关键方法以及未来会如何影响社会生活展现了出来。
基础概念部分包括机器学习各大学派错综关系的梳理;应用部分则描述了机器学习在社会中作用。文中的信息图非常专业,是值得珍藏的材料。我们在此基础上进行了解说。希望这篇文章能对你有所帮助,让你在学习和应用AI技术的道路上更进一步!
前言
AI 如何能成为商业的主流?这需要不同研究方法的结合,以及大量人类的智慧。
我们正处在 AI 取得突破性进展的时代:更为复杂的神经网络伴着有效的语音识别训练数据将亚马逊的 Echo 和谷歌的 Home 带进了千家万户。深度学习在图像、语音和其他模式识别中取得的准确度提升使得微软和谷歌的机器翻译被更多人使用。图像识别的增强使 Facebook 的照片搜索和谷歌照片中的 AI 相关功能得以实现。总体来说,这些进展使得机器识别的能力在很大程度上可以被消费者使用了。
在商业上,如何取得相似的进展?这需要高质量的训练数据、数字化数据处理和数据科学家,同时需要大量的人类智慧,比如请语言领域的专家来调整、精修可计算的、逻辑贯通的商业语境,以使得计算机实现在商业领域的逻辑推理。商业领袖们也要花时间来教导机器将其智能融入具体领域内的处理进程。
一些以统计学为导向的机器学习研究流派,比如联结学派、贝叶斯学派和类推学派,会担心符号学派推动的 “human-in-the-loop” 方法无法扩展。但是,我们期待这一融合了几种流派的、人类和机器间相互反馈的环,在接下来的几年中,会在企业内部变得更为常见。
机器学习概览

1. 什么是机器学习?
机器通过分析大量数据来进行学习。比如说,不需要通过编程来识别猫或人脸,它们可以通过使用图片来进行训练,从而归纳和识别特定的目标。
2. 机器学习和人工智能的关系
机器学习是一种重在寻找数据中的模式并使用这些模式来做出预测的研究和算法的门类。机器学习是人工智能领域的一部分,并且和知识发现与数据挖掘有所交集。
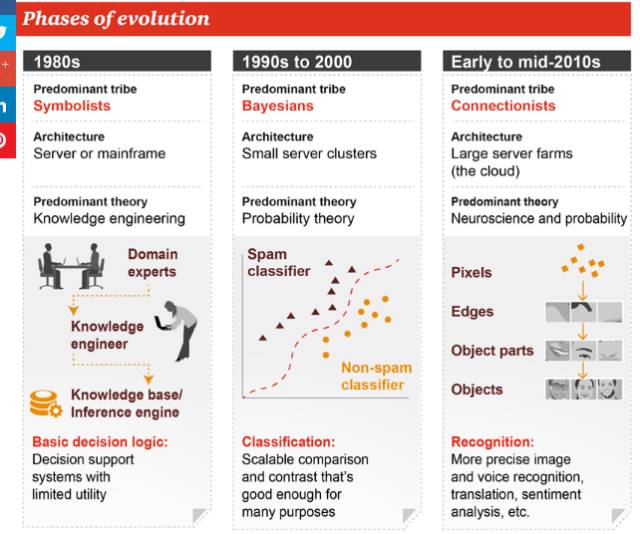
机器学习演化史:各学派发展融合,最终让自动机器成为可能
长久以来,各种派别的人工智能研究者总是在相互竞争。相互合作的时机到来了吗?他们不得不握手言和,因为只有合作将算法整合才能实现真正的通用人工智能(AGI)。下面,我们就来看看机器学习方法走过了什么样的历程,未来又将如何?

-
符号学派(Symbolists):是使用基于规则的符号系统做推理的人。大部分AI都围绕着这种方法。使用Lisp和Prolog的方法属于这一派,使用SemanticWeb,RDF和OWL的方法也属于这一派。其中一个最雄心勃勃的尝试是Doug Lenat在80年代开发的Cyc,试图用逻辑规则将我们对这个世界的理解编码。这种方法主要的缺陷在于其脆弱性,因为在边缘情况下,一个僵化的知识库似乎总是不适用。但在现实中存在这种模糊性和不确定性是不可避免的。爱用方法:规则和决策树
-
贝叶斯学派(Bayesians):是使用概率规则及其依赖关系进行推理的一派。概率图模型(PGM)是这一派通用的方法,主要的计算机制是用于抽样分布的蒙特卡罗方法。这种方法与符号学方法的相似之处在于,可以以某种方式得到对结果的解释。这种方法的另一个优点是存在可以在结果中表示的不确定性的量度。爱用方法:朴素贝叶斯或马尔科夫
-
联结学派(Connectionists):这一派的研究者相信智能起源于高度互联的简单机制。这种方法的第一个具体形式是出现于1959年的感知器。自那以后,这种方法消亡又复活了好几次。其最新的形式是深度学习。爱用方法:神经网络
-
进化学派(Evolutionists):是应用进化的过程,例如交叉和突变以达到一种初期的智能行为的一派。在深度学习中,GA确实有被用来替代梯度下降法,所以它不是一种孤立的方法。这个学派的人也研究细胞自动机(cellular automata ),例如Conway的“生命游戏”和复杂自适应系统(GAS)。爱用方法:遗传算法
-
类推学派(The analogizers):更多地关注心理学和数学最优化,通过外推来进行相似性判断。类推学派遵循“最近邻”原理进行研究。各种电子商务网站上的产品推荐(例如亚马逊或 Netflix的电影评级)是类推方法最常见的示例。爱用方法:支持向量机(SVM)
-
上世纪 80 年代流行符号学派,主导方法是知识工程(Knowledge engineering),由某个领域专家制造能够在特定领域发挥一定决策辅助的机器,也即所谓的“专家机”。
-
上世纪 90 年代开始,贝叶斯学派发展了起来,概率论成为当时的主流思想,基于的原理是可以扩展的比较和对比,这种方法能够适用的场景比较多。
-
到上世纪末至今,连接学派掀起热潮,神经科学和概率论的方法得到了广泛应用。神经网络可以更精准地识别图像、语音,做好机器翻译乃至情感分析(sentiment analysis)等任务。同时,由于神经网络需要大量的计算,基础架构也从上世纪 80 年代的服务器便为大规模数据中心或者云。这部分内容相信大家都非常熟悉了。
-
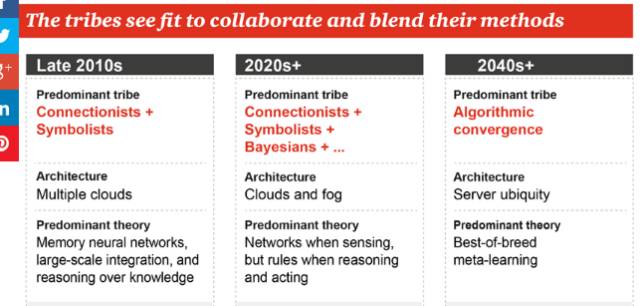
如今,各学派开始相互借鉴融合,21 世纪的头十年,最显著的就是连接学派和符号学派的结合,由此产生了记忆神经网络以及能够根据知识进行简单推理的智能体。基础架构也向大规模云计算转换。
-
第二个十年,连接学派、符号学派和贝叶斯学派也将融合到一起,实际上我们现在已经看到了这样的趋势,比如 DeepMind 的贝叶斯 RNN,而主要的局面将是感知任务由神经网络完成,但涉及到推理和行动还是需要人为编写规则。
-
从 2040 年以后,根据普华永道的预测,主流学派将成为 Algorithmic convergence,也即各种算法融合在一起,届时机器自主学习,也即元学习(Meta-learning)实现,计算服务将无处不在。
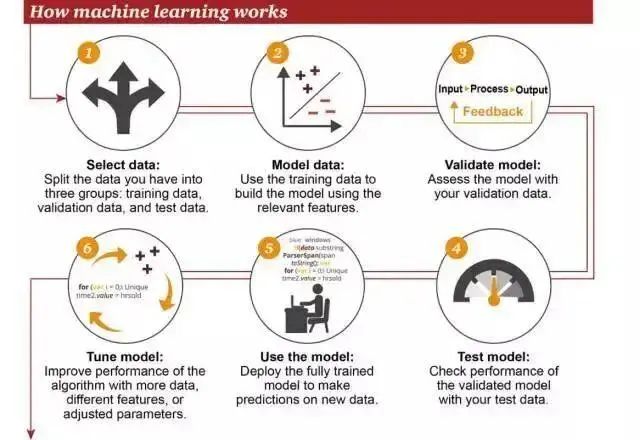
机器学习:工作原理及适用场景
机器学习通过使人类能够“教”机器如何学习,使人类和机器的联系更为紧密。机器通过处理合适的训练集来学习,这些训练集包含优化一个算法所需的各种特征。这个算法使机器能够执行特定的任务,例如对电子邮件进行分类。
但是,其好处远远不止过滤电子邮件,那些十年前就能做到了。如今,在机器学习的助力下,无人机可以实时近距离地拍摄例如桥梁之类的地方,然后快速、准确地评估重建项目的范围。
下面,普华永道的信息图示概述了机器学习的工作原理,机器学习与人工智能的关系,以及企业应该在哪些地方利用它们。

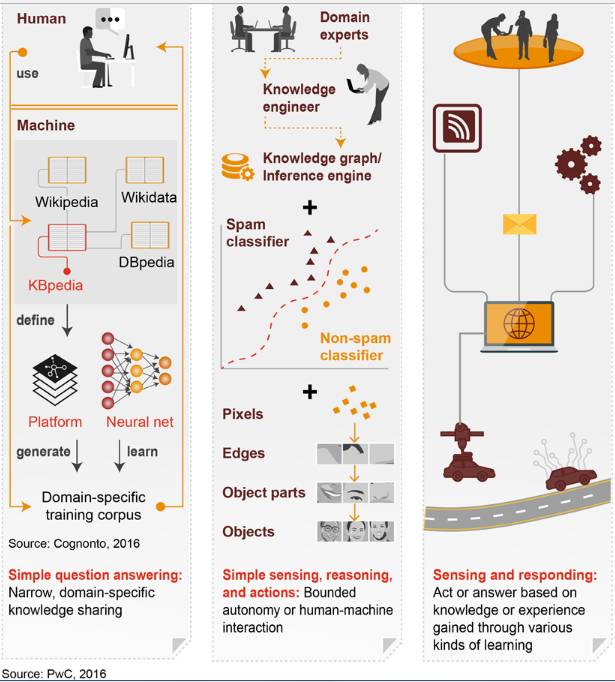
机器学习能够通过“学习”大量的数据,在不需要人为编程的情况下,生成以及识别特定的对象,比如人脸。目前,机器学习也是商业应用中最常用的算法。
那么,机器学习跟人工智能之间具体是怎样的关系呢?
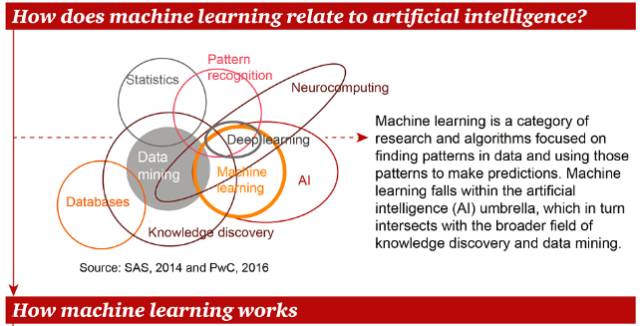
机器学习是一类关注从数据中找到模式,并根据这些模式进行预测的研究和算法。机器学习属于人工智能,它与数据挖掘、统计学、模式识别等相关领域的关系如上图所示。接下来看看机器学习如何工作。
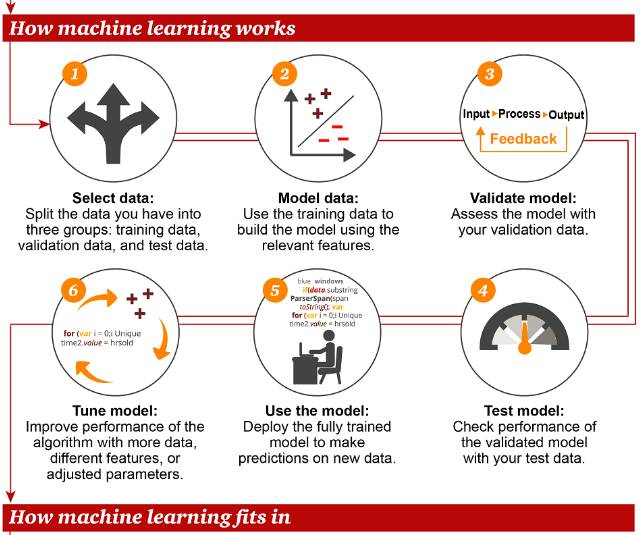
根据普华永道信息图的总结,机器学习的主要流程/步骤:
选择数据:这一过程又分为三部分,分别是训练用数据、验证用数据、测试用数据
数据建模:使用训练数据构建涉及相关特征的模型
验证模型:用验证数据验证建立的模型
调试模型:为了提升模型的性能,使用更多的数据、不同的特征,调整参数,这也是最耗时耗力的一步
使用模型:部署模型训练好的模型,对新的数据进行预测
测试模型:使用测试用数据验证模型,并评估模型的性能
接下来,我们看看机器学习在传统编程、统计学这些常见方法中处于什么样的地位。
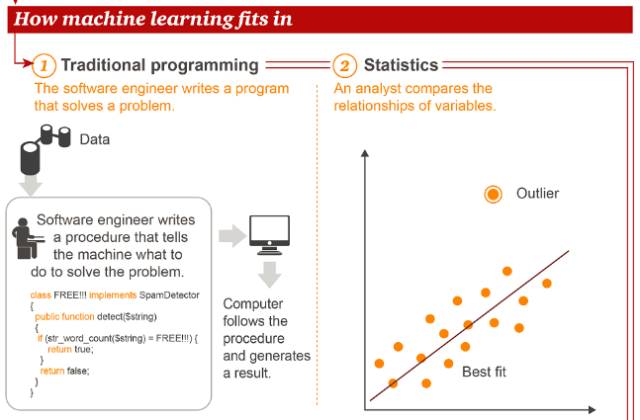
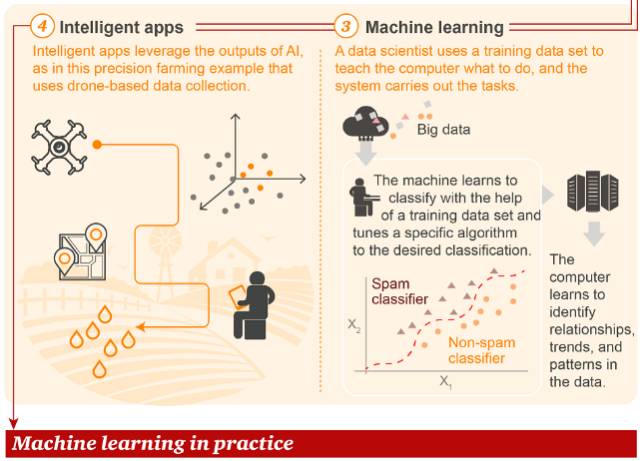
与传统编程和统计学方法不同,在机器学习当中,数据科学家使用训练数据“教育”计算机,然后让计算机执行任务。由此,产生了智能应用(Intelligent App)。图中所举的例子是智能农业,通过无人机采集的数据进行精准的施肥、灌溉等操作。
在实际应用中机器学习有很多适用场景。下图给出了3个例子:

1. 快速三维成图和建模 对一个铁路桥梁重建项目,PwC 数据科学家和领域专家将机器学习应用于无人机收集到的数据。这样的组合使得对正在进行的工作进行精确的监控和快速的反馈成为可能。
2. 加强分析以减轻风险 为了检测内幕交易,PwC 结合机器学习与其他分析技术,发掘更全面的用户资料,更深入地了解复杂的可疑行为。
3. 预测最佳表现者 PwC 使用机器学习和其他分析技术来评估墨尔本杯参赛的各匹马的潜力。
实际应用机器学习:什么才是特定任务的正确算法?
人工智能和机器学习是企业界的热门话题,公司的领导者对如何利用它们改善及自动化业务流程抱有很高的期望。
那么,AI 如何解决商业上的问题,例如帮助你弄清楚为什么流失了客户,或评估信贷申请人的风险?这取决于许多因素,尤其是算法使用的数据以及要训练的类型。什么是特定任务的正确算法?报告调查了最常用的算法以及它们解决的商业问题。
下面列举了最常用的算法及其使用案例。

机器学习中常用的算法有很多,具体需要用哪种,很大程度上取决于你手头的数据及其特征,你的训练目标,尤其是具体的使用场景。除非特殊情况,不必使用最复杂的算法。下面是常见的机器学习算法。
1. 决策树(Decision Trees)
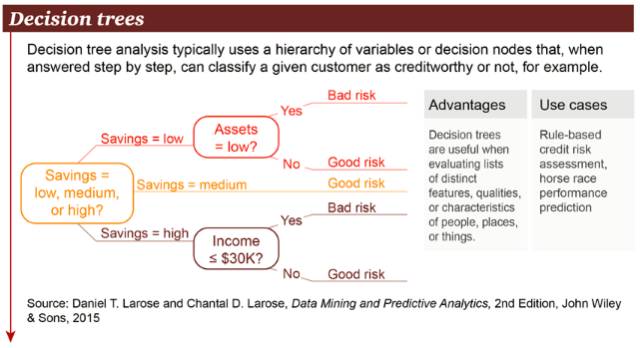
决策树是一个决策支持工具,它使用树形图或决策模型以及序列可能性。包括各种偶然事件的后果、资源成本、功效。从商务决策的角度来看,大部分情况下,决策树是一个人为了评估做出正确决定的概率需要问的是/否问题的最小数值。它能让你以一个结构化和系统化的方式来处理这个问题,然后得出一个合乎逻辑的结论。
2. 支持向量机

支持向量机(SVM)是二元分类算法。给定一组两种类型的N维的地方点,SVM产生一个(N - 1)维超平面到这些点分成2组。假设你有两种类型的点,且它们是线性可分的。SVM将找到一条直线将这些点分成2种类型,并且这条直线会尽可能地远离所有的点。在规模上,目前使用SVM(在适当修改的情况下)解决的最大的问题包括显示广告、人类剪接位点识别、基于图像的性别检测和大规模的图像分类等等。
3. 逻辑回归

回归是非常常用的方法。其中,逻辑回归是一种强大的统计方法,它能建模出一个二项结果与一个(或多个)解释变量。它通过估算使用逻辑运算的概率,测量分类依赖变量和一个(或多个)独立的变量之间的关系,是累积的逻辑分布情况。
总的来说,逻辑回归可以用于以下场景:
车流分析
信用评分
衡量营销活动的成功率
预测某个产品的收入
某一天是否会发生地震?
4. 朴素贝叶斯分类
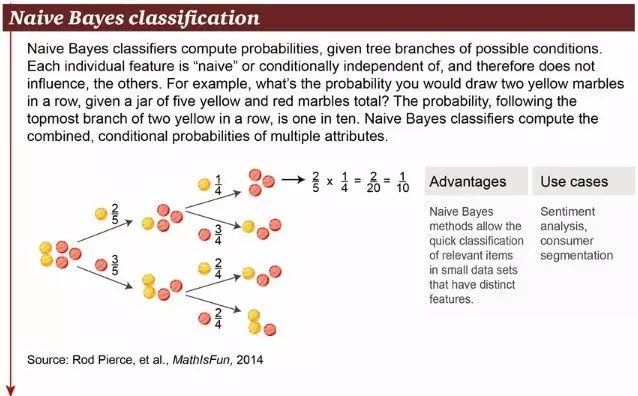
朴素贝叶斯分类是一种十分简单的分类算法,方程 P(A|B)是后验概率,P(B|A)是可能性,P(A)是类先验概率,而P(B)是预测先验概率。朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。它的现实使用例子有:
5. 隐马尔科夫模型
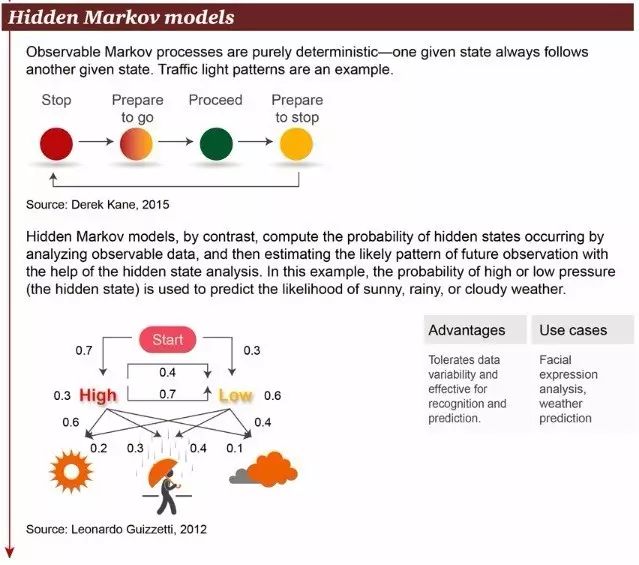
可观察的马尔科夫决策过程是确定性的——一个给定的状态总是遵循另一个给定的状态。例如交通信号灯的模式。
相反,隐马尔科夫模型通过分析可观察的数据来计算隐藏状态的概率,然后通过分析隐藏状态来估计未来可能观察到的模式。一个例子是,通过分析高气压(或低气压)的概率来预测天气是晴天,雨天或多云的可能性。
6. 随机森林
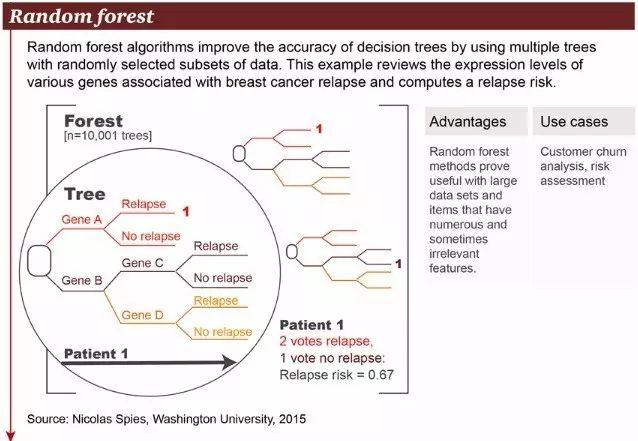
随机森林算法结合了多个树,使用随机挑选的数据子集,以此提升决策树的分析准确率。上图中的例子展示的是与乳腺癌复发相关的不同基因及其几率。随机深林算法的优势在于能够处理大规模数据集,以及大量看似不相关的数据,可以用于风险评估和客户信息分析。
7. 递归神经网络

实际上,递归神经网络(RNN)是两种人工神经网络的总称。一种是时间递归神经网络(Recurrent Neural Network),另一种是结构递归神经网络(Recursive Neural Network)。时间递归神经网络的神经元间连接构成有向图,而结构递归神经网络利用相似的神经网络结构递归构造更为复杂的深度网络。RNN一般指代时间递归神经网络,正如上图所示。
时间递归神经网络可以描述动态时间行为,因为和前馈神经网络(feedforward neural network)接受较特定结构的输入不同,RNN 将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。手写识别是最早成功利用 RNN 的研究结果,其他应用还包括图像分类、图说生成和情感分析。
8. 长短期记忆(LSTM)
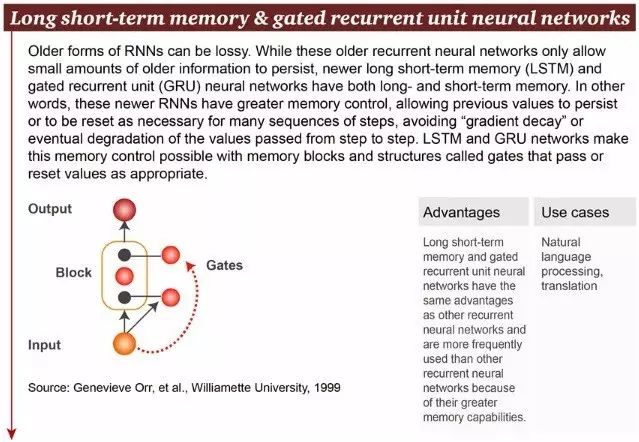
较旧的 RNN 可能是有损的(lossy),因为它们只能保存少量的旧信息。但新的长短期记忆(LSTM)和门控循环单元(gated recurrent unit, GRU)神经网络同时具有长期记忆和短期记忆。换句话说,这些较新的 RNN 具有更好的记忆控制,允许先前的值持续保存,或必要时为许多序列步骤重置,避免在步骤到步骤的传递时造成“梯度衰减”(gradient decay)。LSTM 和 GRU 网络通过记忆体组(memory blocks)和被称为“门”(gates)的结构适当地 pass 或 reset 值来实现这种记忆控制。
9. 卷积神经网络

卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理、药物发现等有出色表现。
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络在图像和语音识别方面能够给出更优的结果。这一模型也可以使用反向传播算法进行训练。相比较其他深度、前馈神经网络,卷积神经网络需要估计的参数更少。