
普通高中选课数据分析和可视化(4)
前情回顾:

3.9 生成各校Excel报名文件
首先打开"xk73.csv"文件,读取某市普通高中选课汇总数据,存储到DataFrame对象df中;再遍历每一所学校,生成7选3原始报名数据到excel文件。
核心代码(完整代码详见源代码文件“7选3生成各校Excel原始报名文件.py”):
# 读文件source_df = pd.read_csv("xk73.csv",sep=',',header='infer',encoding='utf-8')schools = source_df['学校代码'].unique() #生成学校代码名称列表for sch in schools: #遍历每一所学校,生成7选3原始报名数据到excel文件sch_df = source_df[source_df['学校代码']==sch]writer = pd.ExcelWriter(f'各校原始报名文件\{sch}.xlsx')sch_df.to_excel(writer,sheet_name='7选3原始数据',startcol=0,index=False)writer.save()writer.close()
3.10 生成各校7选3固定班级名册
先读取学校原始报名文件,合成学生选课组合信息后,筛选出报考人数达到固定班人数下限的选课组合,存储到DataFrame对象stu_1,生成7选3固定班级名册。把未达到固定班人数下限的选课组合信息存储到stu_2,以备后续生成7选2固定班级名册。
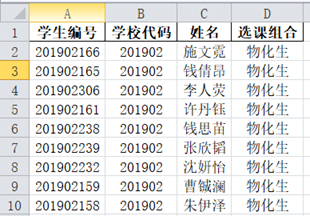
图15 某校7选3固定班级名册Excel表格截图
核心代码(完整代码详见源代码文件“7选3读取Excel原始报名文件并分班.py”):
courses = []for r in sch_df.index:km = ""for c in sch_df.columns:if sch_df.at[r,c] == 1:km += kms_dic[c]courses.append(km)zuhe_df = sch_df.loc[:, ['学生编号','学校代码','姓名']]zuhe_df.insert(3, '选课组合', courses)zuhe_df = zuhe_df.sort_values(['选课组合'],ascending=False)kmzh_3_nums = zuhe_df['选课组合'].value_counts()base = 40in_list = [c for c in kmzh_3_nums.index if kmzh_3_nums[c]>=base]stu_1 = zuhe_df.loc[zuhe_df['选课组合'].isin(in_list)]stu_2 = zuhe_df.loc[~zuhe_df['选课组合'].isin(in_list)]
3.11 生成各校7选2固定班级名册
在生成7选3固定班级名册后,把剩余学生的选课信息存储到stu_2,继续筛选出报考人数达到固定班人数下限的选课组合,存储到DataFrame对象stu_3,生成7选2固定班级名册。并把剩余学生的选课信息存储到stu_4,以便走班管理,或引导他\她们重新选课。
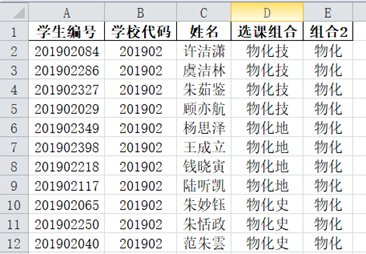
图16 某校7选2固定班级名册Excel表格截图
核心代码(完整代码详见源代码文件“7选3读取Excel原始报名文件并分班.py”):
kmzh_2_df = pd.DataFrame(columns=stu_2.columns)kmzh_2_df["组合2"] = ""base = 40for k in kmzh_2:tmp = stu_2.loc[(stu_2["选课组合"].str.contains(k[0])) & (stu_2["选课组合"].str.contains(k[1]))]tmp.insert(4, "组合2", [k] * len(tmp))kmzh_2_df = kmzh_2_df.append(tmp)kmzh_2_nums = kmzh_2_df['组合2'].value_counts()in_list = [c for c in kmzh_2_nums.index if kmzh_2_nums[c]>=base]stu_3 = kmzh_2_df.loc[kmzh_2_df['组合2'].isin(in_list)]stu_4 = kmzh_2_df.loc[~kmzh_2_df['组合2'].isin(in_list)]
说明:因为本项目内容较多,故写成系列文章分成多次分享,请大家稍安勿躁哦。
需要本文word版或者相关源代码的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
相关优秀文章:
斌哥教你自制多功能单词本
普通高中选课数据分析和可视化(1)
普通高中选课数据分析和可视化(2)
普通高中选课数据分析和可视化(3)
评论