
面试官:你会几种分布式 ID 生成方案???

1. 为什么需要分布式 ID

对于单体系统来说,主键 ID 常用主键自动的方式进行设置。这种 ID 生成方法在单体项目是可行的,但是对于分布式系统,分库分表之后就不适应了。比如订单表数据量太大了,分成了多个库,如果还采用数据库主键自增的方式,就会出现在不同库 id 一致的情况,虽然是不符合业务的。
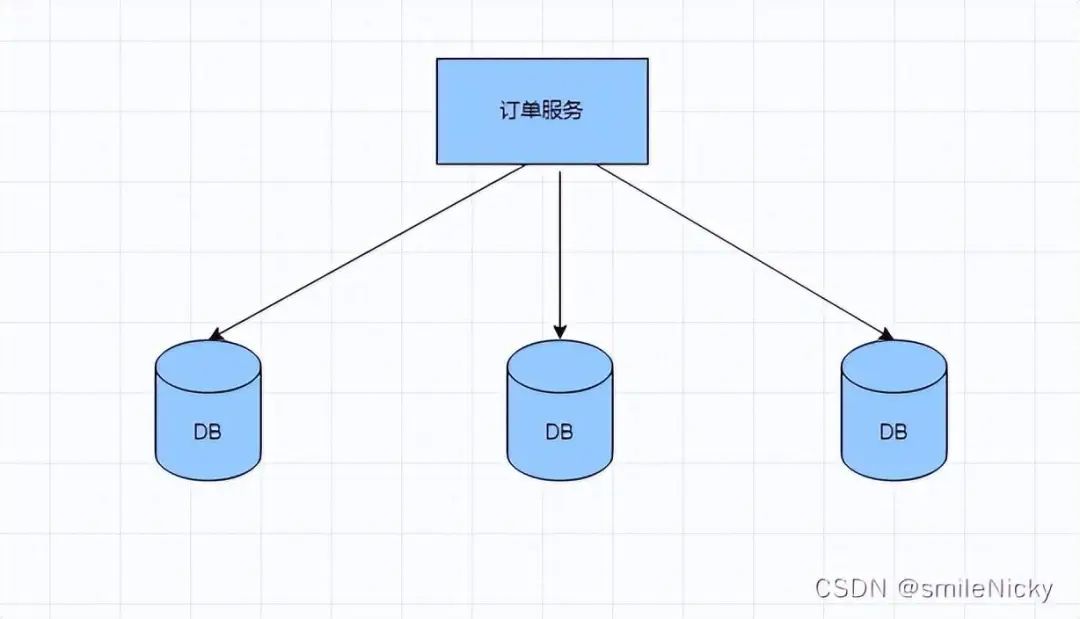
2. 业务系统对分布式 ID 有什么要求
全局唯一性:ID 是作为唯一的标识,不能出现重复;
趋势递增:互联网比较喜欢 MySQL 数据库,而 MySQL 数据库默认使用 InnoDB 存储引擎,其使用的是聚集索引,使用有序的主键 ID 有利于保证写入的效率;
单调递增:保证下一个 ID 大于上一个 ID,这种情况可以保证事务版本号,排序等特殊需求实现;
信息安全:前面说了 ID 要递增,但是最好不要连续。如果 ID 是连续的,容易被恶意爬取数据,指定一系列连续的,所以 ID 递增但是不规则是最好的。
3. 分布式 ID 生成方案
UUID
数据库自增
号段模式
Redis 实现
雪花算法(SnowFlake)
百度 Uidgenerator
美团 Leaf
滴滴 TinyID
3.1 UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。
UUID 的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 36 个字符,示例 863e254b-ae34-4371-87da-204b71d46a7b。
UUID 理论上的总数为 1632=2128,约等于 3.4 x 10^38。
优点:性能非常高,本地生成的,不依赖于网络;
缺点:不易存储。16 字节 128 位,36 位长度的字符串信息不安全,基于 MAC 地址生成 UUID 算法可能会造成 MAC 地址泄露,暴露使用者的位置。UUID 的无序性可能会引起数据位置频繁变动,影响性能。
3.2 数据库自增
在分布式环境也可以使用 MySQL 自增实现分布式 ID 的生成。如果分库分表了,当然不是简单地设置好 auto_increment_increment 和 auto_increment_offset 就行。在分布式系统中,我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。
比如有两台机器,设置步长 step 为 2。Server1 的初始值为 1(1, 3, 5, 7, 9, 11…),Server2 的初始值为 2(2, 4, 6, 8, 10…)。
这是 Flickr 团队在 2010 年撰文介绍的一种主键生成策略(Ticket Servers: Distributed Unique Primary Keys on the Cheap )。
假设有 N 台机器,step 就要设置为 N,如下图进行设置:
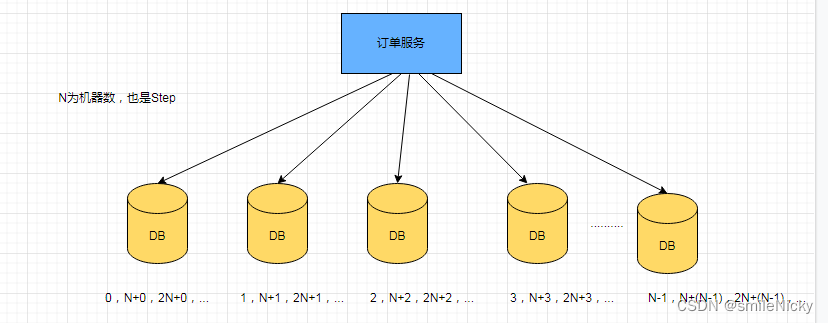
这种方案看起来是可行的。但是如果要扩容,步长 step 等要重新设置。
假如只有一台机器,步长就是 1,比如 1,2,3,4,5,6。这时候如果要进行扩容,就要重新设置。
机器 2 可以挑一个偶数的数字,这个数字在扩容时间内,数据库自增达不到这个数的,然后步长就是 2。机器 1 要重新设置 step 为 2,然后还是以一个奇数开始进行自增。
这个过程看起来不是很杂,但是如果机器很多的话,那就要花很多时间去维护重新设置。
这种实现的缺陷:
ID 没有了单调递增的特性,只能趋势递增。有些业务场景可能不符合;
数据库压力还是比较大,每次获取 ID 都需要读取数据库,只能通过多台机器提高稳定性和性能。
3.3 号段模式
这种模式也是现在生成分布式 ID 的一种方法。实现思路是,会从数据库获取一个号段范围,比如 [1,1000],生成 1 到 1000 的自增 ID 加载到内存中。
建表结构如下:
CREATE TABLE id_generator (id int(10) NOT NULL,max_id bigint(20) NOT NULL COMMENT '当前最大id',step int(20) NOT NULL COMMENT '号段的布长',biz_type int(20) NOT NULL COMMENT '业务类型',version int(20) NOT NULL COMMENT '版本号',PRIMARY KEY (`id`))
biz_type:不同业务类型;
max_id :当前最大的 id;
step:代表号段的步长;
version :版本号,就像 MVCC 一样,可以理解为乐观锁。
等 ID 都用完了,再去数据库获取,然后更改最大值:
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX-
优点:有比较成熟的方案,像百度 Uidgenerator,美团 Leaf; -
缺点:依赖于数据库实现。
3.4 Redis 实现
-
优点:Redis 性能相对比较好,而且可以保证唯一性和有序性; -
缺点:需要依赖 Redis 来实现,系统需要引入 Redis 组件。
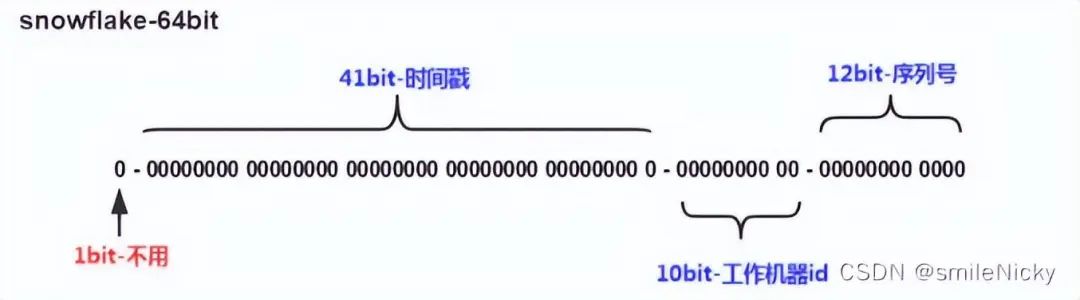
3.5 雪花算法(SnowFlake)
-
第一部分:第一位占用 1 bit,始终是 0,是一个符号位,不使用; -
第二部分:第 2 位开始的 41 位是时间戳。41-bit 位可表示 241 个数,每个数代表毫秒,那么雪花算法可用的时间年限是 (241)/(1000606024365)=69 年的时间; -
第三部分:10-bit 位可表示机器数,即 2^10 = 1024 台机器。通常不会部署这么多台机器; -
第四部分:12-bit 位是自增序列,可表示 2^12 = 4096 个数。觉得一毫秒个数不够用也可以调大点。
-
优点:雪花算法生成的 ID 是趋势递增,不依赖数据库等第三方系统。生成 ID 的效率非常高,稳定性好,可以根据自身业务特性分配 bit 位,比较灵活; -
缺点:雪花算法强依赖于机器时钟。如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。如果恰巧回退前生成过一些 ID,而时间回退后,生成的 ID 就有可能重复。
3.6 百度 Uidgenerator
引用官网的解释:

-
sign(1bit):固定 1bit 符号标识,即生成的 UID 为正数; -
delta seconds (28 bits):当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年; -
worker id (22 bits):机器 id,最多可支持约 420 万次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略; -
sequence (13 bits):每秒下的并发序列,13 bits 可支持每秒 8192 个并发。
3.7 美团 Leaf
There are no two identical leaves in the world “世界上没有两片相同的树叶”
-
原方案每次获取 ID 都得读写一次数据库,造成数据库压力大。改为利用 proxy server 批量获取,每次获取一个 segment(step 决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大减轻数据库的压力; -
各个业务不同的发号需求用 biz_tag 字段来区分,每个 biz-tag 的 ID 获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对 biz_tag 分库分表就行。
>+-------------+--------------+------+-----+-------------------+-----------------------------+| Field | Type | Null | Key | Default | Extra |+-------------+--------------+------+-----+-------------------+-----------------------------+| biz_tag | varchar(128) | NO | PRI | | || max_id | bigint(20) | NO | | 1 | || step | int(11) | NO | | NULL | || desc | varchar(256) | YES | | NULL | || update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |+-------------+--------------+------+-----+-------------------+-----------------------------+
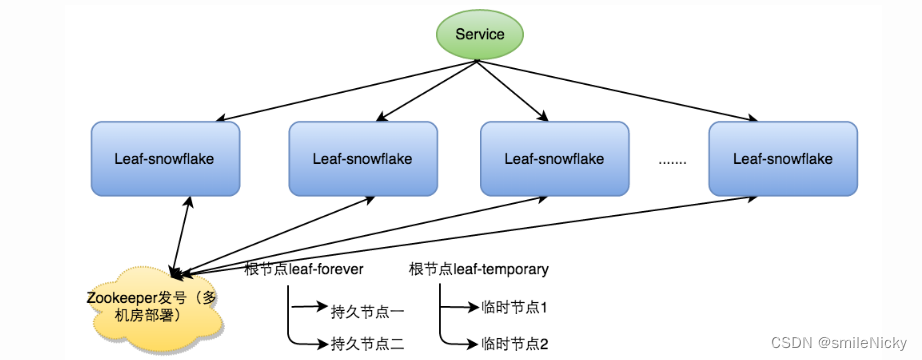
Leafsnowflake 方案
Leafsnowflake 是在雪花算法上改进来的,引用官网技术博客介绍:
-
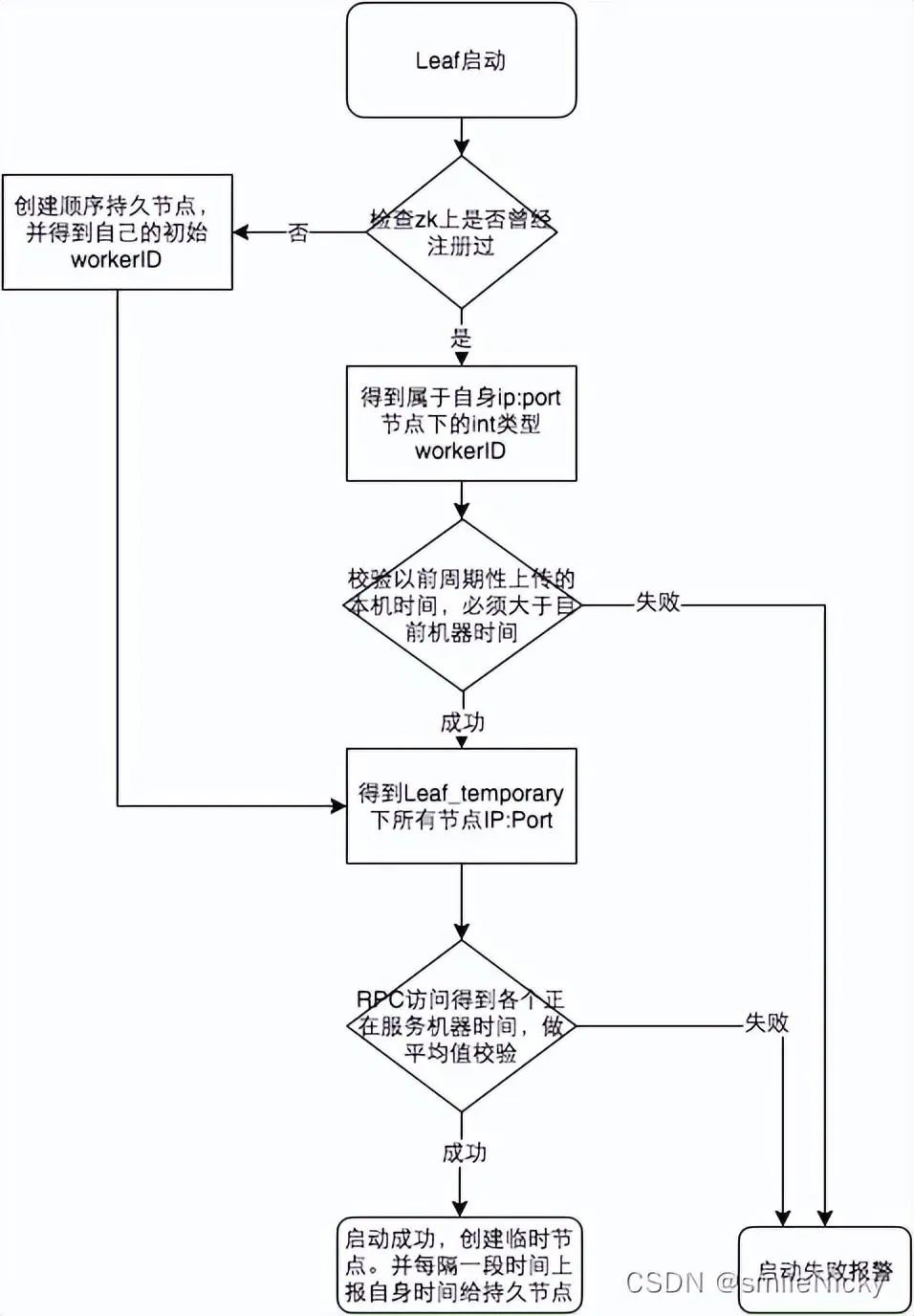
启动 Leaf-snowflake 服务,连接 Zookeeper,在 leaf_forever 父节点下检查自己是否已经注册过(是否有该顺序子节点); -
如果有注册过直接取回自己的 workerID(Zookeeper 顺序节点生成的int类型ID号),启动服务; -
如果没有注册过,就在该父节点下面创建一个持久顺序节点。创建成功后取回顺序号当做自己的 workerID 号,启动服务。
3.8 滴滴 Tinyid
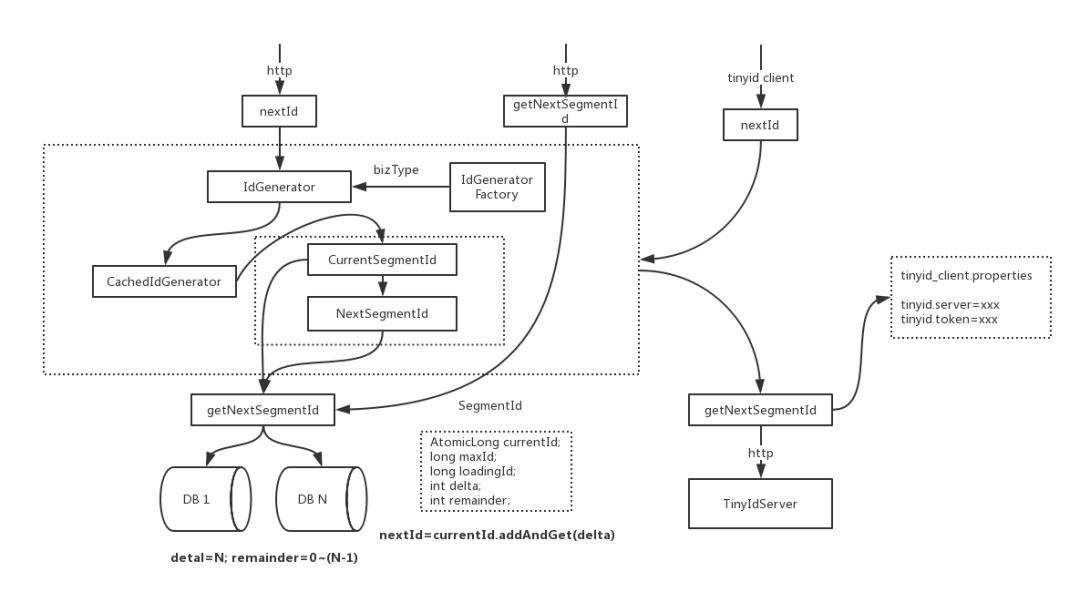
-
优点:方便集成,有成熟的方案和实现; -
缺点:依赖 DB 稳定性,需要采用集群主从备份的方式提高 DB 可用性。
作者:smileNicky
来源:blog.csdn.net/u014427391/article/details/127408363
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
面试题】即可获取