
深度学习 VS 传统计算机视觉
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:机器之心
作者:Niall O’ Mahony等 | 参与:魔王、张倩
深度学习崛起后,传统计算机视觉方法被淘汰了吗?

论文链接:https://arxiv.org/ftp/arxiv/papers/1910/1910.13796.pdf
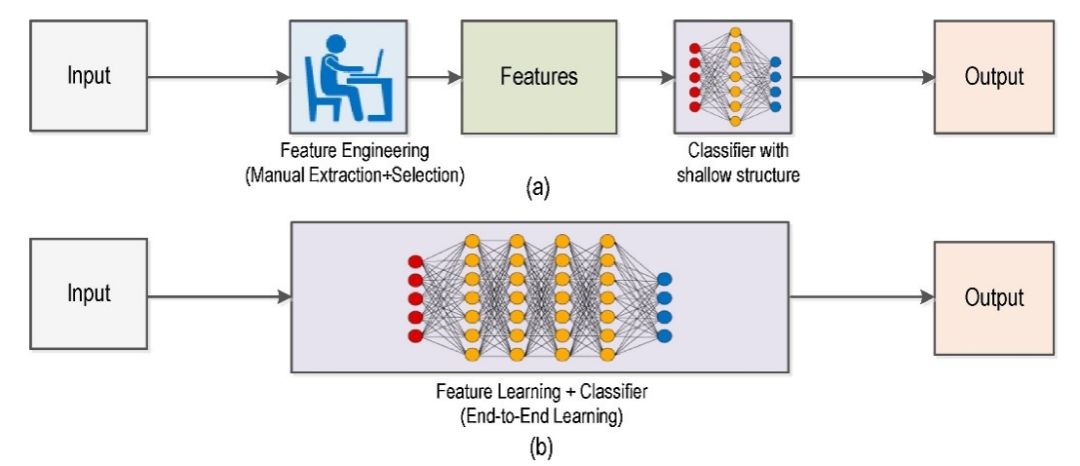
图 1:a)传统计算机视觉工作流 vs b)深度学习工作流。(图源:[8])
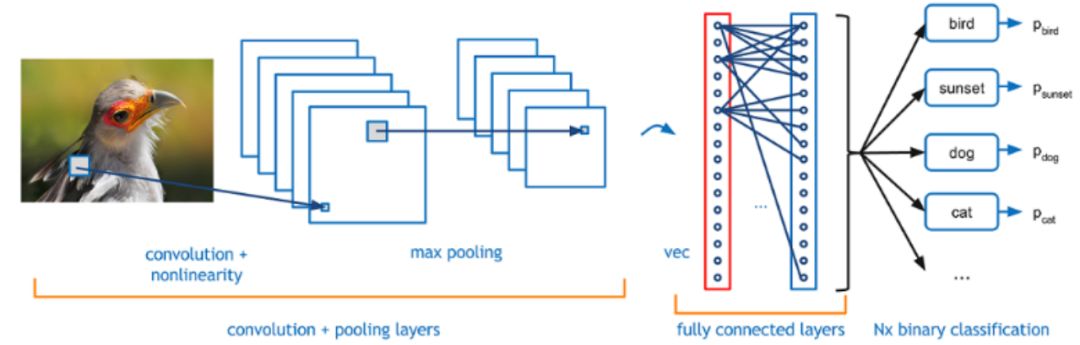
图 2:CNN 构造块。(图源:[13])
尺度不变特征变换(Scale Invariant Feature Transform,SIFT)[14]
加速稳健特征(Speeded Up Robust Feature,SURF)[15]
基于加速分割测试的特征(Features from Accelerated Segment Test,FAST)[16]
霍夫变换(Hough transform)[17]
几何哈希(Geometric hashing)[18]
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论