
深度学习前人精度很高了,该怎么创新?
机器学习实验室
共 3707字,需浏览 8分钟
·
2021-04-19 16:20
导读
深度学习领域新技术层出不穷,顶尖的研究人员也愈来越多,当研究领域的前人精度已经很高了,我们该怎么创新,从哪些角度去创新呢?
# 回答一
作者:仿佛若有光
公众号:CV技术指南
来源链接:
https://www.zhihu.com/question/451438634/answer/1813414490# 回答二
作者:DLing
来源链接:
https://www.zhihu.com/question/451438634/answer/1815201106
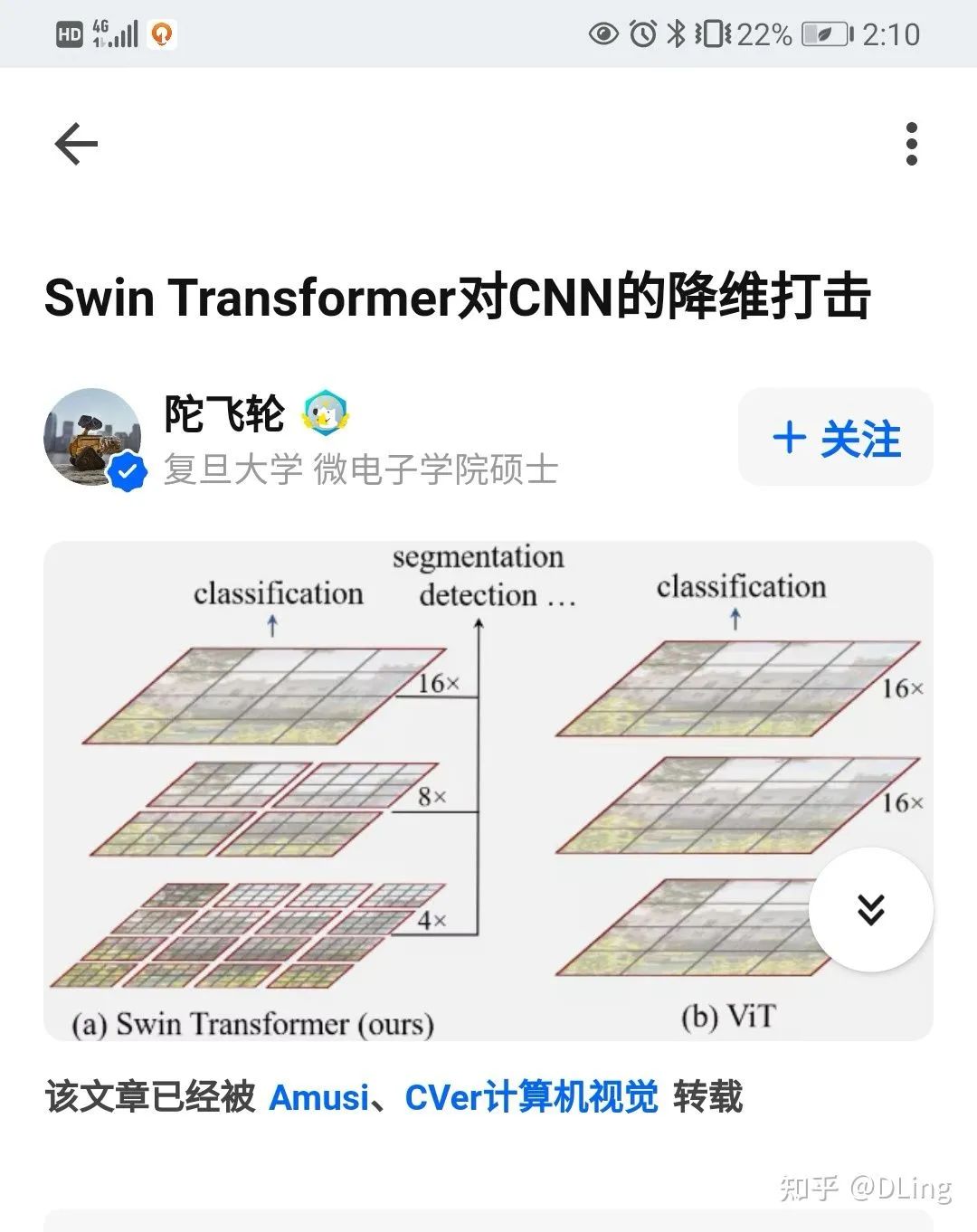
# 回答三
作者:CC查理
来源链接:
https://www.zhihu.com/question/451438634/answer/1816128126
往期精彩:
求个在看
评论