
用于RGB-D显著目标检测的自监督表示学习
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


现有的基于CNN的RGB-D显著目标检测(SOD)网络都需要在ImageNet上进行预先训练,学习层次特征,这有助于提供良好的初始化。然而,大规模数据集的收集和注释是耗时和昂贵的。在本文中,我们利用自监督表示学习(SSL)设计了两个借口任务:跨模态自动编码器和深度轮廓估计。我们的借口任务只需要少量的和未标记的RGB-D数据集来执行预训练,这使网络捕获丰富的语义上下文,并减少两种模式之间的差距,从而为下游任务提供一个有效的初始化。此外,针对RGB-D SOD中固有的跨模态融合问题,我们提出了一种多路径融合(MPF)模块,该模块将单一特征融合分解为多路径融合,以实现对一致和差异信息的充分感知。强积金模块具有通用性,适用于跨模态和跨层次的特征融合。在6个基准的RGB-D SOD数据集上进行了大量的实验,我们的模型在RGB-D数据集上进行了预处理(6;335不带任何注释)可以优于大多数在ImageNet上预先训练的最先进的RGB-D方法(1;280;000,带有图像级注释)。
对于网络架构,我们提出了一个通用模块,称为多路径融合(MPF),以实现跨模态和跨级融合。具体来说,对于两种具有互补关系的特征,我们计算它们的共同一致(JC)特征和共同差异(JD)特征。JC特征更注重其一致性,并能有效防止非显著信息的干扰。JD的功能描述了它们的差异,并可以补充微妙的信息。
我们的主要贡献总结如下:
我们提出了一种与RGB- d SOD任务密切相关的自监督网络,该网络由跨模态的RGB深度显著性分类、RGB深度深度轮廓深度、RGB基于cnn的RGB- d SOD网络(Others)、SSL网络(Ours)自动编码器和深度轮廓估计译码器组成。这是第一个对RGB-D SOD进行自监督表示学习的方法。
我们设计了一种简单有效的多路径融合结构,适用于跨层次和跨模态的特征融合。
我们使用6;335对没有任何相互标签的rgb深度图像。与预先训练的ImageNet相比(1;280;在6个RGB-D数据集上,我们的方法仍然比大多数竞争对手表现得更好。此外,本文提出的具有ImageNet预训练的网络在RGB SOD任务上也取得了良好的性能。
我们的网络架构如下图所示,遵循由一个编码器、一个多路径融合模块和一个解码器组成的双流模型。编码器-解码器体系结构是基于FPN[28]。编码器基于一个共同的骨干网,例如VGG-16[42],分别对RGB和深度进行特征提取。我们抛弃了VGG-16的所有全连接层,去掉最后的池化层,将VGG-16网络修改为全卷积网络。我们将两模编码块的输出特征传递到多路径融合模块中,实现各层次的跨模态融合。强积金也嵌入在解码器中。一旦我们得到这些跨模态融合的特征,它们就会参与到解码器中,从高阶到低阶的细节逐步融合,从而不断恢复全分辨率显著图。
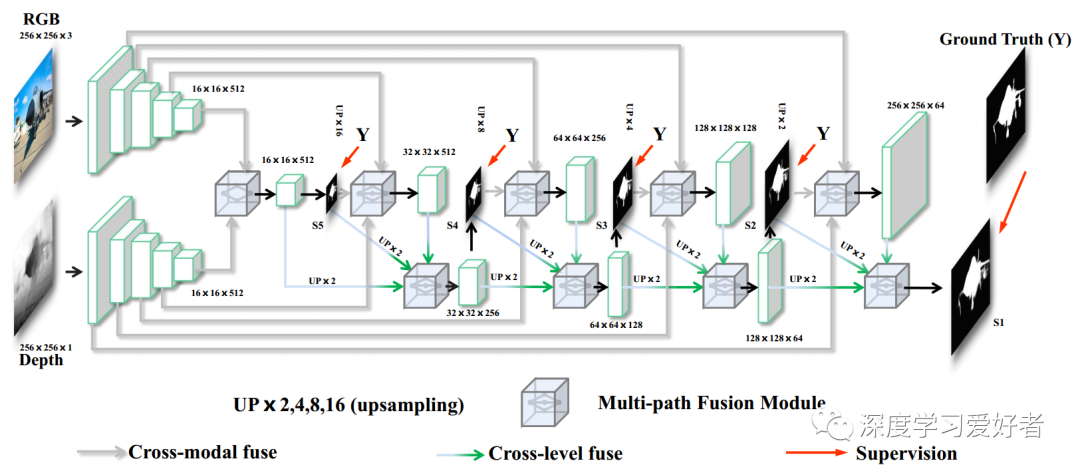
网络管道的下游任务。它由两个VGG-16编码器、五个跨模态层和四个解码器块组成。多路径融合模块(MPF)实现了跨模态和跨层次的融合。我们采用交叉熵损失作为监督,生成多分辨率的地面真值。
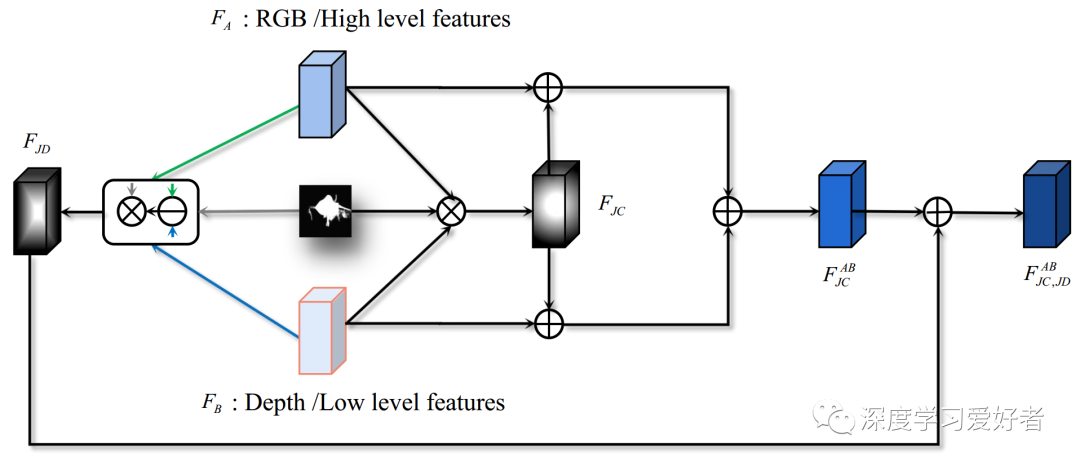
多路径融合模块示意图
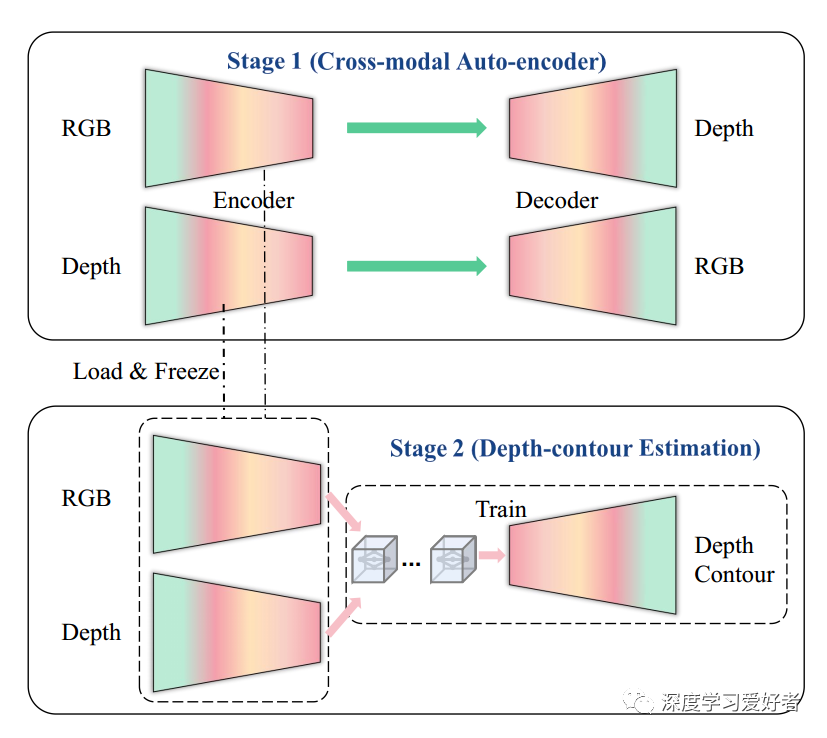
第一阶段:跨模态自动编码器。第二阶段:深度轮廓估计。

不同RGB-D SOD方法的目视比较
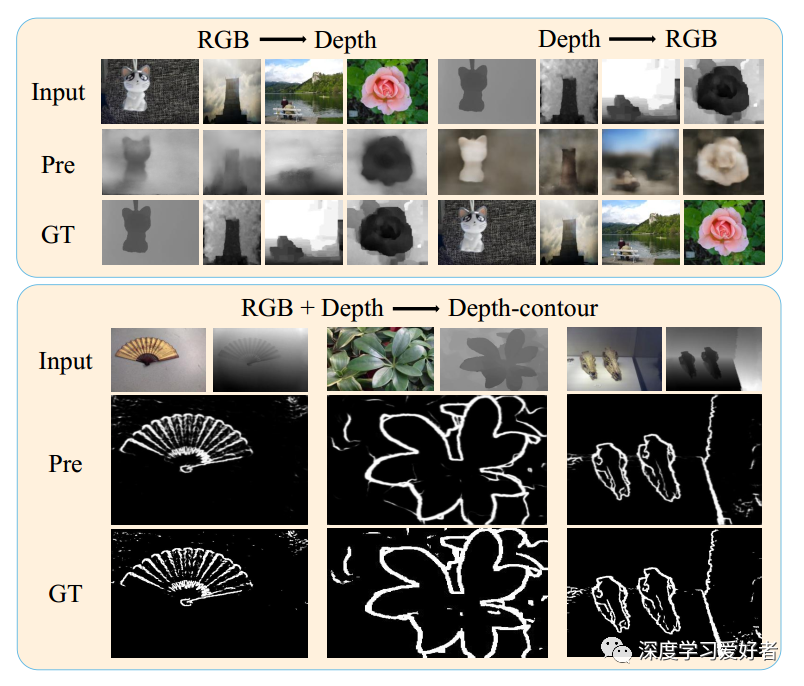
在这项工作中,我们提出了一种新的自监督学习(SSL)方案来完成有效的RGB-D SOD任务的前训练,而不需要人工标注。SSL借口任务包括跨模态自动编码和深度轮廓估计,通过这些任务网络可以捕获丰富的上下文,减少模态之间的差距。此外,我们还设计了一个多路径融合模块,实现了跨通道、跨层次的信息融合。大量的实验表明,我们的模型在RGB- d和RGB SOD数据集上都有很好的表现。作为SSL在RGB-D SOD中的第一种方法,可以作为未来研究的新基线。
论文链接:https://arxiv.org/pdf/2101.12482.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~