
【Python私活案例】Pandas找到公司内最相似的员工(100元)
今日份在蚂蚁老师的vip群里,有一位群友提出一个需求
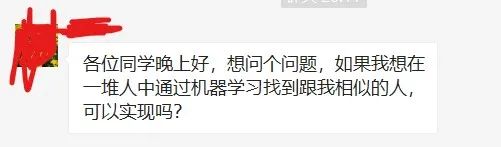
我马上想到可以用所学的pandas相关知识解决
让我们来看看群友的具体需求
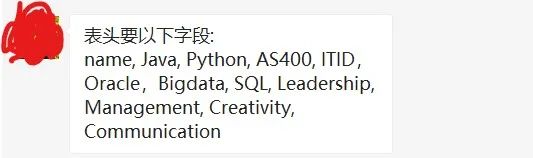
我们根据群友的需求,构造了出了相应的表格数据
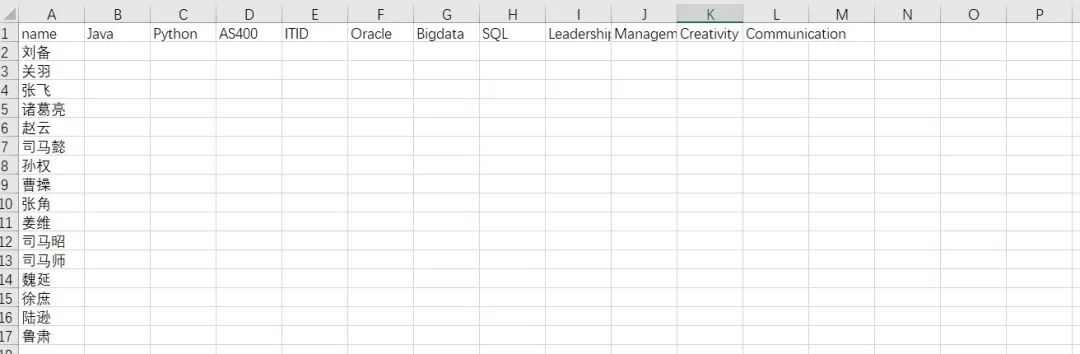
在这里,我在name字段下先设定了一些值
开始写代码!
首先引入numpy和pandas,这俩是数据分析领域必不可少的模块
import numpy as np
# 这行代码的意思是通过设置固定的随机数种子,让你我生成的随机数是一样的
np.random.seed(666)
import pandas as pd
# 读取我们的excel文件
data = pd.read_excel("data.xlsx")
观察数据,我们有十六名员工,除了姓名,其它都是空值
data
| name | Java | Python | AS400 | ITID | Oracle | Bigdata | SQL | Leadership | Management | Creativity | Communication | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 刘备 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 关羽 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 张飞 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 诸葛亮 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 赵云 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 司马懿 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 6 | 孙权 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7 | 曹操 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 8 | 张角 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 9 | 姜维 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 10 | 司马昭 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 11 | 司马师 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 12 | 魏延 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 13 | 徐庶 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 14 | 陆逊 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 15 | 鲁肃 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
将空值用0到1之间的随机数代替
def initialize(item):
# 如果发现当前这个元素是空值,就用随机数代替
if pd.isnull(item):
return np.random.random()
# 否则就原样返回(对应name那列)
else:
return item
通过applymap函数,将上面的自定义函数应用到表格中的每一个数据上
new_data = data.applymap(initialize)
再来看看我们构造好的数据new_data,发现已经得到预期值了
new_data
| name | Java | Python | AS400 | ITID | Oracle | Bigdata | SQL | Leadership | Management | Creativity | Communication | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 刘备 | 0.036712 | 0.354109 | 0.897044 | 0.510947 | 0.847097 | 0.819443 | 0.788641 | 0.285868 | 0.994770 | 0.577906 | 0.273414 |
| 1 | 关羽 | 0.155675 | 0.440437 | 0.554369 | 0.147062 | 0.121957 | 0.378483 | 0.868364 | 0.670942 | 0.700497 | 0.719190 | 0.035426 |
| 2 | 张飞 | 0.138446 | 0.237509 | 0.688492 | 0.986374 | 0.515409 | 0.910156 | 0.170967 | 0.799865 | 0.020661 | 0.802278 | 0.424132 |
| 3 | 诸葛亮 | 0.045878 | 0.295690 | 0.875218 | 0.014569 | 0.041040 | 0.406339 | 0.696076 | 0.306823 | 0.178275 | 0.006340 | 0.132899 |
| 4 | 赵云 | 0.926776 | 0.158741 | 0.212268 | 0.999313 | 0.060130 | 0.593934 | 0.296281 | 0.425722 | 0.665509 | 0.910555 | 0.824788 |
| 5 | 司马懿 | 0.158174 | 0.686519 | 0.989481 | 0.328145 | 0.843783 | 0.894061 | 0.314048 | 0.292965 | 0.305031 | 0.236982 | 0.178578 |
| 6 | 孙权 | 0.234794 | 0.854272 | 0.953005 | 0.973668 | 0.483947 | 0.904404 | 0.803289 | 0.522370 | 0.949673 | 0.096465 | 0.439397 |
| 7 | 曹操 | 0.218246 | 0.707425 | 0.881069 | 0.376662 | 0.801466 | 0.755265 | 0.291798 | 0.938050 | 0.485826 | 0.346437 | 0.066456 |
| 8 | 张角 | 0.498340 | 0.563020 | 0.019941 | 0.686956 | 0.438963 | 0.942209 | 0.535298 | 0.068399 | 0.169205 | 0.638146 | 0.246636 |
| 9 | 姜维 | 0.866382 | 0.336534 | 0.459816 | 0.121275 | 0.117527 | 0.086200 | 0.724672 | 0.041077 | 0.792852 | 0.620457 | 0.794938 |
| 10 | 司马昭 | 0.387280 | 0.911111 | 0.361018 | 0.024711 | 0.352168 | 0.874307 | 0.560931 | 0.066454 | 0.303852 | 0.267894 | 0.524910 |
| 11 | 司马师 | 0.069331 | 0.654498 | 0.133358 | 0.349297 | 0.092552 | 0.527592 | 0.559391 | 0.041385 | 0.411011 | 0.391010 | 0.340453 |
| 12 | 魏延 | 0.057241 | 0.201021 | 0.491702 | 0.580754 | 0.186123 | 0.807221 | 0.324736 | 0.729737 | 0.920088 | 0.080613 | 0.537976 |
| 13 | 徐庶 | 0.036221 | 0.205992 | 0.953927 | 0.383384 | 0.494315 | 0.416861 | 0.089345 | 0.640795 | 0.513479 | 0.412078 | 0.759755 |
| 14 | 陆逊 | 0.570870 | 0.410881 | 0.757321 | 0.260093 | 0.916110 | 0.689473 | 0.087644 | 0.199368 | 0.570718 | 0.741445 | 0.307660 |
| 15 | 鲁肃 | 0.412343 | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | 0.135349 | 0.436991 |
接下来我想将上面的表格进行自表连接,便于计算,所以设置了一个用于连接的公共字段one
new_data["one"] = 1
new_data.head(5)
| name | Java | Python | AS400 | ITID | Oracle | Bigdata | SQL | Leadership | Management | Creativity | Communication | one | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 刘备 | 0.036712 | 0.354109 | 0.897044 | 0.510947 | 0.847097 | 0.819443 | 0.788641 | 0.285868 | 0.994770 | 0.577906 | 0.273414 | 1 |
| 1 | 关羽 | 0.155675 | 0.440437 | 0.554369 | 0.147062 | 0.121957 | 0.378483 | 0.868364 | 0.670942 | 0.700497 | 0.719190 | 0.035426 | 1 |
| 2 | 张飞 | 0.138446 | 0.237509 | 0.688492 | 0.986374 | 0.515409 | 0.910156 | 0.170967 | 0.799865 | 0.020661 | 0.802278 | 0.424132 | 1 |
| 3 | 诸葛亮 | 0.045878 | 0.295690 | 0.875218 | 0.014569 | 0.041040 | 0.406339 | 0.696076 | 0.306823 | 0.178275 | 0.006340 | 0.132899 | 1 |
| 4 | 赵云 | 0.926776 | 0.158741 | 0.212268 | 0.999313 | 0.060130 | 0.593934 | 0.296281 | 0.425722 | 0.665509 | 0.910555 | 0.824788 | 1 |
进行自表连接,可以发现我们连接后的表有256行,也就是16*16,符合预期
需要注意的是,为了区分一左右两个表的数据来源,会将来源于左表的字段加_x,来源于右表则加_y
new_data_merge = pd.merge(left=new_data, right=new_data, left_on="one", right_on="one")
new_data_merge
| name_x | Java_x | Python_x | AS400_x | ITID_x | Oracle_x | Bigdata_x | SQL_x | Leadership_x | Management_x | ... | Python_y | AS400_y | ITID_y | Oracle_y | Bigdata_y | SQL_y | Leadership_y | Management_y | Creativity_y | Communication_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 刘备 | 0.036712 | 0.354109 | 0.897044 | 0.510947 | 0.847097 | 0.819443 | 0.788641 | 0.285868 | 0.994770 | ... | 0.354109 | 0.897044 | 0.510947 | 0.847097 | 0.819443 | 0.788641 | 0.285868 | 0.994770 | 0.577906 | 0.273414 |
| 1 | 刘备 | 0.036712 | 0.354109 | 0.897044 | 0.510947 | 0.847097 | 0.819443 | 0.788641 | 0.285868 | 0.994770 | ... | 0.440437 | 0.554369 | 0.147062 | 0.121957 | 0.378483 | 0.868364 | 0.670942 | 0.700497 | 0.719190 | 0.035426 |
| 2 | 刘备 | 0.036712 | 0.354109 | 0.897044 | 0.510947 | 0.847097 | 0.819443 | 0.788641 | 0.285868 | 0.994770 | ... | 0.237509 | 0.688492 | 0.986374 | 0.515409 | 0.910156 | 0.170967 | 0.799865 | 0.020661 | 0.802278 | 0.424132 |
| 3 | 刘备 | 0.036712 | 0.354109 | 0.897044 | 0.510947 | 0.847097 | 0.819443 | 0.788641 | 0.285868 | 0.994770 | ... | 0.295690 | 0.875218 | 0.014569 | 0.041040 | 0.406339 | 0.696076 | 0.306823 | 0.178275 | 0.006340 | 0.132899 |
| 4 | 刘备 | 0.036712 | 0.354109 | 0.897044 | 0.510947 | 0.847097 | 0.819443 | 0.788641 | 0.285868 | 0.994770 | ... | 0.158741 | 0.212268 | 0.999313 | 0.060130 | 0.593934 | 0.296281 | 0.425722 | 0.665509 | 0.910555 | 0.824788 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 251 | 鲁肃 | 0.412343 | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | ... | 0.654498 | 0.133358 | 0.349297 | 0.092552 | 0.527592 | 0.559391 | 0.041385 | 0.411011 | 0.391010 | 0.340453 |
| 252 | 鲁肃 | 0.412343 | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | ... | 0.201021 | 0.491702 | 0.580754 | 0.186123 | 0.807221 | 0.324736 | 0.729737 | 0.920088 | 0.080613 | 0.537976 |
| 253 | 鲁肃 | 0.412343 | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | ... | 0.205992 | 0.953927 | 0.383384 | 0.494315 | 0.416861 | 0.089345 | 0.640795 | 0.513479 | 0.412078 | 0.759755 |
| 254 | 鲁肃 | 0.412343 | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | ... | 0.410881 | 0.757321 | 0.260093 | 0.916110 | 0.689473 | 0.087644 | 0.199368 | 0.570718 | 0.741445 | 0.307660 |
| 255 | 鲁肃 | 0.412343 | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | ... | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | 0.135349 | 0.436991 |
256 rows × 25 columns
紧接着,我们看一下特征属性,要剔除name字段以及用于自表连接的one字段
我们也可以通过修改columns里面的值,自定义关注哪些字段
columns = list(new_data.columns)
columns.remove("name")
columns.remove("one")
columns
['Java',
'Python',
'AS400',
'ITID',
'Oracle',
'Bigdata',
'SQL',
'Leadership',
'Management',
'Creativity',
'Communication']
计算相似度的函数
我们通过“欧式距离”来表征相似度,欧式距离越大,说明两者之间差距越大,相似度越小,反之亦然
def similarity(row):
# 传进来的row是表中的一行
# 设定相似度的初始值是0
sim_value = 0.0
# 取出一行当中的每一个特征值
# 相应的特征值相减之后的结果再进行平方,最后全部加起来,也就是“欧氏距离”的概念
for column in columns:
sim_value += (float(row[column+"_x"]) - float(row[column+"_y"]))**2
return sim_value
通过设定axis=1来指定对表格中的每一行进行计算相似度的操作
new_data_merge["sim"] = new_data_merge.apply(similarity, axis=1)
来看看计算后的表格,发现多了一个字段sim
new_data_merge.sample(15)
| name_x | Java_x | Python_x | AS400_x | ITID_x | Oracle_x | Bigdata_x | SQL_x | Leadership_x | Management_x | ... | AS400_y | ITID_y | Oracle_y | Bigdata_y | SQL_y | Leadership_y | Management_y | Creativity_y | Communication_y | sim | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 218 | 徐庶 | 0.036221 | 0.205992 | 0.953927 | 0.383384 | 0.494315 | 0.416861 | 0.089345 | 0.640795 | 0.513479 | ... | 0.361018 | 0.024711 | 0.352168 | 0.874307 | 0.560931 | 0.066454 | 0.303852 | 0.267894 | 0.524910 | 2.002230 |
| 62 | 诸葛亮 | 0.045878 | 0.295690 | 0.875218 | 0.014569 | 0.041040 | 0.406339 | 0.696076 | 0.306823 | 0.178275 | ... | 0.757321 | 0.260093 | 0.916110 | 0.689473 | 0.087644 | 0.199368 | 0.570718 | 0.741445 | 0.307660 | 2.315648 |
| 245 | 鲁肃 | 0.412343 | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | ... | 0.989481 | 0.328145 | 0.843783 | 0.894061 | 0.314048 | 0.292965 | 0.305031 | 0.236982 | 0.178578 | 1.749616 |
| 129 | 张角 | 0.498340 | 0.563020 | 0.019941 | 0.686956 | 0.438963 | 0.942209 | 0.535298 | 0.068399 | 0.169205 | ... | 0.554369 | 0.147062 | 0.121957 | 0.378483 | 0.868364 | 0.670942 | 0.700497 | 0.719190 | 0.035426 | 1.935264 |
| 46 | 张飞 | 0.138446 | 0.237509 | 0.688492 | 0.986374 | 0.515409 | 0.910156 | 0.170967 | 0.799865 | 0.020661 | ... | 0.757321 | 0.260093 | 0.916110 | 0.689473 | 0.087644 | 0.199368 | 0.570718 | 0.741445 | 0.307660 | 1.645900 |
| 149 | 姜维 | 0.866382 | 0.336534 | 0.459816 | 0.121275 | 0.117527 | 0.086200 | 0.724672 | 0.041077 | 0.792852 | ... | 0.989481 | 0.328145 | 0.843783 | 0.894061 | 0.314048 | 0.292965 | 0.305031 | 0.236982 | 0.178578 | 3.124456 |
| 65 | 赵云 | 0.926776 | 0.158741 | 0.212268 | 0.999313 | 0.060130 | 0.593934 | 0.296281 | 0.425722 | 0.665509 | ... | 0.554369 | 0.147062 | 0.121957 | 0.378483 | 0.868364 | 0.670942 | 0.700497 | 0.719190 | 0.035426 | 2.615905 |
| 20 | 关羽 | 0.155675 | 0.440437 | 0.554369 | 0.147062 | 0.121957 | 0.378483 | 0.868364 | 0.670942 | 0.700497 | ... | 0.212268 | 0.999313 | 0.060130 | 0.593934 | 0.296281 | 0.425722 | 0.665509 | 0.910555 | 0.824788 | 2.615905 |
| 135 | 张角 | 0.498340 | 0.563020 | 0.019941 | 0.686956 | 0.438963 | 0.942209 | 0.535298 | 0.068399 | 0.169205 | ... | 0.881069 | 0.376662 | 0.801466 | 0.755265 | 0.291798 | 0.938050 | 0.485826 | 0.346437 | 0.066456 | 2.136879 |
| 246 | 鲁肃 | 0.412343 | 0.426180 | 0.444081 | 0.238445 | 0.200476 | 0.665652 | 0.848165 | 0.510707 | 0.965271 | ... | 0.953005 | 0.973668 | 0.483947 | 0.904404 | 0.803289 | 0.522370 | 0.949673 | 0.096465 | 0.439397 | 1.155614 |
| 115 | 曹操 | 0.218246 | 0.707425 | 0.881069 | 0.376662 | 0.801466 | 0.755265 | 0.291798 | 0.938050 | 0.485826 | ... | 0.875218 | 0.014569 | 0.041040 | 0.406339 | 0.696076 | 0.306823 | 0.178275 | 0.006340 | 0.132899 | 1.806937 |
| 166 | 司马昭 | 0.387280 | 0.911111 | 0.361018 | 0.024711 | 0.352168 | 0.874307 | 0.560931 | 0.066454 | 0.303852 | ... | 0.953005 | 0.973668 | 0.483947 | 0.904404 | 0.803289 | 0.522370 | 0.949673 | 0.096465 | 0.439397 | 2.016103 |
| 194 | 魏延 | 0.057241 | 0.201021 | 0.491702 | 0.580754 | 0.186123 | 0.807221 | 0.324736 | 0.729737 | 0.920088 | ... | 0.688492 | 0.986374 | 0.515409 | 0.910156 | 0.170967 | 0.799865 | 0.020661 | 0.802278 | 0.424132 | 1.701496 |
| 86 | 司马懿 | 0.158174 | 0.686519 | 0.989481 | 0.328145 | 0.843783 | 0.894061 | 0.314048 | 0.292965 | 0.305031 | ... | 0.953005 | 0.973668 | 0.483947 | 0.904404 | 0.803289 | 0.522370 | 0.949673 | 0.096465 | 0.439397 | 1.376950 |
| 61 | 诸葛亮 | 0.045878 | 0.295690 | 0.875218 | 0.014569 | 0.041040 | 0.406339 | 0.696076 | 0.306823 | 0.178275 | ... | 0.953927 | 0.383384 | 0.494315 | 0.416861 | 0.089345 | 0.640795 | 0.513479 | 0.412078 | 0.759755 | 1.505521 |
15 rows × 26 columns
然后,在自表连接的时候肯定有“自己连自己的情况”
也就是name_x字段的值等于name_y
这些是无意义的数据,剔除
new_data_merge = new_data_merge[new_data_merge["name_x"] != new_data_merge["name_y"]].copy()
随机选5条清理后的数据看看
new_data_merge.sample(5)
| name_x | Java_x | Python_x | AS400_x | ITID_x | Oracle_x | Bigdata_x | SQL_x | Leadership_x | Management_x | ... | AS400_y | ITID_y | Oracle_y | Bigdata_y | SQL_y | Leadership_y | Management_y | Creativity_y | Communication_y | sim | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 114 | 曹操 | 0.218246 | 0.707425 | 0.881069 | 0.376662 | 0.801466 | 0.755265 | 0.291798 | 0.938050 | 0.485826 | ... | 0.688492 | 0.986374 | 0.515409 | 0.910156 | 0.170967 | 0.799865 | 0.020661 | 0.802278 | 0.424132 | 1.327640 |
| 37 | 张飞 | 0.138446 | 0.237509 | 0.688492 | 0.986374 | 0.515409 | 0.910156 | 0.170967 | 0.799865 | 0.020661 | ... | 0.989481 | 0.328145 | 0.843783 | 0.894061 | 0.314048 | 0.292965 | 0.305031 | 0.236982 | 0.178578 | 1.572089 |
| 156 | 姜维 | 0.866382 | 0.336534 | 0.459816 | 0.121275 | 0.117527 | 0.086200 | 0.724672 | 0.041077 | 0.792852 | ... | 0.491702 | 0.580754 | 0.186123 | 0.807221 | 0.324736 | 0.729737 | 0.920088 | 0.080613 | 0.537976 | 2.417639 |
| 92 | 司马懿 | 0.158174 | 0.686519 | 0.989481 | 0.328145 | 0.843783 | 0.894061 | 0.314048 | 0.292965 | 0.305031 | ... | 0.491702 | 0.580754 | 0.186123 | 0.807221 | 0.324736 | 0.729737 | 0.920088 | 0.080613 | 0.537976 | 1.720346 |
| 90 | 司马懿 | 0.158174 | 0.686519 | 0.989481 | 0.328145 | 0.843783 | 0.894061 | 0.314048 | 0.292965 | 0.305031 | ... | 0.361018 | 0.024711 | 0.352168 | 0.874307 | 0.560931 | 0.066454 | 0.303852 | 0.267894 | 0.524910 | 1.065205 |
5 rows × 26 columns
找每个员工与他最相似的10个员工
def get_top_student(df_sub):
# 传入的是清洗后的数据结果groupby后的子表,对应单个员工的数据
# 例如刘备与其他人连接的所有行,曹操与其他人连接的所有行
# 对这个子表按sim值,也就是相似度进行升序排序,取出前10条数据
df_sort = df_sub.sort_values(by="sim", ascending=True).head(10)
# 将前十个人的名字取出
names = ",".join(list(df_sort["name_y"]))
# 将前十个人的值相似度值取出
sims = ",".join([str(x) for x in list(df_sort["sim"])])
# 打包成Series返回给调用它的地方
return pd.Series({"names": names, "sims": sims})
对清洗后的表先按name_x进行groupby分组,对每一个分组,调用上述函数
result = new_data_merge.groupby("name_x").apply(get_top_student)
结果如下
例如,与关羽最相似的前十位依次是鲁肃,司马师,诸葛亮,刘备,曹操,魏延,姜维,徐庶,司马昭,陆逊
相似值依次是 0.7735408527877448,1.0708763430514607,1.113466...
result
| names | sims | |
|---|---|---|
| name_x | ||
| 关羽 | 鲁肃,司马师,诸葛亮,刘备,曹操,魏延,姜维,徐庶,司马昭,陆逊 | 0.7735408527877448,1.0708763430514607,1.113466... |
| 刘备 | 孙权,司马懿,陆逊,鲁肃,曹操,关羽,魏延,徐庶,司马师,司马昭 | 0.9632560988057848,0.9990413893821443,1.099269... |
| 司马师 | 司马昭,张角,鲁肃,关羽,诸葛亮,魏延,姜维,司马懿,陆逊,徐庶 | 0.5730340940360173,0.7408606894082557,0.994871... |
| 司马懿 | 曹操,陆逊,刘备,司马昭,徐庶,诸葛亮,孙权,张飞,司马师,张角 | 0.5130746529222359,0.75366469445295,0.99904138... |
| 司马昭 | 司马师,张角,司马懿,鲁肃,诸葛亮,陆逊,关羽,姜维,曹操,魏延 | 0.5730340940360173,0.9338616306533777,1.065204... |
| 姜维 | 鲁肃,司马师,赵云,关羽,司马昭,陆逊,徐庶,诸葛亮,张角,魏延 | 1.1997951508166318,1.522733479990684,1.5613112... |
| 孙权 | 刘备,鲁肃,魏延,曹操,司马懿,徐庶,司马昭,关羽,司马师,陆逊 | 0.9632560988057848,1.1556135829895424,1.206446... |
| 张角 | 司马师,司马昭,陆逊,张飞,赵云,司马懿,鲁肃,关羽,刘备,魏延 | 0.7408606894082557,0.9338616306533777,1.439048... |
| 张飞 | 徐庶,曹操,张角,司马懿,陆逊,魏延,赵云,刘备,司马师,孙权 | 1.2290138375053403,1.3276402597791603,1.527254... |
| 徐庶 | 魏延,曹操,陆逊,司马懿,张飞,刘备,诸葛亮,鲁肃,关羽,司马师 | 0.8881419714636151,1.1138655046817798,1.144920... |
| 曹操 | 司马懿,陆逊,徐庶,刘备,张飞,孙权,魏延,关羽,鲁肃,司马昭 | 0.5130746529222359,1.067403409629831,1.1138655... |
| 诸葛亮 | 关羽,司马师,鲁肃,司马懿,司马昭,徐庶,魏延,曹操,刘备,姜维 | 1.1134665626313842,1.143403490075634,1.2731639... |
| 赵云 | 姜维,张角,张飞,魏延,鲁肃,陆逊,司马师,徐庶,关羽,司马昭 | 1.561311245891365,1.5859586070097609,1.9056652... |
| 陆逊 | 司马懿,曹操,刘备,徐庶,司马昭,张角,张飞,司马师,鲁肃,关羽 | 0.75366469445295,1.067403409629831,1.099269594... |
| 魏延 | 鲁肃,徐庶,孙权,刘备,曹操,司马师,关羽,诸葛亮,张飞,司马懿 | 0.6536739741495201,0.8881419714636151,1.206446... |
| 鲁肃 | 魏延,关羽,司马师,司马昭,刘备,孙权,姜维,诸葛亮,徐庶,曹操 | 0.6536739741495201,0.7735408527877448,0.994871... |
生成excel文件,方便观看
result.to_excel("相似计算结果.xlsx", index=True)
最后,推荐蚂蚁老师的Pandas数据分析课程
课程名:《Python使用Pandas入门数据分析》
部分大纲:
扫码购买:
购买课程后,加我vx:ant_learn_python,拉付费VIP群
点击《阅读原文》,也可以到达课程页面。
评论