
SRGAN-超分辨率图像复原
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|机器学习算法工程师

github:
https://github.com/OUCMachineLearning/OUCML/blob/master/GAN/srgan_celebA/srgan.py
arxiv:
https://arxiv.org/abs/1609.04802
我的研究方向:GAN
大家好,我是中国海洋大学的陈扬。在遥远的九月份,我开始做了keras的系列教程,现在我主要的研究方向转到了生成对抗网络,生成对抗网络的代码实现和训练机制比分类模型都要复杂和难入门.之前一段时间时间一直在帮璇姐跑cvpr的实验代码,做了蛮多的对比实验,其中我就发现了,keras的代码实现和可阅读性很好,搭生成对抗网络网络GAN就好像搭乐高积木一样有趣哦。不只是demo哦,我还会在接下来的一系列 keras教程中教你搭建Alexnet,Vggnet,Resnet,DCGAN,ACGAN,CGAN,SRGAN,等等实际的模型并且教你如何在GPU服务器上运行。
上个星期发了一篇有关GAN入门的文章,同学们都觉得挺有趣的,上一次我写了如何理解最基础的GAN的原理,今天我给大家带来的是如何运用强大的GAN做一些好玩的应用.
超分辨率复原一直是计算机视觉领域一个十分热门的研究方向,在商业上也有着很大的用武之地,随着2014年goodflew那篇惊世骇俗的GAN发表出来,GAN伴随着CNN一起,可谓是乘风破浪,衍生出来琳琅满目的各种应用.
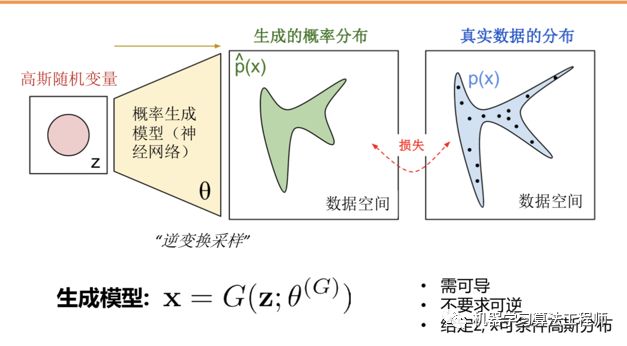
简单的来说,就给定一个低分辨率图片作为噪声z的输入,通过生成器的变换把噪声的概率分布空间尽可能的去拟合真实数据的分布空间.

在这里,我们把生成器看的目标看成是要以次充好,判别器的目标是要明辨真假.
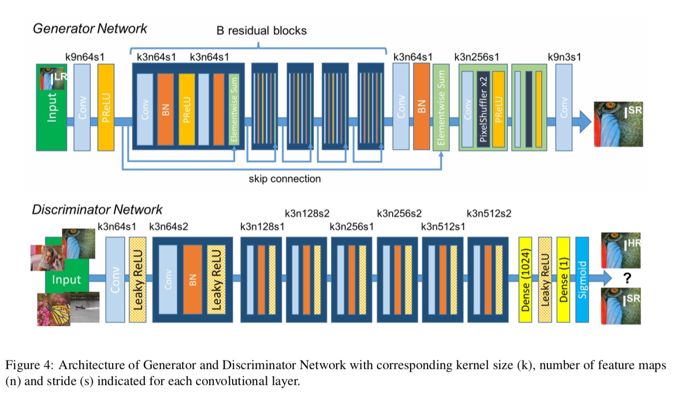
我们可以的看到,在生成器的前6层网络中,我们运用了残差块,为什么要用残差块呢?
因为我们可以从上图看出来,当损失函数从判别器开始反向传播会生成器的时候,实际上进过来很多层,我们知道越深的网络隐藏参数越多,在反向传播的过程中也越容易梯度弥散.而且残差连接的方法,就有效的保证了我们梯度信息能够有效的传递而增强生成对抗网络的鲁棒性.(事实上沃瑟斯坦loss也可以增强GAN训练的鲁棒性,以后会写)
再来聊聊今天用的数据集,这是Celeb-A,里面有大量的带标注信息的明星人脸.在目前很多的GAN的应用中,都是用CelebA作为基础的数据集,这个数据集大概在1.2G左右,可以在kaggle上下载.

浏览数据集
[https://www.kaggle.com/jessicali9530/celeba-dataset]
A popular component of computer vision and deep learning revolves around identifying faces for various applications from logging into your phone with your face or searching through surveillance images for a particular suspect. This dataset is great for training and testing models for face detection, particularly for recognising facial attributes such as finding people with brown hair, are smiling, or wearing glasses. Images cover large pose variations, background clutter, diverse people, supported by a large quantity of images and rich annotations. This data was originally collected by researchers at MMLAB, The Chinese University of Hong Kong (specific reference in Acknowledgment section).
202,599 number of face images of various celebrities
10,177 unique identities, but names of identities are not given
40 binary attribute annotations per image
5 landmark locations
简单点说,就是给你一张模糊的图片,让你复原一张高清的图片.

这个时候,我们可以把LRimg看成是一个噪声z的输入,G生成的是一个FAKE-HRimg,我们让D分辨fake-HRimg and original HRimg.
Our ultimate goal is to train a generating function G that estimates for a given LR input image its corresponding HR counterpart. To achieve this, we train a generator network as a feed-forward CNN GθG parametrized by θG. Here θG = {W1:L ; b1:L } denotes the weights and biases of a L-layer deep network and is obtained by optimizing a SR-specific
loss function lSR. For training images IHR , n = 1, . . . , N n
withcorrespondingILR,n=1,...,N,wesolve:

作者认为这更接近人的主观感受,因为使用pixel-wise的MSE使得图像变得平滑,而如果先用VGG来抓取到高级特征(feature)表示,再对feature使用MSE,可以更好的抓取不变特征。




核心公式
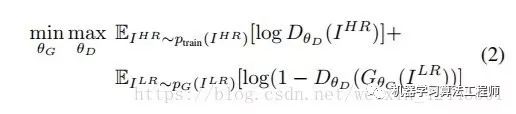
这个公式我们要分成两个部分来看,先看前半部分:

这个公式的意思是,先看加号前面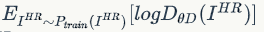 ,我们希望D最大,所以
,我们希望D最大,所以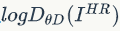 应该最大,意味着我的判别器可以很好的识别出,真实的高分辨率图像是"true",在看加号后面的
应该最大,意味着我的判别器可以很好的识别出,真实的高分辨率图像是"true",在看加号后面的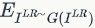 ,要让log尽可能的大,需要的是ΘD(ΘG(z))尽可能的小,意味着我们生成模型复原的图片应该尽可能的被判别模型视为"FALSE".
,要让log尽可能的大,需要的是ΘD(ΘG(z))尽可能的小,意味着我们生成模型复原的图片应该尽可能的被判别模型视为"FALSE".

再看后半部分部分
我们应该让G尽可能的小,加号前面的式子并没有G,所以无关,在看加号后面的式子
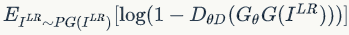
,要让ΘG尽可能地小,就要ΘD(ΘG(Z))尽可能的大,也就是说本来就一张低分辨率生成的图片,判别器却被迷惑了,以为是一张原始的高分辨率图片.这就是所谓的以次充好.
、
###vgg用于提取特征
self.vgg.compile(loss='mse',
optimizer=optimizer,
metrics=['accuracy'])
###生成器
self.combined.compile(loss=['binary_crossentropy', 'mse'],
loss_weights=[1e-3, 1],
optimizer=optimizer)
###判别器
self.discriminator.compile(loss='mse',
optimizer=optimizer,
metrics=['accuracy'])训练判别器
d_loss_real = self.discriminator.train_on_batch(imgs_hr, valid)
d_loss_fake = self.discriminator.train_on_batch(fake_hr, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)训练生成器
image_features = self.vgg.predict(imgs_hr)
# Train the generators
g_loss = self.combined.train_on_batch([imgs_lr, imgs_hr], [valid, image_features]) 5000 batchsize
5000 batchsize
、
嘻嘻嘻,大家要是喜欢这个系列的话就给我个小小的赞哦,等到我期末考考完试文件录视频来讲如何从零开始搭建生成对抗网络,emmmm现在大二学业压力确实大了,不过我们的创造会一如既往的用心做下去的,感谢你们的陪伴,也是我持续创造的动力源泉.

END
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~