
漫谈图像超分辨率技术
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作为将模糊的图像变清晰的神奇技术,图像超分辨率技术在游戏、电影、相机、医疗影像等多个领域都有广泛的应用。在这篇文章中,微软亚洲研究院的研究员们为你总结了图像超分辨率问题中的主流方法、现存问题与解决方案。微软亚洲研究院在图像超分辨率领域的相关技术也已在顶级会议发表,并转化入 PowerPoint 产品中,我们将在后续文章中为大家解读。
近年来,随着高清设备的普及,用户端显示设备的分辨率已经普遍提升到了 2K 甚至更高的水平。相对早期的游戏或电影在上述设备上往往无法得到很好的表现,这促使了很多经典游戏和电影的高清重制工作被提上日程。在整个重制过程中,最核心的就是多媒体素材的高清重建工作,而该部分工作在过去往往只能通过聘请专业的设计师耗费大量的资源来完成。
近年来,图像超分辨率技术的发展为上述问题提供了一个全新的解决思路。通过图像超分辨率技术,无需耗费大量的资源即可完成多媒体内容的高清重建工作,在上述结果上,设计师仅需进行简单少量的修改即可达到和人工设计相媲美的结果,大大简化了工作的流程,降低了工作的成本。
另一方面,图像超分辨率技术在相机拍摄过程中也有着广泛的应用。近年来,随着用户对手机拍摄功能的重视,越来越多的厂商将手机的拍摄性能作为一个重要的卖点来进行宣传。特别的,相机的变焦能力作为手机拍摄性能中的一个重要指标往往深受用户的重视,其通常可以分为两部分:光学变焦与数码变焦。其中光学变焦通过调整镜头来对焦距进行调整,由于受限于设备体积的大小,调整能力比较有限。相对的,数码变焦则是通过算法来对图像进行调整,以达到模拟光学变焦的目的,算法的优劣很大程度上决定了数码变焦的倍数以及其结果的好坏。图像超分辨率技术相对于传统的图像插值算法,往往能够提供更大的变焦倍数以及更好的图像质量,近年来广泛被各大手机厂商所采用。如图1所示,图像红框内的局部区域经过数码变焦后的结果依然清晰。

图1:通过图像超分辨率技术进行数码变焦
(左:原始焦距图像,右:数码变焦图像)
相对于上述领域,图像超分辨率技术在很多专业领域也有应用 [1]。如医疗影像领域,高质量的医疗影像(如X射线图像、计算机断层扫描图像、核磁共振图像)对于精确地诊断患者的病因起到了至关重要的作用,然而高分辨率的医疗成像设备往往非常昂贵。通过图像超分辨率技术,可以在硬件有限的条件下得到更高质量的医疗影像,在便于医生做出更加准确的诊断的同时,也进一步降低了患者的开销。
图像超分辨率是指从低分辨率图像中恢复出自然、清晰的纹理,最终得到一张高分辨率图像,是图像增强领域中一个非常重要的问题。近年来,得益于深度学习技术强大的学习能力,该问题有了显著的进展。
低分辨率图像一般通过一系列的退化操作得到,在损失了大量细节的同时,也引入了一系列的噪声。基于深度学习的超分辨率过程本质上就是通过网络模型采用成对的训练数据进行有监督学习的训练,进而拟合上述退化操作的逆操作,得到重建后的高清图像。不难想象,图像超分辨率问题是一个病态问题,对于同样一张低分辨率图像,往往存在多张可行的高分辨率图像。如图2所示,对于同一张大猩猩毛发的低分辨率图像,存在多种合理的高分辨率重建结果。
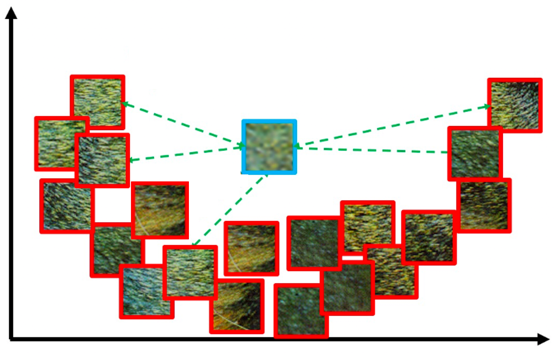
图2:同一张低分辨率图像可对应多张可行的高分辨率重建结果 [2]
目前主流的图像超分辨率技术的解决方案可以分为基于单张图像的超分辨率技术和基于参考图像的超分辨率技术,下面将分别对其展开介绍。
基于单张图像的超分辨率是指通过一张输入图像对图像中的高分辨率细节进行重建,最终得到图像超分辨率的结果,是传统图像超分辨率问题中的主流方法。
在众多方法中,SRCNN 模型 [3] 首次将卷积神经网络应用于图像超分辨率技术,相对于传统插值、优化算法在重建质量上取得了极大的提升。如图3所示,该模型使用一个三层的卷积神经网络来拟合从低分辨率图像到高分辨率图像的函数。特别地,该方法在 FSRCNN 模型 [4] 中被进一步优化,大大提升了其推理速度。
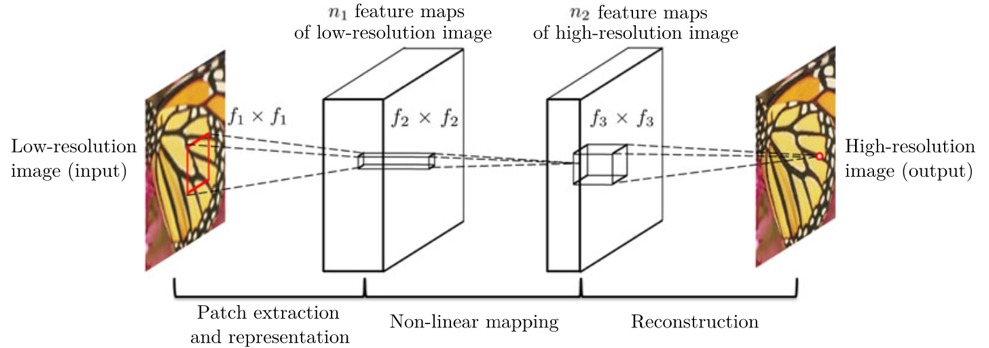
图3:SRCNN 模型中的三层卷积结构[3]
图像超分辨率过程实际上是高频纹理信息的生成过程,对于低频部分通常来源于输入的低分辨率图像。然而,SRCNN 模型的特征学习过程不仅要学习生成高频的信息,还需要对低频信息进行重建,大大的降低了模型的使用效率。针对于此,VDSR 模型 [5] 首次提出了残差学习的网络结构。如图4所示,通过一个残差连接(蓝色箭头)将输入图像直接加到最终的重建高频残差上,可以显著的提升模型的学习效率。

图4:VDSR 模型中的残差学习结构 [5]
不难发现,上述方法均是先对输入的低分辨率图像进行上采样,然后再将其送入模型行进行学习,这种做法在降低了模型的推理速度的同时也大大增加了内存的开销。如图5所示,EPSCN 模型 [6] 首次提出了子像素卷积操作,在网络的最后才将学习得到的特征进一步放大到目标大小,大大提升了模型的训练效率,也使得更深卷积通道数更多的模型的训练成为了可能。
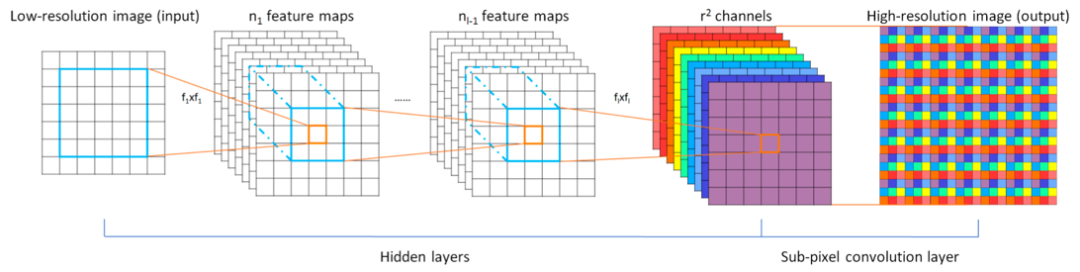
图5:ESPCN 模型中的子像素卷积操作[6]
为了进一步提升模型的表达能力,如图6所示,SRResNet 模型 [2] 首次将被广泛应用于图像分类任务中的残差模块引入到了图像超分辨率问题中,取得了很好的结果。此外,EDSR 模型 [7] 针对上述网络结构提出了进一步的优化,通过去掉残差模块中的批量归一化层和第二个激活层,进一步提升了模型的性能。
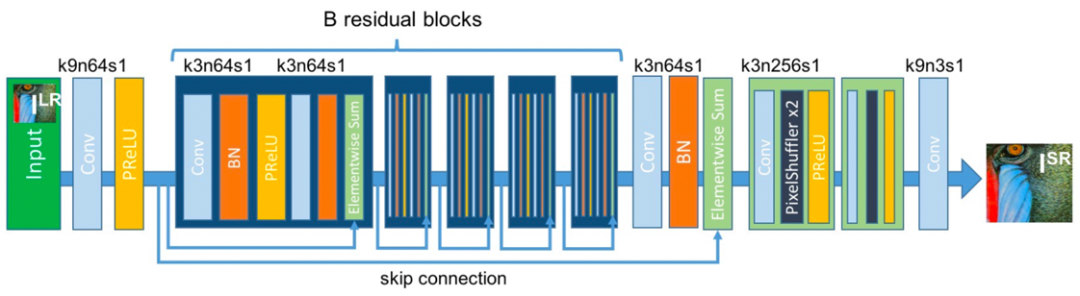
图6:SRResNet 模型中的残差模块结构 [2]
近年来,还有很多其他方法从模型的角度进行优化。如,SRDenseNet 模型 [8] 和 RDN 模型 [9] 引入了稠密卷积模块,RCAN 模型 [10] 引入了通道注意力机制,SAN 模型 [11] 引入了二阶统计信息等,上述方法均取得了非常好的结果。
如前文所述,图像超分辨率问题是一个病态的问题,通过单纯的使用平均平方误差或平均绝对误差损失函数进行训练的模型往往会输出模糊的图像。这是因为在整个训练过程中,模型的优化得到的最优解实际上是所有可行解的一个平均值。
针对上述问题,被广泛应用于图像风格迁移的感知损失函数和风格损失函数被分别引入图像超分辨率问题中 [12, 13],某种程度上缓解了上述问题。另一方面,对抗生成损失函数在图像生成模型中取得了很好的结果,SRGAN 模型 [2] 首次将其应用于图像超分辨率问题,大大的提升了重建图像的真实感。
然而上述方法仍存在一定的问题,主要是由于生成对抗网络所依赖的模型能力有限,往往很难对自然界中的全部纹理进行表达,因此在某些纹理复杂的地方会生成错误的纹理(如图7中的文字部分),带来不好的观感。

图7:基于对抗生成损失函数的错误纹理生成问题 [2]
针对单张图像超分辨率技术中生成对抗损失函数引入的错误纹理生成问题,基于参考图像的超分辨率技术为该领域指明了一个新的方向。基于参考图像的超分辨率,顾名思义就是通过一张与输入图像相似的高分辨率图像,辅助整个超分辨率的复原过程。高分辨率参考图像的引入,将图像超分辨率问题由较为困难的纹理恢复/生成转化为了相对简单的纹理搜索与迁移,使得超分辨率结果在视觉效果上有了显著的提升。
Landmark 模型 [14] 通过图像检索技术,从网络上爬取与输入图像相似的高分辨率图像,再进一步通过图像配准操作,最终合成得到对应的超分辨率结果,其算法流程如图8所示。
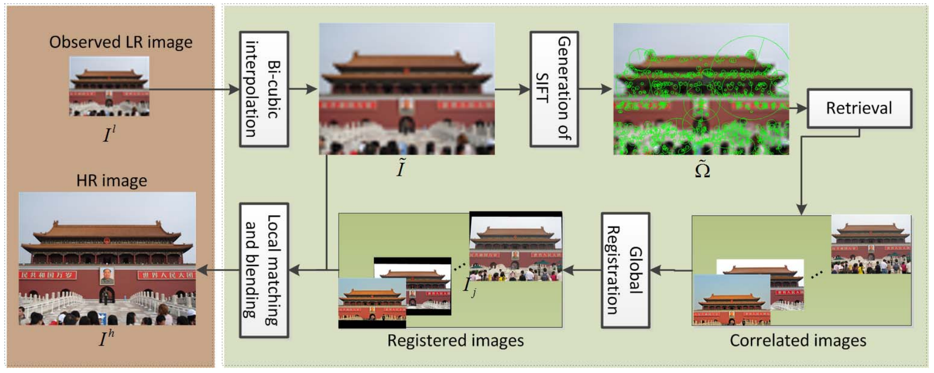
图8:Landmark 模型的算法流程图 [14]
CrossNet 模型 [15] 进一步优化上述图像配准过程,提出了基于光流估计的模型结构。如图9所示,该模型通过估计输入低分辨率图像与参考图像之间的光流来对超分辨率图像进行重建。最终结果的优劣很大程度上依赖于光流计算的准确与否,而这要求输入的低分辨率图像与参考图像在视角上不能存在很大的偏差,大大限制了上述模型的适用性。
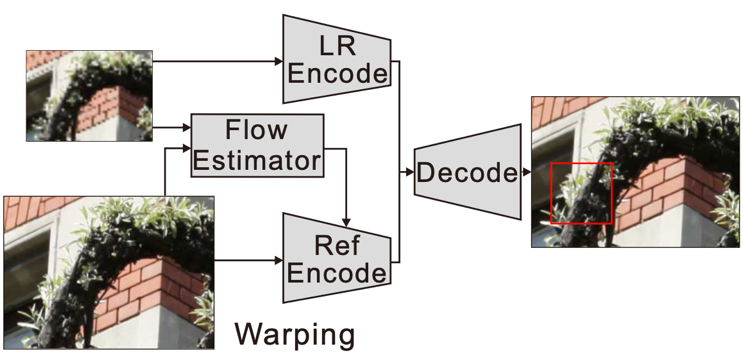
图9:CrossNet 模型的光流估计与图像编解码结构 [15]
针对上述问题,最近发表的 SRNTT 模型 [16] 提出了基于图像块的全局搜索与迁移模块,取得了非常不错的结果。该模型通过在不同尺度上对输入低分辨率图像与高分辨率参考图像中的相似图像块进行全局的搜索与迁移,上述过程可以很好地通过高分辨率的参考图像中的高频纹理对输入低分辨率图像进行表达,进而得到非常真实的超分辨率结果。
上文中提到的现有图像超分辨率技术在实际应用中仍存在较大的问题,特别是在面对分辨率较小的输入图像时(如小于200x200的图像),其得到的结果很难令人满意。另一方面,对于用户日常从网络上收集得到的图像素材,低分辨率的插图是十分常见的。直接通过上述算法得到的结果,其图像质量通常难以被用户所接受,并不能在实际的生产场景中带来很好的用户体验。
微软亚洲研究院针对这一问题提出了一套全新的图像超分辨率解决方案,在技术上全面领先的同时,该科研成果还将进一步集成进 Microsoft 365 中 PowerPoint 产品的 Design Ideas 模块中,该模块通过人工智能技术,为用户提供各种在幻灯片制作过程中的建议与帮助,提升用户幻灯片制作的效率与最终成品的质量。如图10所示,当用户插入一张低分辨率的图像时,会自动触发 Design Ideas 模块,一旦用户确认使用图像超分辨率技术进行图像增强,原始的低分辨率图像将立即被一张高分辨率的图像所替代,整个过程耗时极低,实际效果却有着很大的提升。
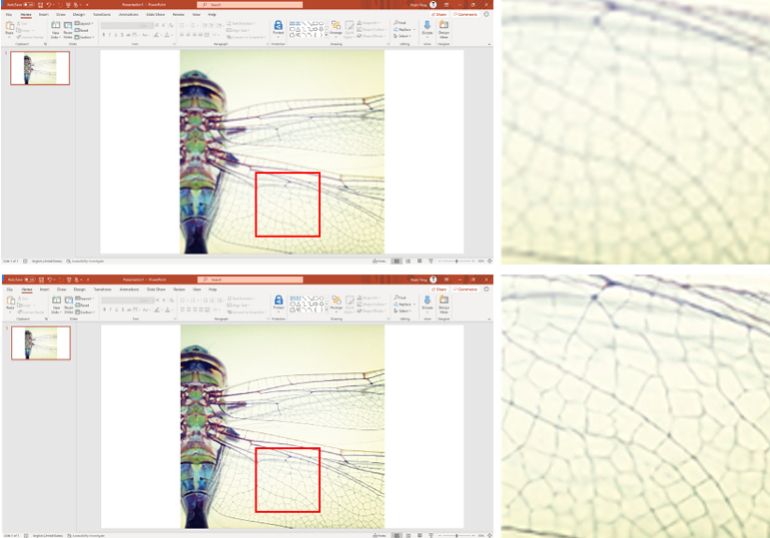
图10:通过 PowerPoint 中的 Design Ideas 模块提升用户的图像质量
(上:用户插入的低分辨率图像放大结果,下:超分辨率后图像放大结果)
很快,Microsoft 365 的用户就可以体验到这一新功能,背后的相关技术论文已经被 CVPR 2020 收录,请大家关注我们的后续文章,会为大家一一揭晓。
参考文献
[1] Oktay O , Bai W , Lee M , et al. Multi-Input Cardiac Image Super-Resolution using Convolutional Neural Networks[C]. MICCAI 2016.
[2] Ledig C , Theis L , Huszar F , et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[J]. CVPR 2017.
[3] Dong C , Loy C C , He K , et al. Image Super-Resolution Using Deep Convolutional Networks[J]. TPAMI 2016.
[4] Dong C , Loy C C , Tang X . Accelerating the Super-Resolution Convolutional Neural Network[C]. ECCV 2016.
[5] Kim J , Lee J K , Lee K M . Accurate Image Super-Resolution Using Very Deep Convolutional Networks[C]. CVPR 2016.
[6] Shi W , Caballero J , Huszár, Ferenc, et al. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network[C]. CVPR 2016.
[7] Lim B , Son S , Kim H , et al. Enhanced Deep Residual Networks for Single Image Super-Resolution[C]. CVPRW 2017.
[8] Tong T , Li G , Liu X , et al. Image Super-Resolution Using Dense Skip Connections[C]. ICCV 2017.
[9] Zhang Y , Tian Y , Kong Y , et al. Residual Dense Network for Image Super-Resolution[C]. CVPR 2018.
[10] Zhang Y , Li K , Li K , et al. Image Super-Resolution Using Very Deep Residual Channel Attention Networks[C]. CVPR 2018.
[11] Dai T , Cai J , Zhang Y, et al. Second-Order Attention Network for Single Image Super-Resolution[C]. CVPR 2019.
[12] Johnson J , Alahi A , Fei-Fei L . Perceptual Losses for Real-Time Style Transfer and Super-Resolution[C]. ECCV 2016.
[13] Sajjadi M S M , Schlkopf B , Hirsch M . EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis[C]. ICCV 2017.
[14] Yue H , Sun X , Member S , et al. Landmark Image Super-Resolution by Retrieving Web Images[J]. TIP 2013.
[15] Zheng H , Ji M , Wang H , et al. CrossNet: An End-to-end Reference-based Super Resolution Network using Cross-scale Warping[C]. ECCV 2018.
[16] Zhang Z , Wang Z , Lin Z , et al. Image Super-Resolution by Neural Texture Transfer[C]. CVPR 2019.
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~