扩散+超分辨率模型强强联合,谷歌图像生成器Imagen背后的技术
作者:Ryan O'Connor
机器之心编译
机器之心编辑部
本文详细解读了 Imagen 的工作原理,分析并理解其高级组件以及它们之间的关联。


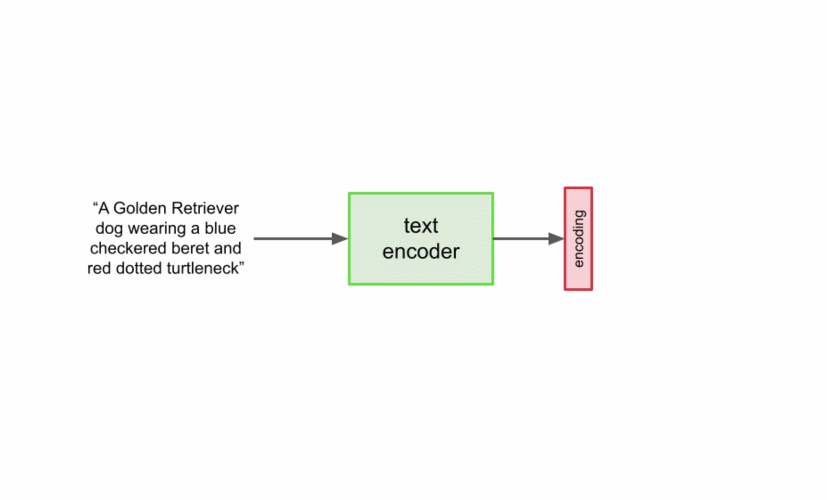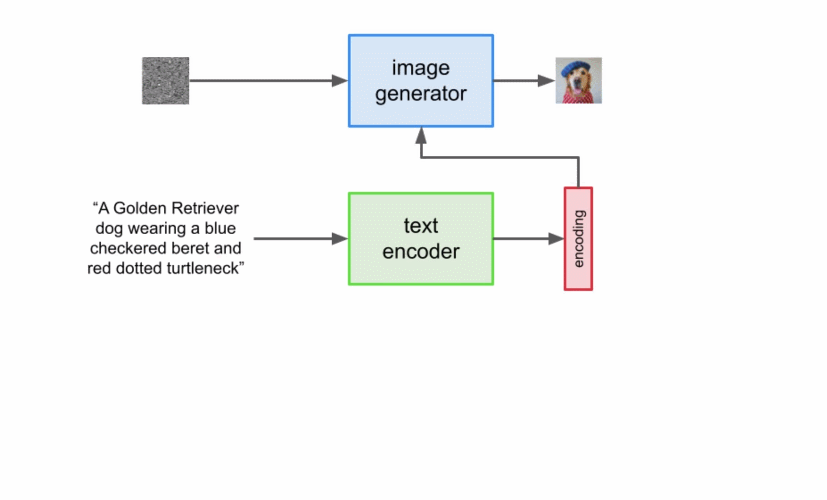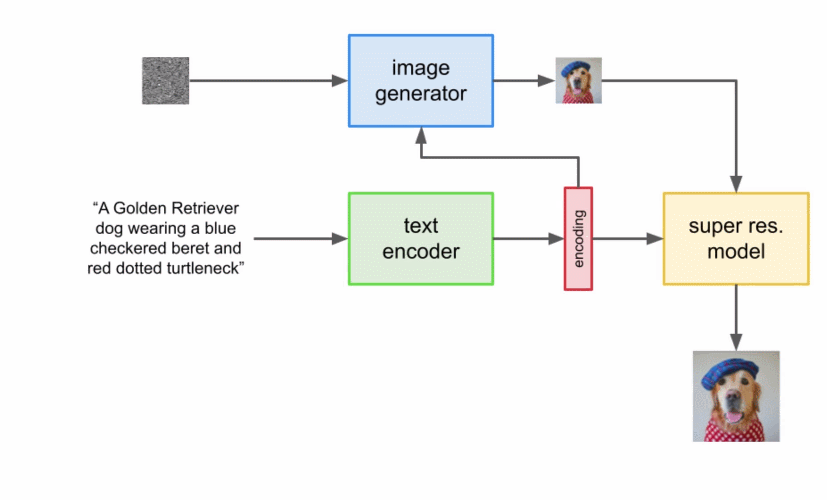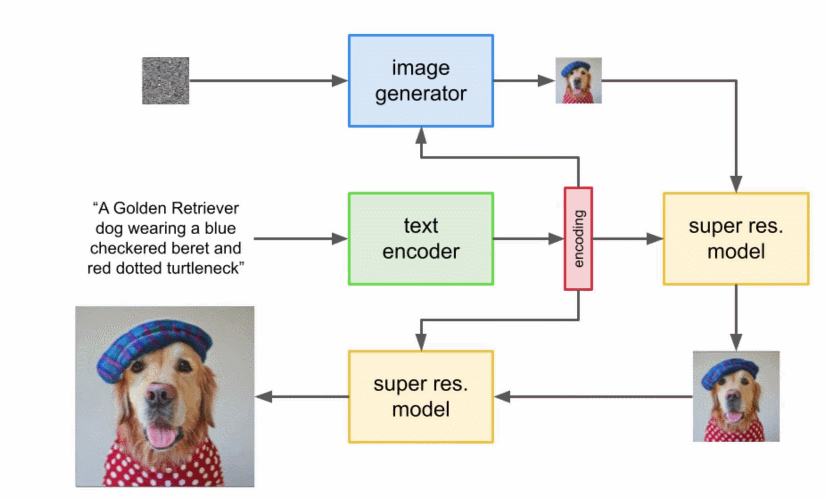



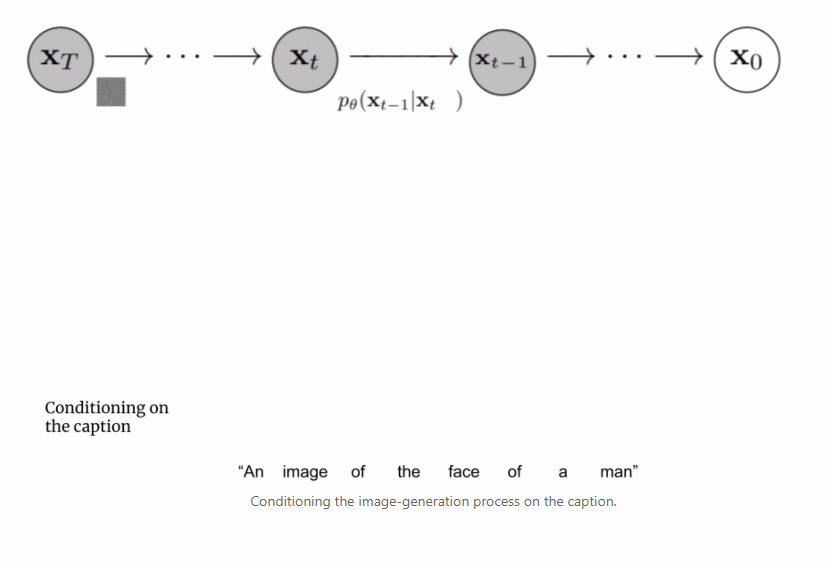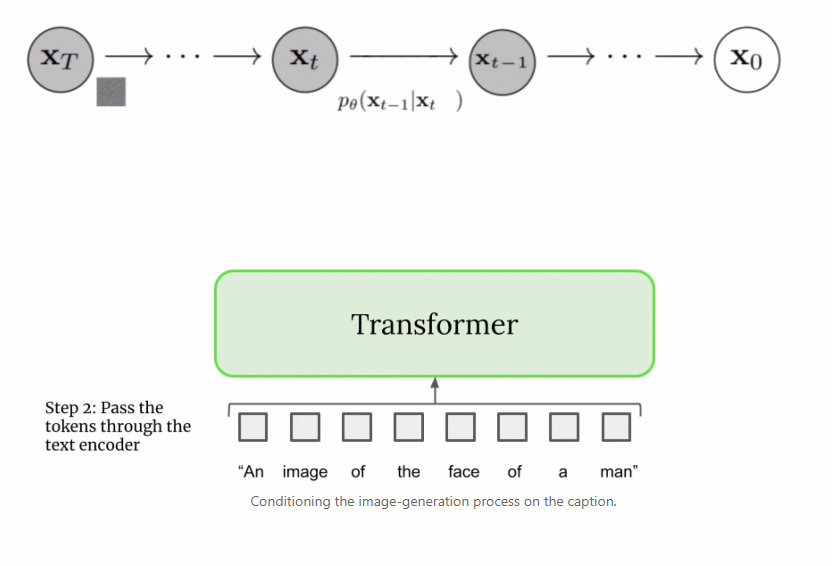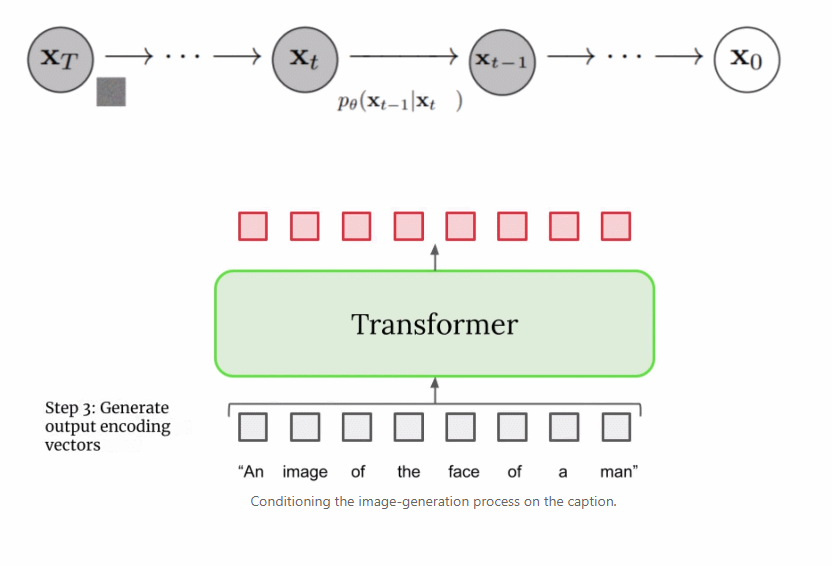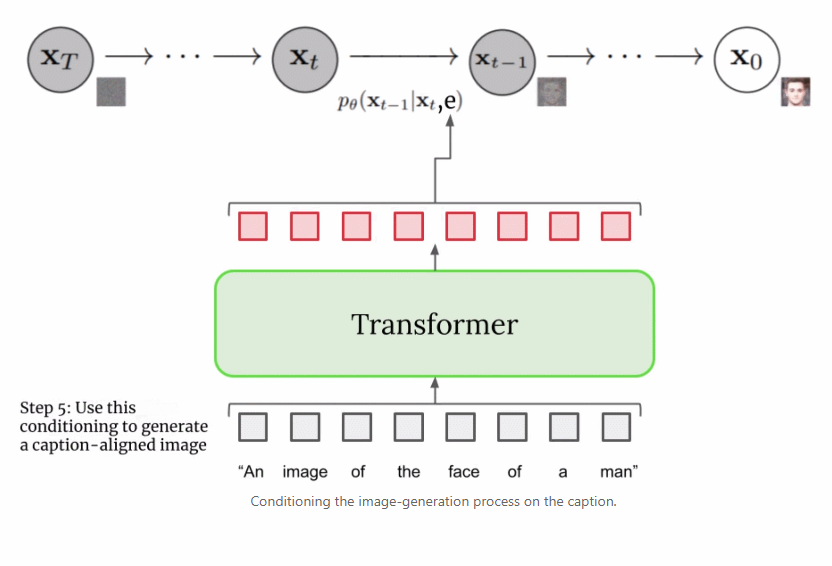
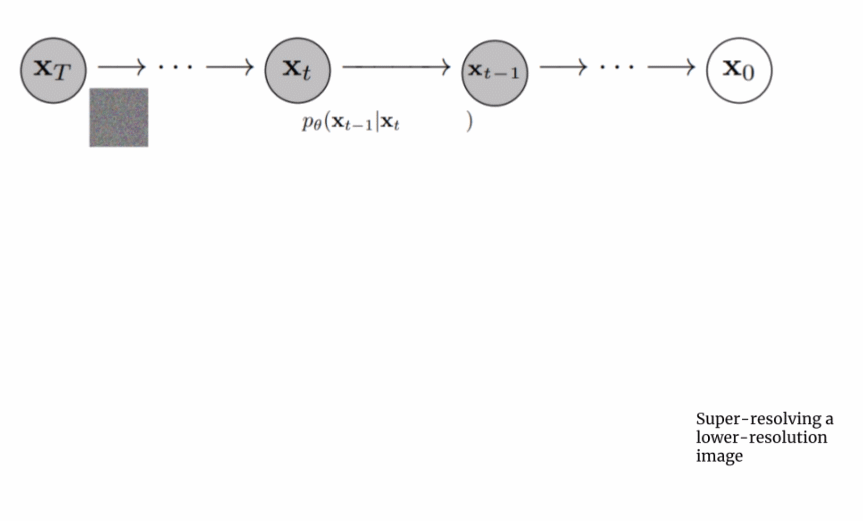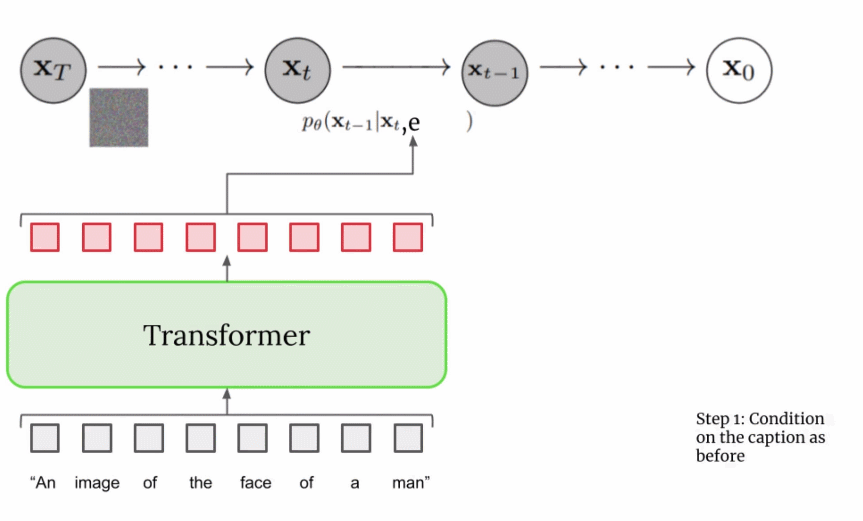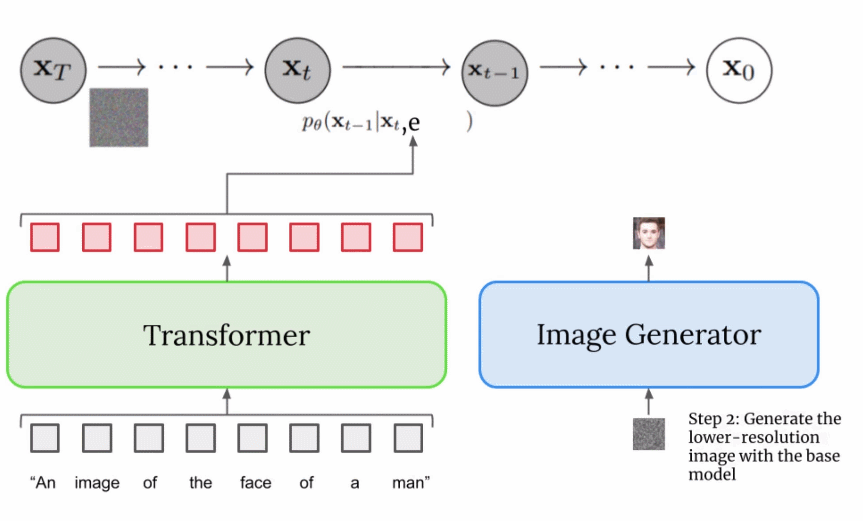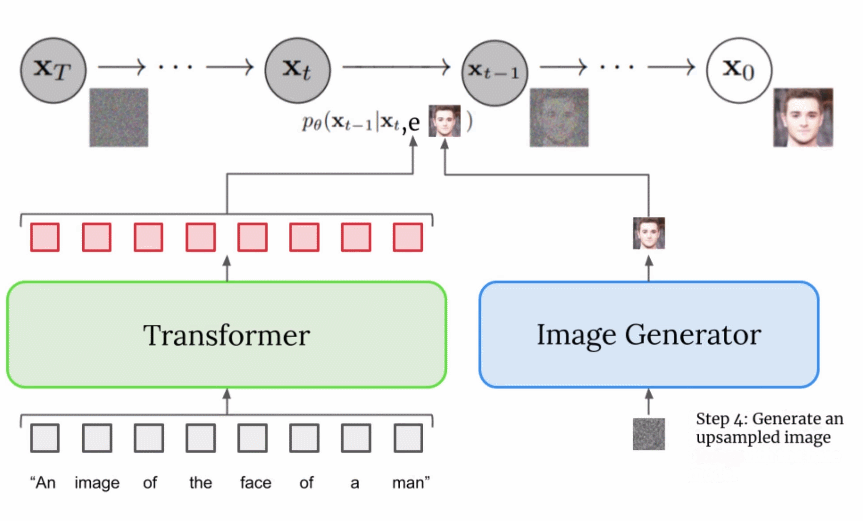
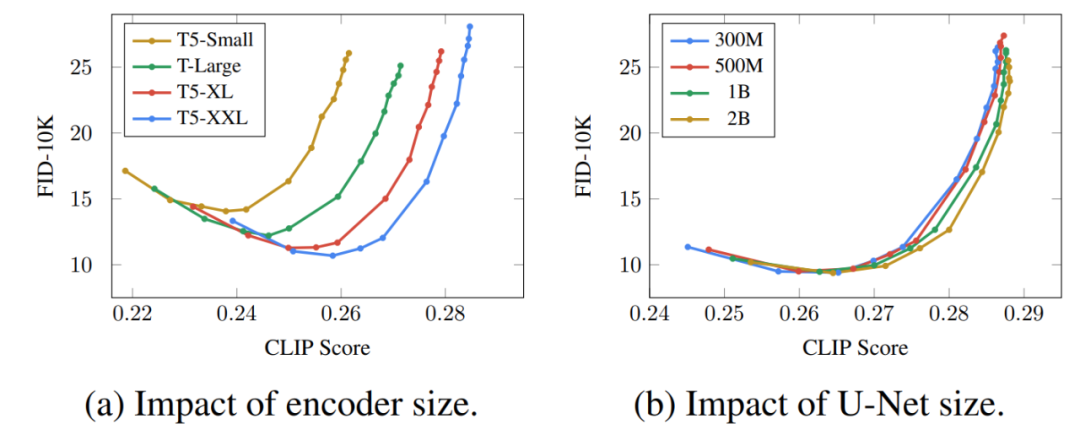
扩展文本编码器是非常有效的; 扩展文本编码器比扩展 U-Net 大小更重要; 动态阈值至关重要; 噪声条件增强在超分辨率模型中至关重要; 将交叉注意用于文本条件反射至关重要; 高效的 U-Net 至关重要。
— 完 —
评论
 下载APP
下载APP作者:Ryan O'Connor
机器之心编译
机器之心编辑部
本文详细解读了 Imagen 的工作原理,分析并理解其高级组件以及它们之间的关联。
— 完 —