
Python爬虫实战 | 只需 “4步” 入门网络爬虫(有福利哦)

什么是爬虫?
网络爬虫(Web crawler),就是通过网址获得网络中的数据、然后根据目标解析数据、存储目标信息。这个过程可以自动化程序实现,行为类似一个蜘蛛。蜘蛛在互联网上爬行,一个一个网页就是蜘蛛网。这样蜘蛛可以通过一个网页爬行到另外一个网页。

网络爬虫也是获取数据的一个途径。对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择。
根据上面的分析,我们可以把网络爬虫分为四步:
获取网页数据
解析网页数据
存储网页数据
分析网页数据
第一步:获取网页数据
获取网页数据,也就是通过网址( URL:Uniform Resource Locator,统一资源 定位符),获得网络的数据,充当搜索引擎。当输入网址,我们就相当于对网址服务器发送了一个请求,网站服务器收到以后,进行处理和解析,进而给我们一个相应的相应。如果网络正确并且网址不错,一般都可以得到网页信息,否则告诉我们一个错误代码,比如404. 整个过程可以称为请求和响应。
常见的请求方法有两种,GET和 POST。GET请求是把参数包含在了url里面,比如在百度里面输入爬虫,得到一个get 请求,链接为 https://www.baidu.com/s?wd=爬虫。而post请求大多是在表单里面进行,也就是让你输入用户名和秘密,在url里面没有体现出来,这样更加安全。post请求的大小没有限制,而get请求有限制,最多1024个字节。

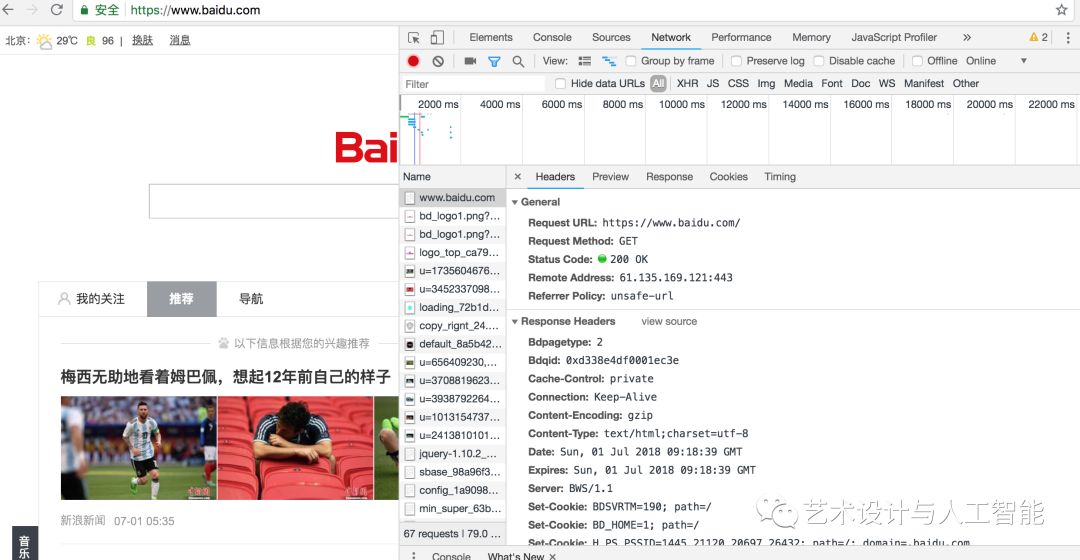
在python程序里面,上述过程可以通过获取网页中的源代码实现,进而获得网页中的数据。首先看一下网址的源代码查看方法,使用google浏览器,右键选择检查,查看需要爬取的网址源代码,具体如下:从图可得知,在Network选项卡里面,点击第一个条目,也就是www.baidu.com,看到源代码。
在本图中,第一部分是General,包括了网址的基本信息,比如状态 200等,第二部分是Response Headers,包括了请求的应答信息,还有body部分,比如Set-Cookie,Server等。第三部分是,Request headers,包含了服务器使用的附加信息,比如Cookie,User-Agent等内容。
上面的网页源代码,在python语言中,我们只需要使用urllib、requests等库实现即可,具体如下。这里特别说明一些,requests比urllib更加方便、快捷。一旦学会requests库,肯定会爱不释手。
import urllib.request
import socket
from urllib import error
try:
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.read().decode('utf-8'))
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
第二步:解析网页数据
在第一步,我们获得了网页的源代码,也就是数据。然后就是解析里面的数据,为我们的分析使用。常见的方法有很多,比如正则表达式、xpath解析等。
在Python语言中,我们经常使用Beautiful Soup、pyquery、lxml等库,可以高效的从中获取网页信息,如节点的属性、文本值等。
Beautiful Soup库是解析、遍历、维护“标签树”的功能库,对应一个HTML/XML文档的全部内容。安装方法非常简单,如下:
#安装方法
pips install beautifulsoup4
#验证方法
from bs4 import BeautifulSoup
第三步:存储网页数据
解析完数据以后,就可以保存起来。如果不是很多,可以考虑保存在txt 文本、csv文本或者json文本等,如果爬取的数据条数较多,我们可以考虑将其存储到数据库中。因此,我们需要学会 MySql、MongoDB、SqlLite的用法。更加深入的,可以学习数据库的查询优化。
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、C++、Java、JavaScript、Perl、Python等)。这些特性使JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。
JSON在python中分别由list和dict组成。Python官方json网址是 https://docs.python.org/3/library/json.html?highlight=json#module-json
具体使用方法如下:
with open('douban_movie_250.csv','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n')
第四步:分析网页数据
爬虫的目的是分析网页数据,进的得到我们想要的结论。在 python数据分析中,我们可以使用使用第三步保存的数据直接分析,主要使用的库如下:NumPy、Pandas、 Matplotlib 三个库。
NumPy :它是高性能科学计算和数据分析的基础包。
Pandas : 基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。它可以算得上作弊工具。
Matplotlib:Python中最著名的绘图系统Python中最著名的绘图系统。它可以制作出散点图,折线图,条形图,直方图,饼状图,箱形图散点图,折线图,条形图,直方图,饼状图,箱形图等。
往期实战及福利
关注本公众号,牧原小主 送您
回复“python3.7”,获得python 3.7官方最新pdf 文档
2.7G 380份最新数据分析报告
40G 人工智能算法课
已关注的小伙伴,直接回复数据分析报告、人工智能算法
关注后,回复 PM2.5 获得 Python分析北京PM2.5,原来每年的值都在变少......
关注后,回复 世界杯, 获得 2018世界杯来了,利用Python预测冠军(附全部代码和数据集)
关注后,回复“豆瓣电影“,获得 Python实战 | 手把手教你爬取豆瓣电影 Top 250(附全部代码及福利哦)
更多python爬虫实战,敬请关注期待
感谢您的阅读,祝您一天好心情!
长按二维码,关注我们