
即插即用的涨点神器,南航开源AFF:注意力特征融合

极市导读
本文介绍了一种即插即用的涨点神器——Attentional Feature Fusion(AFF)。注意力特征融合技术适用于大多数常见场景,本文详细展示了它的实现方法和实验结果。>>加入极市CV技术交流群,走在计算机视觉的最前沿

1 简介
特征融合是指来自不同层或分支的特征的组合,是现代网络体系结构中很常见的一种操作。它通常通过简单的操作(例如求和或串联)来实现,但这可能不是最佳选择。在本论文中提出了一个统一而通用的方案,即注意力特征融合,该方案适用于大多数常见场景,包括由short and long skip connections以及在Inception层内的特征融合。
为了更好地融合语义和尺度不一致的特征,提出了一个多尺度的通道注意力模块,该模块解决了在融合不同尺度的特征时出现的问题。同时还通过添加另一个注意力级别(称为迭代注意力特征融合)来缓解特征图的初始集成的瓶颈。
2 相关工作
2.1、Multi-scale Attention Mechanism
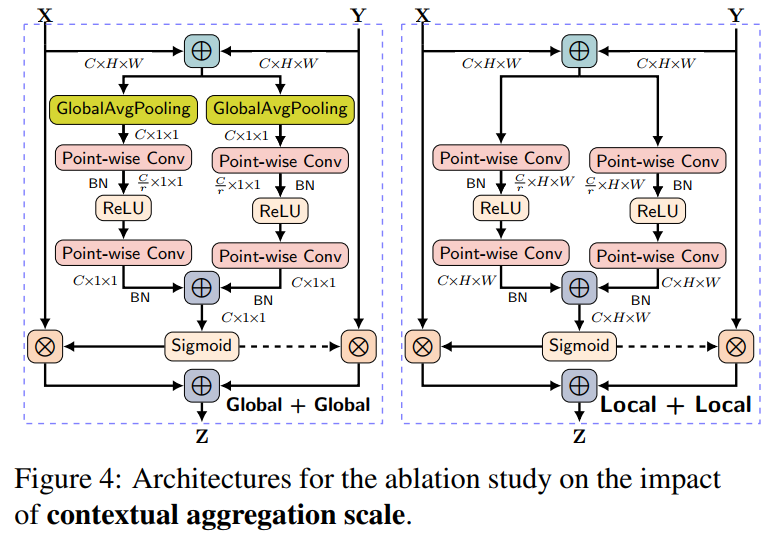
第1类:将多个尺度上的特征或它们连接的结果输入注意模块生成多尺度上的Faeture map,注意模块内上下文聚合的特征尺度要保持统一。 第2类:也被称为多尺度空间注意,通过大小不同的卷积核或从注意模块内的金字塔聚集上下文的特征。
1)、MS-CAM通过逐点卷积来关注通道的尺度问题,而不是大小不同的卷积核。 2)、MS-CAM不是在主干网中,而是在通道注意力模块中局部本地和全局的特征上下文特征。
2.2、Skip Connections in Deep Learning
3 本文方法:MS-CAM
3.1、Multi-Scale Channel Attention Module(MS-CAM)
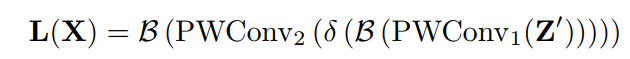
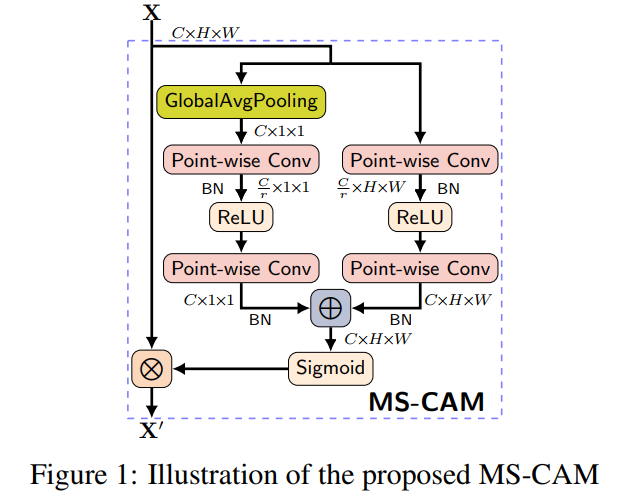
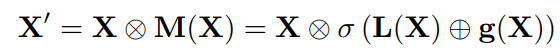
class ResGlobLocaChaFuse(HybridBlock):
def __init__(self, channels=64):
super(ResGlobLocaChaFuse, self).__init__()
with self.name_scope():
self.local_att = nn.HybridSequential(prefix='local_att')
self.local_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.local_att.add(nn.BatchNorm())
self.global_att = nn.HybridSequential(prefix='global_att')
self.global_att.add(nn.GlobalAvgPool2D())
self.global_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.global_att.add(nn.BatchNorm())
self.sig = nn.Activation('sigmoid')
def hybrid_forward(self, F, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = F.broadcast_add(xl, xg)
wei = self.sig(xlg)
xo = 2 * F.broadcast_mul(x, wei) + 2 * F.broadcast_mul(residual, 1-wei)
return xo
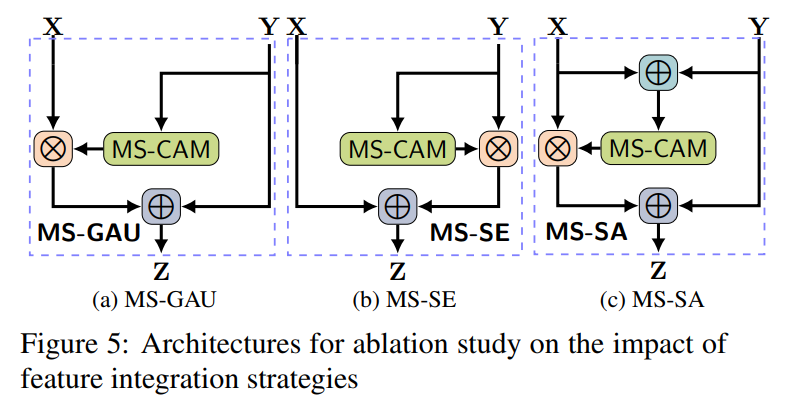
4 模块
4.1、AFF模块
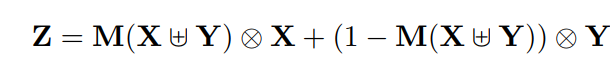
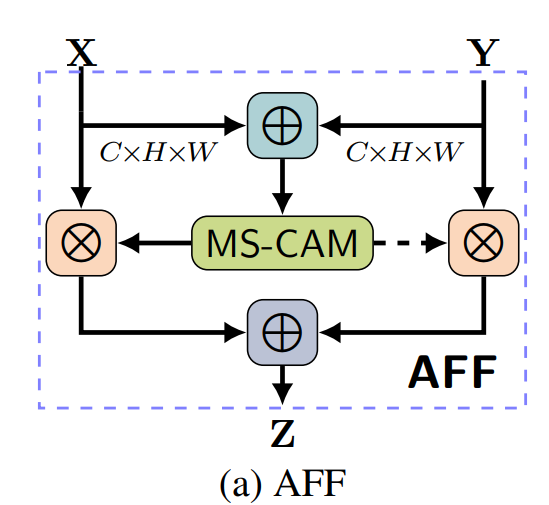
class AXYforXplusYAddFuse(HybridBlock):
def __init__(self, channels=64):
super(AXYforXplusYAddFuse, self).__init__()
with self.name_scope():
self.local_att = nn.HybridSequential(prefix='local_att')
self.local_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.local_att.add(nn.BatchNorm())
self.global_att = nn.HybridSequential(prefix='global_att')
self.global_att.add(nn.GlobalAvgPool2D())
self.global_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.global_att.add(nn.BatchNorm())
self.sig = nn.Activation('sigmoid')
def hybrid_forward(self, F, x, residual):
xi = x + residual
xl = self.local_att(xi)
xg = self.global_att(xi)
xlg = F.broadcast_add(xl, xg)
wei = self.sig(xlg)
xo = F.broadcast_mul(wei, residual) + x
return xo
4.2、iAFF模块
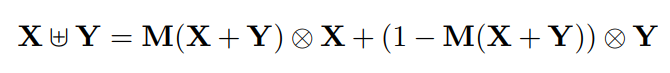
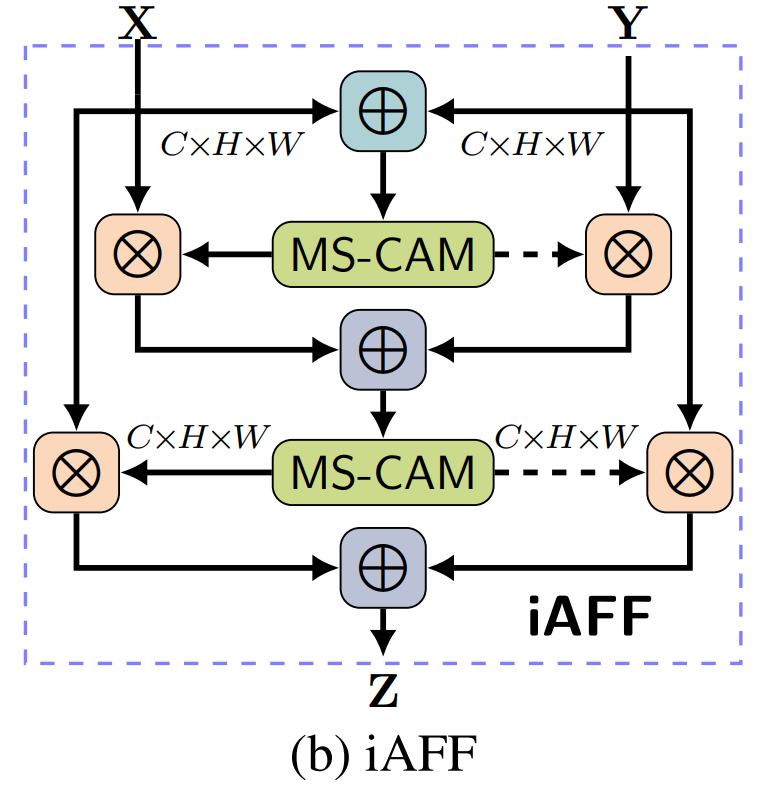
class AXYforXYAddFuse(HybridBlock):
def __init__(self, channels=64):
super(AXYforXYAddFuse, self).__init__()
with self.name_scope():
self.local_att = nn.HybridSequential(prefix='local_att')
self.local_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.local_att.add(nn.BatchNorm())
self.global_att = nn.HybridSequential(prefix='global_att')
self.global_att.add(nn.GlobalAvgPool2D())
self.global_att.add(nn.Conv2D(channels, kernel_size=1, strides=1, padding=0))
self.global_att.add(nn.BatchNorm())
self.sig = nn.Activation('sigmoid')
def hybrid_forward(self, F, x, residual):
xi = x + residual
xl = self.local_att(xi)
xg = self.global_att(xi)
xlg = F.broadcast_add(xl, xg)
wei = self.sig(xlg)
xo = F.broadcast_mul(wei, xi)
return xo
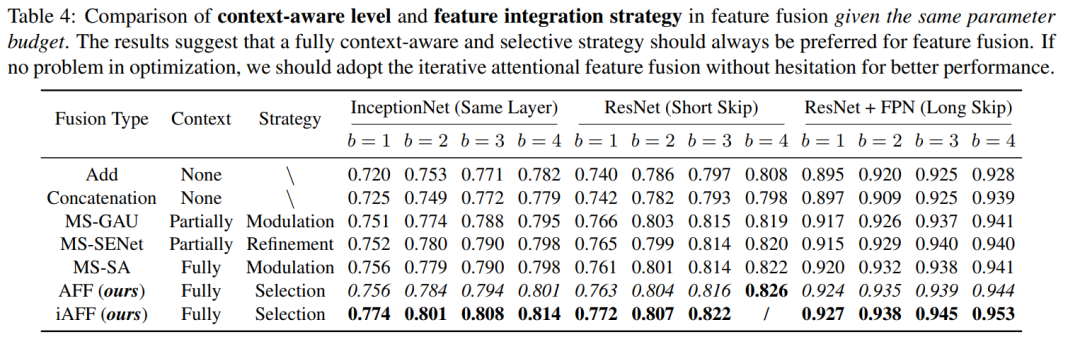
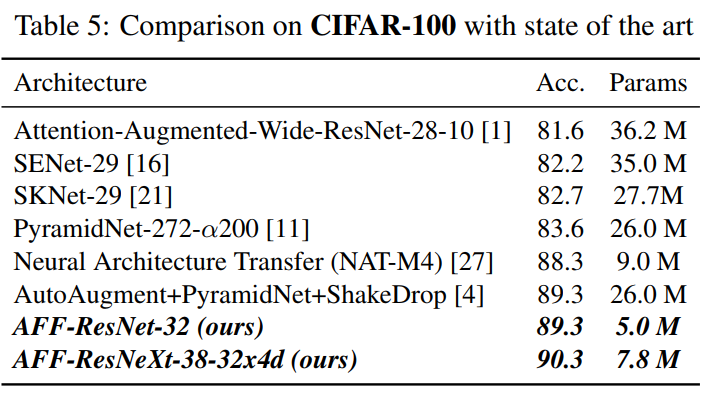
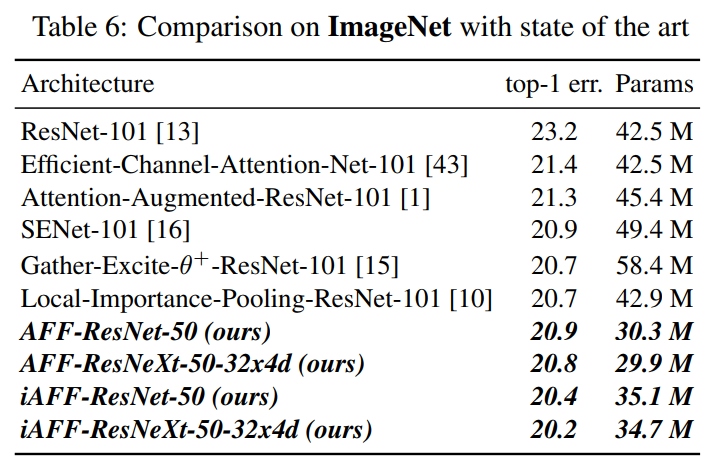
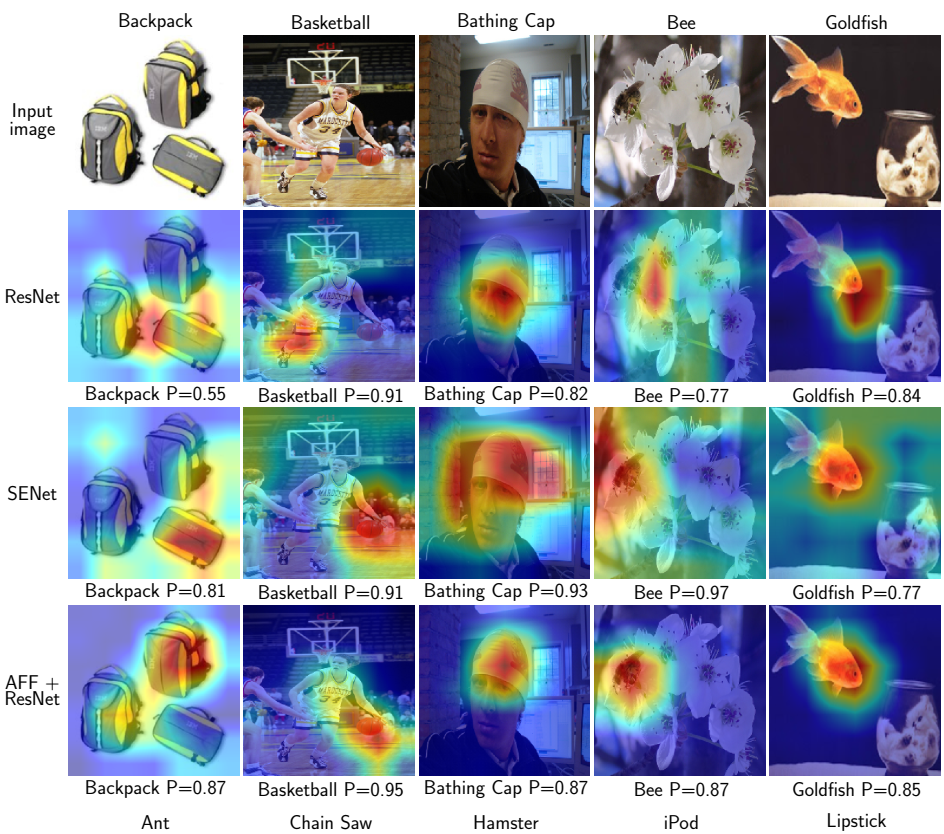
5 实验和可视化结果

推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!

评论