
ECCV2020 | 即插即用,涨点明显!FPT:特征金字塔Transformer
共 3816字,需浏览 8分钟
·
2020-08-08 10:39
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

这篇文章收录于ECCV2020,将Transformer机制应用于对特征金字塔FPN的改进上,整体思路新颖,和之前的将Transformer应用于目标检测、语义分割、超分辨率等任务的思想相类似,是一个能够继续挖掘的方向。
论文地址:https://arxiv.org/abs/2007.09451
代码地址:https://github.com/ZHANGDONG-NJUST/FPT
跨空间和尺度的特征交互是现代视觉识别系统的基础,因为它们引入了有益的视觉环境。通常空间上下文信息被动地隐藏在卷积神经网络不断增加的感受野中,或者被non-local卷积主动地编码。但是,non-local空间交互作用并不是跨尺度的,因此它们无法捕获在不同尺度中的对象(或部分)的非局部上下文信息。为此,本文提出了一种在空间和尺度上完全活跃的特征交互,称为特征金字塔Transformer(FPT)。它通过使用三个专门设计的Transformer,以自上而下和自下而上的交互方式,将任何一个特征金字塔变换成另一个同样大小但具有更丰富上下文的特征金字塔。FPT作为一个通用的视觉框架,具有合理的计算开销。最后,本文在实例级(即目标检测和实例分割)和像素级分割任务中进行了广泛的实验,使用不同的主干和头部网络,并观察到比所有baseline和最先进的方法一致的改进。
简介
现代视觉识别系统与上下文息息相关。由于卷积神经网络(CNN)的层次结构,如图1(a)所示,通过pooling池化、stride或空洞卷积等操作,将上下文编码在逐渐变大的感受野(绿色虚线矩形)中。因此,对最后一个特征图的预测基本上是基于丰富的上下文信息。
Scale also matters。尺度scale也很重要,传统的解决方案是对同一图像进行堆积多尺度的图像金字塔,其中较高/较低的层次采用较低/较高分辨率的图像进行输入。因此,不同尺度的物体在其相应的层次中被识别。然而,图像金字塔增加了CNN前向传递的耗时,因为每个图像都需要一个CNN来识别。幸运的是,CNN提供了一种特征金字塔FPN,即通过低/高层次的特征图代表高/低分辨率的视觉内容,而不需要额外的计算开销。如图1(b)所示,可以通过使用不同级别的特征图来识别不同尺度的物体,即小物体(电脑)在较低层级中识别,大物体(椅子和桌子)在较高层级中识别。
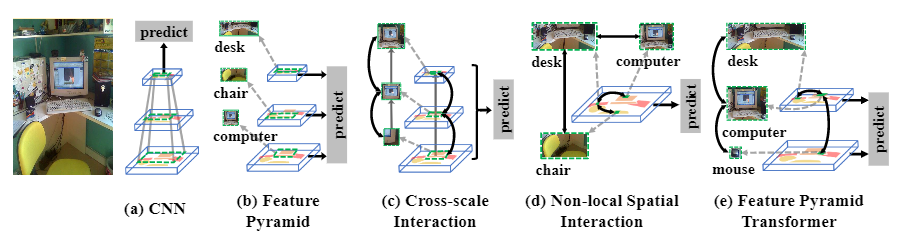
Sometimes the recognition——尤其是像语义分割这样的像素级标签,需要结合多个尺度的上下文。例如图1(c)中,要对显示的帧区域的像素赋予标签,也许从较低的层次上看,实例本身的局部上下文就足够了;但对于类外的像素,需要同时利用局部上下文和较高层次的全局上下文。
为此,本文提出了一种称为特征金字塔转换器Transformer(FPT)的新颖特征金字塔网络,用于视觉识别任务,例如实例级(即目标检测和实例分割)和像素级分割任务。简而言之,如图2所示,FPT的输入是一个特征金字塔,而输出是一个变换的金字塔,其中每个level都是一个更丰富的特征图,它编码了跨空间和尺度的非局部non-local交互作用。然后,可以将特征金字塔附加到任何特定任务的头部网络。顾名思义,FPT中特征之间的交互采用了 transformer-style。它具有整洁的查询query,键key和值value操作,在选择远程信息进行交互时非常有效,从而可以调整我们的目标:以适当的规模进行非局部non-local交互。另外,像其他任何transformer模型一样,使用TPU可以减轻计算开销。
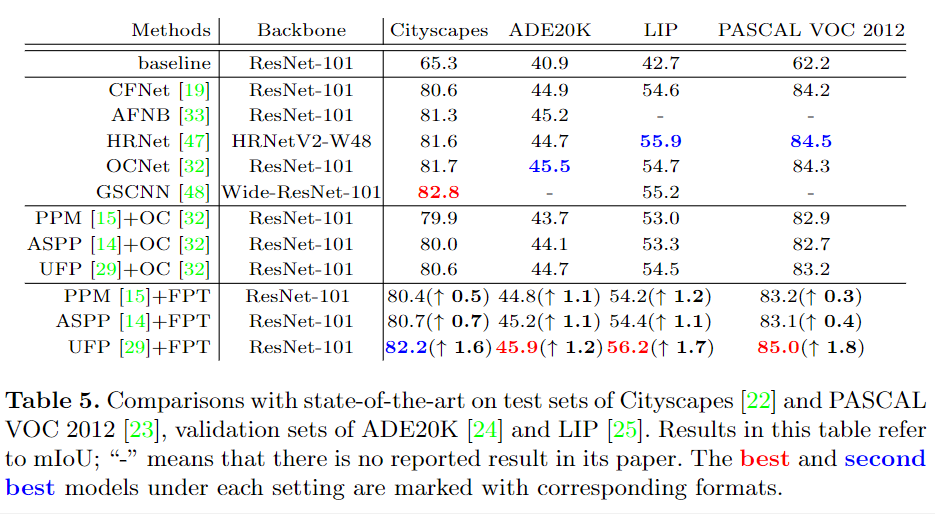
大量的实验表明,FPT可以极大地改善传统的检测/分割网络:1)在MS-COCO test-dev数据集上,用于框检测的百分比增益为8.5%,用于遮罩实例的mask AP值增益为6.0%;2)对于语义分割,分别在Cityscapes和PASCAL VOC 2012 测试集上的增益分别为1.6%和1.2%mIoU;在ADE20K 和LIP 验证集上的增益分别为1.7%和2.0%mIoU。
本文方法
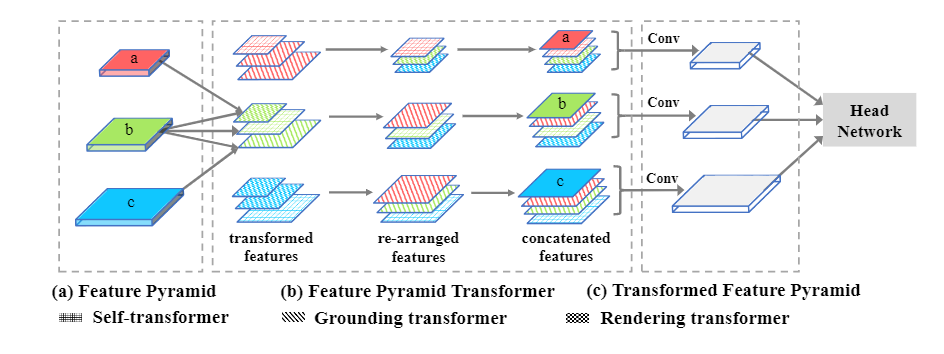
图2. 本文提出的FPT网络的总体结构。不同的纹理图案表示不同的特征转换器,不同的颜色表示具有不同比例的特征图。“ Conv”表示输出尺寸为256的3×3卷积。在不失一般性的前提下,顶层/底层特征图没有rendering/grounding 转换器。
如图2的FPT分解图所示,主要是是三种transformer的设计:1)自变换器Self-Transformer(ST)。它是基于经典的同级特征图内的非局部non-local交互,输出与输入具有相同的尺度。2)Grounding Transformer(GT)。它是以自上而下的方式,输出与下层特征图具有相同的比例。直观地说,将上层特征图的 "概念 "与下层特征图的 "像素 "接地。特别是,由于没有必要使用全局信息来分割对象,而局部区域内的上下文在经验上更有参考价值,因此,还设计了一个locality-constrained的GT,以保证语义分割的效率和准确性。3)Rendering Transformer(RT)。它是以自下而上的方式,输出与上层特征图具有相同的比例。直观地说,将上层 "概念 "与下层 "像素 "的视觉属性进行渲染。这是一种局部交互,因为用另一个远处的 "像素 "来渲染一个 "对象 "是没有意义的。每个层次的转换特征图(红色、蓝色和绿色)被重新排列到相应的地图大小,然后与原始map连接,然后再输入到卷积层,将它们调整到原始 "厚度"。
1、Non-Local Interaction Revisited
传统的Non-Local Interaction
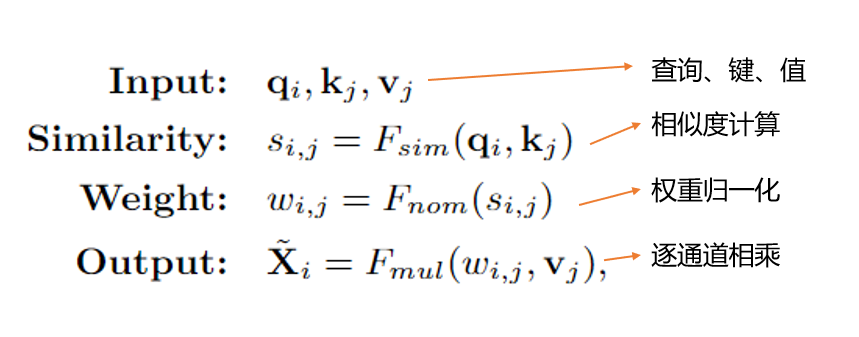
2、Self-Transformer
自变换器(Self-Transformer,ST)的目的是在同一张特征图上捕获共同发生的对象特征。如图3(a)所示,ST是一种修改后的非局部non-local交互,输出的特征图与其输入特征图的尺度相同。与其他方法区别在于,作者部署了Mixture of Softmaxes(MoS)作为归一化函数,事实证明它比标准的Softmax在图像上更有效。具体来说,首先将查询q和键k划分为N个部分。然后,使用Fsim计算每对图像的相似度分数。基于MoS的归一化函数Fmos表达式如下:

自变换器可以表达为:

3、Grounding Transformer
Grounding Transformer(GT)可以归类为自上而下的非局部non-local交互,它将上层特征图Xct中的 "概念 "与下层特征图Xf中的 "像素 "进行对接。输出特征图与Xf具有相同的尺度。一般来说,不同尺度的图像特征提取的语义或语境信息不同,或者两者兼而有之。此外,根据经验,当两个特征图的语义信息不同时,euclidean距离的负值比点积更能有效地计算相似度。所以我们更倾向于使用euclidean距离Fedu作为相似度函数,其表达方式为:
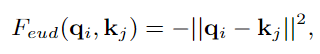
于是,Grounding Transformer可以表述为:

在特征金字塔中,高/低层次特征图包含大量全局/局部图像信息。然而,对于通过跨尺度特征交互的语义分割,没有必要使用全局信息来分割图像中的两个对象。从经验上讲,查询位置周围的局部区域内的上下文会提供更多信息。这就是为什么常规的跨尺度交互(例如求和和级联)在现有的分割方法中有效的原因。如图3(b)所示,它们本质上是隐式的局部non-local样式,但是本文的默认GT是全局交互的。
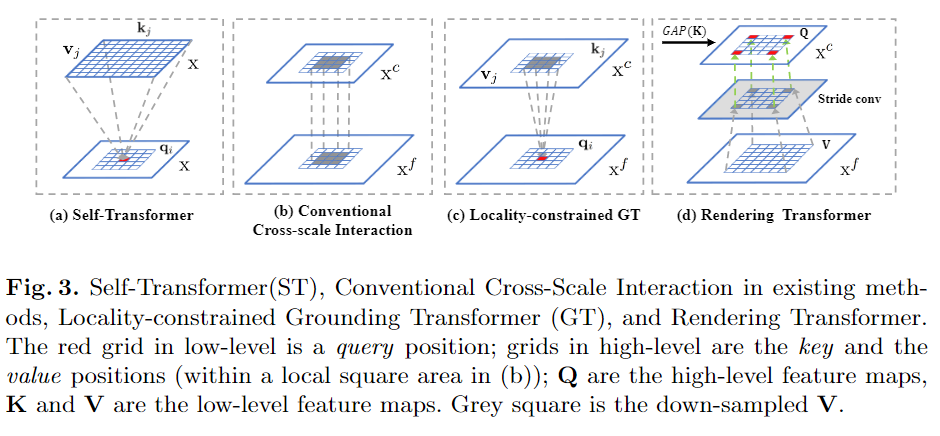
Locality-constrained Grounding Transformer。因此,作者引入了局域性GT转换进行语义分割,这是一个明确的局域特征交互作用。如图3(c)所示,每个q(即低层特征图上的红色网格)在中心区域的局部正方形区域内与k和v的一部分(即高层特征图上的蓝色网格)相互作用。坐标与q相同,边长为正方形。特别是,对于k和v超出索引的位置,改用0值。
4、Rendering Transformer
Rendering Transformer(RT)以自下而上的方式工作,旨在通过将视觉属性合并到低层级“像素”中来渲染高层级“概念”。如图3(d)所示,RT是一种局部交互,其中该局部是基于渲染具有来自另一个遥远对象的特征或属性的“对象”是没有意义的这一事实。
在本文的实现中,RT不是按像素进行的,而是按整个特征图进行的。具体来说,高层特征图定义为Q,低层特征图定义为K和V,为了突出渲染目标,Q和K之间的交互是以通道导向的关注方式进行的,K首先通过全局平均池化(GAP)计算出Q的权重w。然后,加权后的Q(即Qatt)通过3×3卷积进行优化,V通过3×3卷积与步长来缩小特征规模(图3(d)中的灰色方块)。最后,将优化后的Qatt和下采样的V(即Vdow)相加,再经过一次3×3卷积进行细化处理。
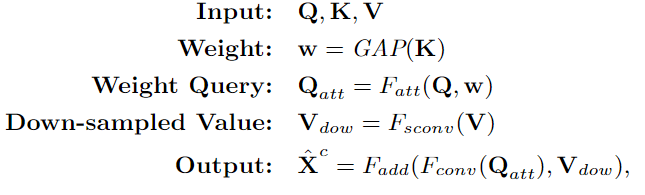
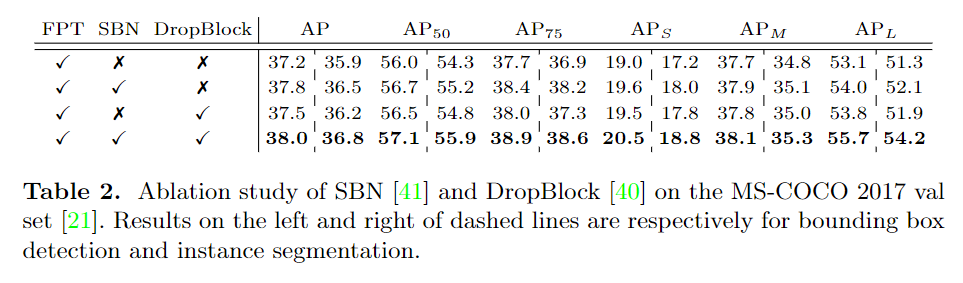
消融实验:

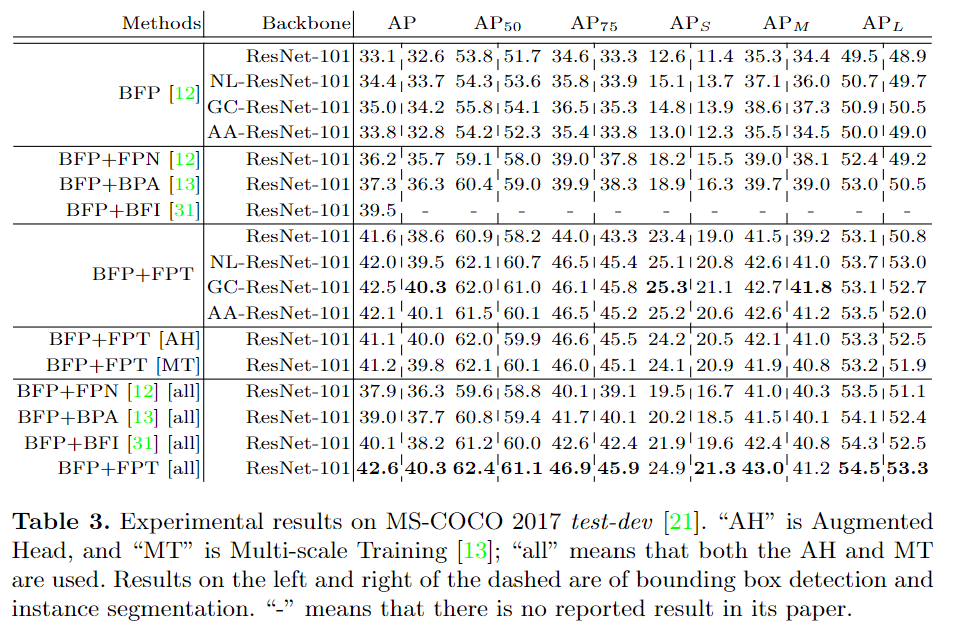
对比实验
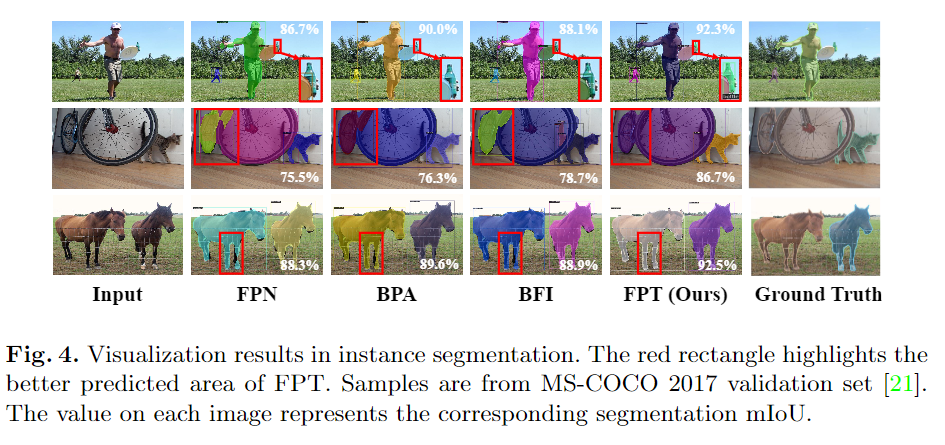
可视化对比
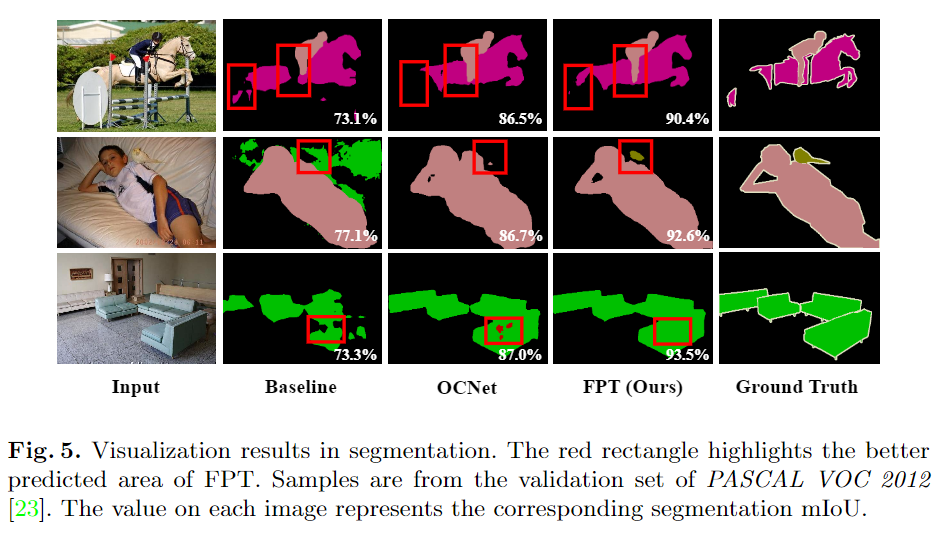


更多细节可参考论文原文。
