本文盘点了6月22日以来关于“即插即用”网络模块的重要论文,共计10篇,相信能对大家的科研工作有所帮助。
前言
最近出现了很多"即插即用"的网络模块,比如用来替换传统的卷积层,可以使你的网络轻松涨点!
本文就来盘点一下近期(6.22-至今)较为亮眼的论文,也许对你目前的科研工作会有所帮助,或者有所启发。有意思的是Amusi统计出正好10篇论文,其实每一篇都可以单独写出文章来分享,但这里汇总成大盘点系列,方便做对比和参考。1 DO-Conv
替换传统卷积!阿里等提出DO-Conv:Depthwise Over-parameterized卷积层DO-Conv: Depthwise Over-parameterized Convolutional Layer
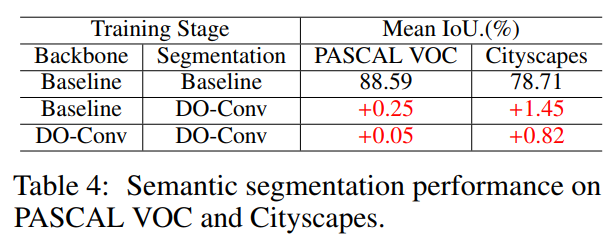
代码:https://github.com/yangyanli/DO-Conv论文:https://arxiv.org/abs/2006.12030仅用DO-Conv层替换常规卷积层就可以提高CNN在许多经典视觉任务(如分类,目标检测和分割等)上的性能。PyTorch、TF和GluonCV版本代码刚刚开源!卷积层是卷积神经网络(CNN)的核心构建模块。在本文中,我们提出通过附加的depthwise卷积来增强卷积层,其中每个输入通道都使用不同的2D kernel进行卷积。两个卷积的组成构成了over-parameterization,因为它增加了可学习的参数,而生成的线性运算可以由单个卷积层表示。我们将此depthwise over-parameterized卷积层称为DO-Conv。我们通过大量实验表明,仅用DO-Conv层替换常规卷积层就可以提高CNN在许多经典视觉任务(例如图像分类,检测和分割)上的性能。此外,在推理阶段,深度卷积被折叠为常规卷积,从而使计算量精确地等于卷积层的计算量,而没有over-parameterization。由于DO-Conv引入了性能提升,而不会导致推理的计算复杂性增加,因此我们提倡将其作为传统卷积层的替代方法。
2 PyConv
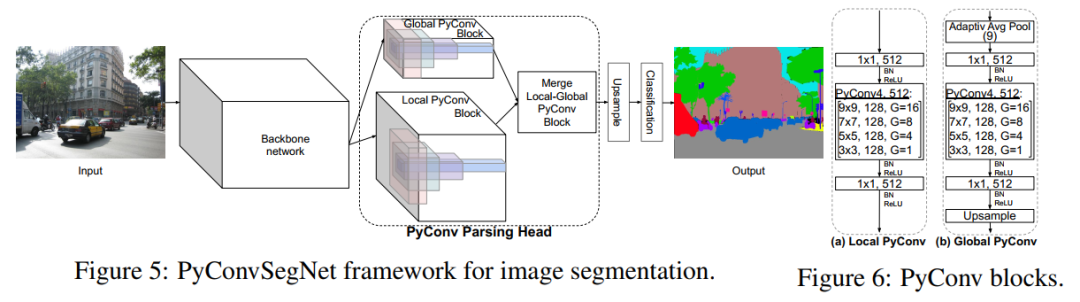
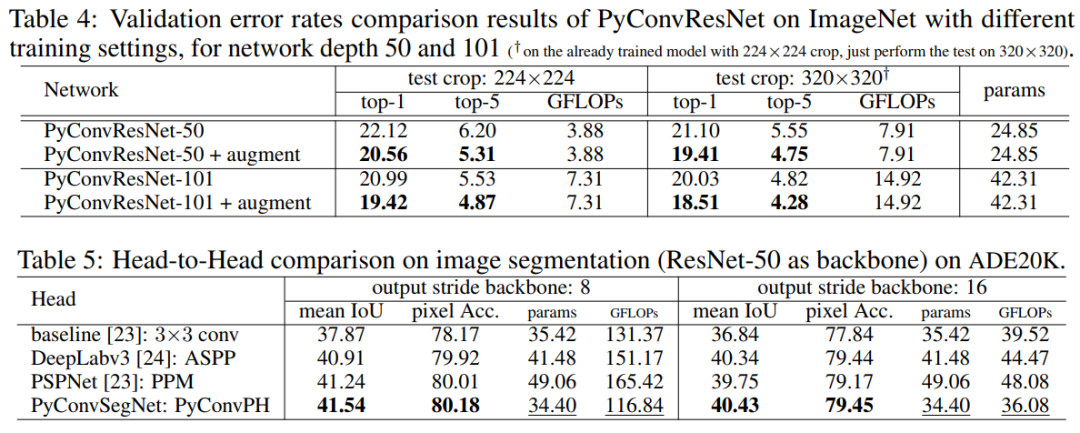
金字塔卷积(PyConv):重新思考用于视觉任务的卷积神经网络Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition代码:https://github.com/iduta/pyconv论文:https://arxiv.org/abs/2006.11538PyConv具有影响几乎所有计算机视觉任务的潜力,如分类PyConvResNet、分割PyConvSegNet,检测PyConvSSD等,在提高性能的同时(涨点明显),不增加计算量和参数,代码刚刚开源!这项工作引入了金字塔卷积(PyConv),它能够在多个filter尺度上处理输入。PyConv包含一个kernel金字塔,其中每个level涉及大小和深度不同的不同类型的filters,它们能够捕获场景中不同level的细节。除了这些改进的识别功能之外,PyConv还是高效的,并且按照我们的公式,与标准卷积相比,它不会增加计算成本和参数。而且,它非常灵活和可扩展,为不同的应用提供了大量的潜在网络体系结构。
PyConv具有影响几乎所有计算机视觉任务的潜力,在这项工作中,我们针对视觉识别的四个主要任务提出了基于PyConv的不同体系结构:图像分类,视频动作分类/识别,目标检测和语义图像分割/解析。与基线相比,我们的方法显示出对所有这些核心任务的显著改进。例如,在图像识别方面,我们的50层网络在ImageNet数据集上的识别性能优于其具有152层的对应基准ResNet,同时参数减少了2.39倍,计算复杂度降低了2.52倍,层减少了3倍以上。在图像分割方面,我们新颖的框架为具有挑战性的场景解析ADE20K基准设置了新的技术。
PyConv 在图像分类、语义分割等任务上的性能表现:
3 GENet
涨点神器!GENet(组集成网络):在单个ConvNet中学习ConvNet的集成Group Ensemble: Learning an Ensemble of ConvNets in a single ConvNet
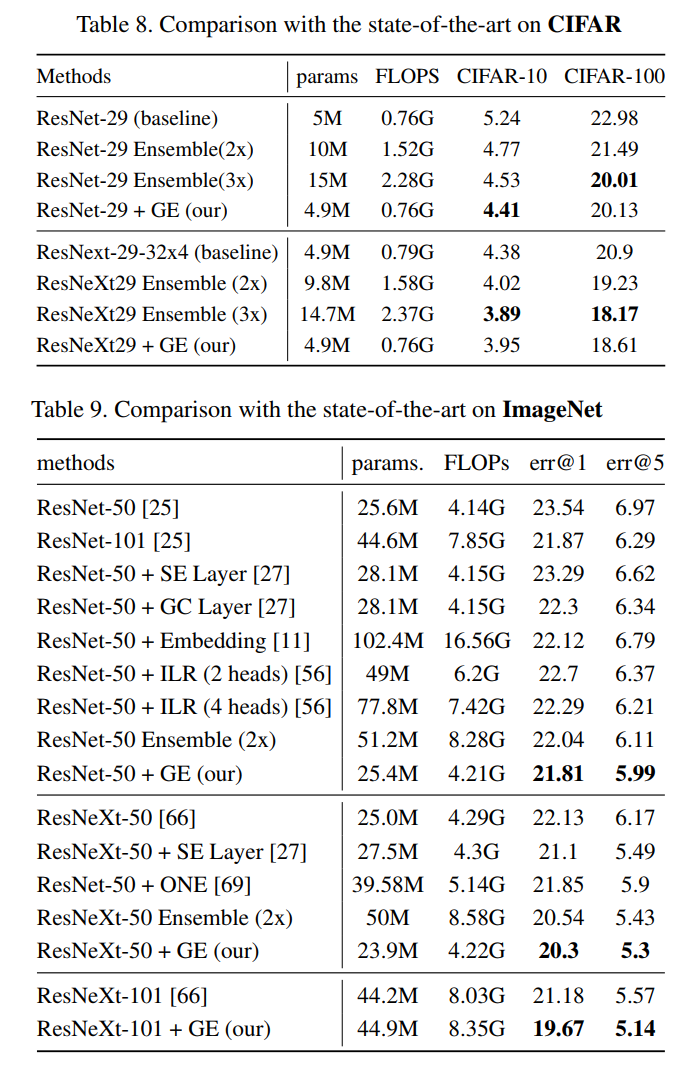
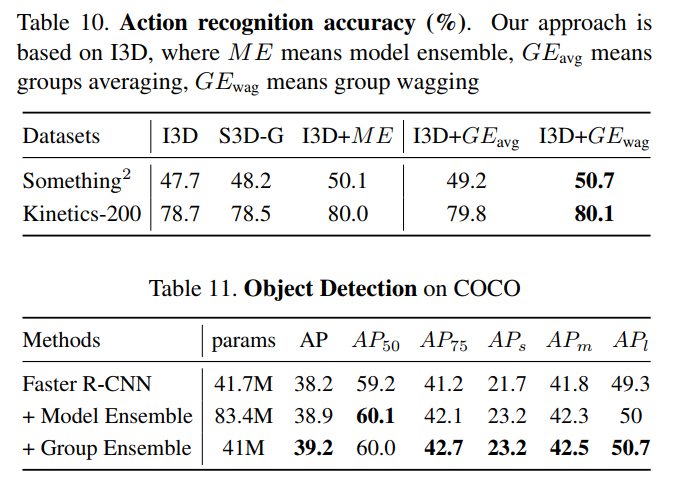
论文:https://arxiv.org/abs/2007.00649ResNet-50 + GE从原23.54降低至21.81错误率,ResNeXt-50 + GE从原 22.13降低至20.3错误率,还可应用于其他CV任务,如目标检测、行为识别等。集成学习是提高机器学习准确性的通用技术。但是,ConvNets集合的繁重计算限制了其在深度学习中的使用。在本文中,我们介绍了组集成网络(GENet),一种将ConvNet集成到单个ConvNet中的体系结构。通过基于共享和多头的结构,GENet被分为几个组,以使在单个ConvNet中进行显式的集成学习成为可能。由于分组卷积和共享库,GENet可以充分利用显式集成学习的优势,同时保留与单个ConvNet相同的计算。此外,我们将“组平均”,“组Wagging”和“组Boosting”作为三种不同的策略来汇总这些成员。最后,GENet优于大型单一网络,小型网络的标准集成以及CIFAR和ImageNet上的其他最新技术。具体来说,对于ImageNet上的ResNeXt-50,group ensemble将top-1错误减少1.83%。我们还将展示其在行为识别和目标检测任务上的有效性。GENet 在图像分类、目标检测和行为识别等任务上的性能表现:4 ULSAM
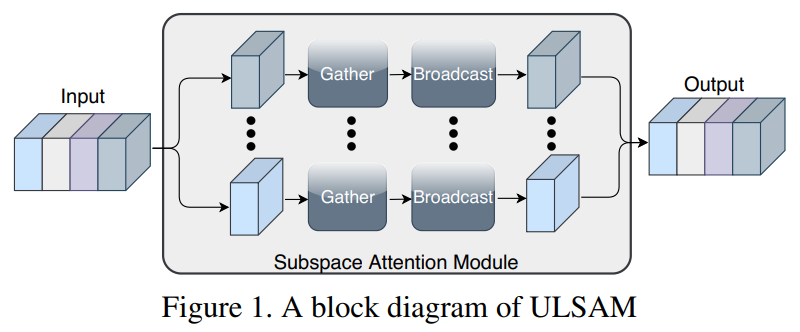
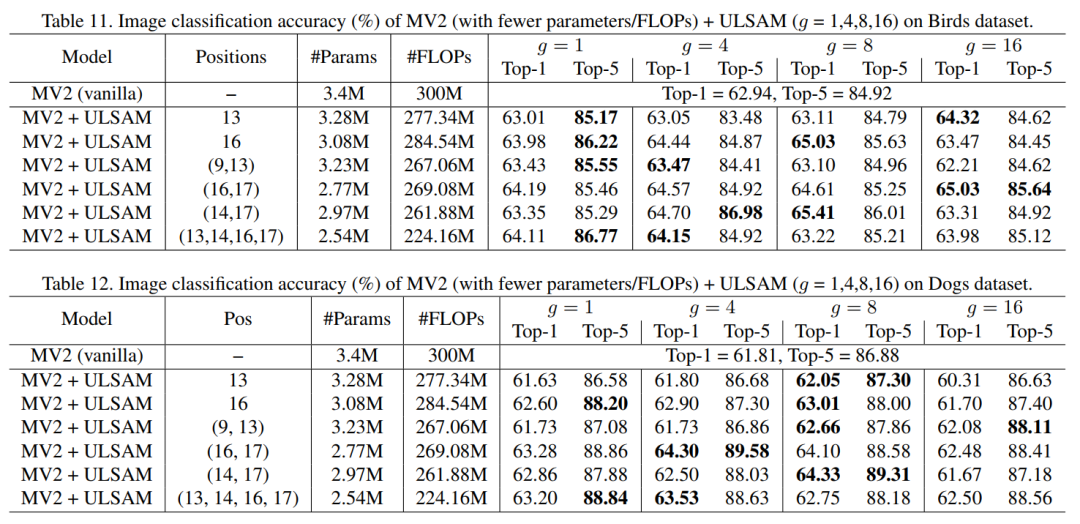
ULSAM:用于紧凑型CNN的超轻量级子空间注意力模块ULSAM: Ultra-Lightweight Subspace Attention Module for Compact Convolutional Neural Networks代码:https://github.com/Nandan91/ULSAM论文:https://arxiv.org/abs/2006.15102即插即用!首次尝试使用子空间注意力机制来提高紧凑型CNN的效率,并提高细粒度图像分类性能,如MobileNetV2 + ULSAM,其FLOP和参数减少的同时,准确率提高,代码现已开源!自注意力机制对long-range依赖关系进行建模的能力已使其在视觉模型中的部署迅速发展。与卷积运算符不同,自注意力提供了无限的感受野,并实现了对全局依赖关系的高效计算建模。但是,现有的最新注意力机制会导致较高的计算和/或参数开销,因此不适合紧凑型卷积神经网络(CNN)。在这项工作中,我们提出了一个简单而有效的“超轻量子空间注意力机制”(ULSAM),它为每个特征图子空间推断出不同的注意力图。我们认为,针对每个特征子空间倾斜单独的注意力图可以实现多尺度和多频率的特征表示,这对于细粒度的图像分类而言更为理想。我们的子空间注意方法是正交的,并且与视觉模型中使用的现有最新注意机制互补。ULSAM可进行端到端训练,并且可以作为现成的紧凑型CNN中的即插即用模块进行部署。值得注意的是,我们的工作是首次尝试使用子空间注意力机制来提高紧凑型CNN的效率。为了显示ULSAM的功效,我们使用MobileNet-V1和MobileNet-V2作为ImageNet-1K和三个细粒度图像分类数据集的主干架构进行了实验。在ImageNet-1K和细粒度图像分类数据集上,我们分别使MobileNet-V2的FLOP和参数计数减少了约13%和约25%,在top-1准确性方面分别提高了0.27%和1%以上。)。5 Sandglass block
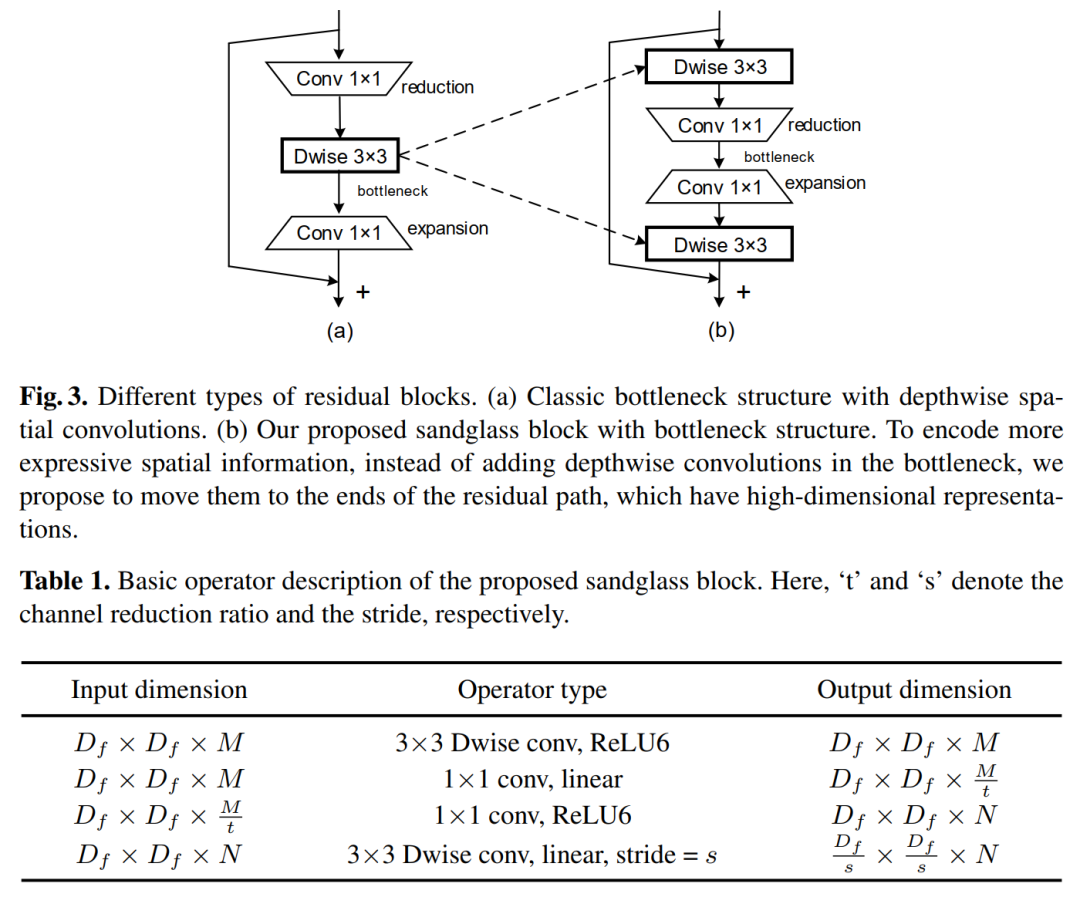
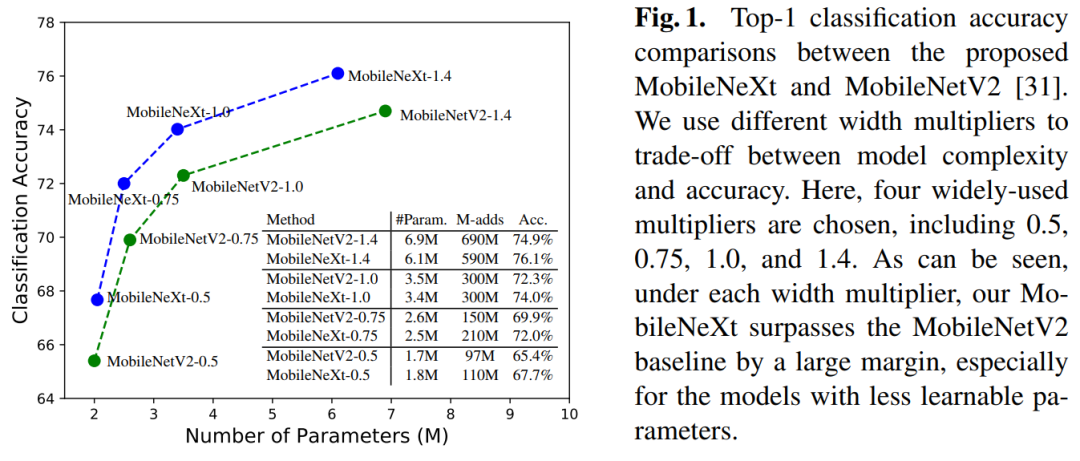
重新思考高效移动网络设计的Bottleneck结构(ECCV 2020)Rethinking Bottleneck Structure for Efficient Mobile Network Design代码:https://github.com/zhoudaquan/rethinking_bottleneck_design论文:https://arxiv.org/abs/2007.02269用sandglass block替换Inverted Residual Block,如提出MobileNeXt 性能优于EfficientNet、GhostNet和FBNet等网络,代码即将开源!最近,反向残差模块在移动网络的架构设计中占主导地位。通过引入两个设计规则,它改变了经典的残差bottleneck:学习反向残差和使用线性bottleneck。在本文中,我们重新考虑了这种设计更改的必要性,发现它可能带来信息丢失和梯度混淆的风险。因此,我们提出翻转结构并提出一种新颖的瓶颈设计,称为“沙漏块(sandglass block)”,该设计在更高的维度上执行标识映射和空间变换,从而有效地减轻了信息丢失和梯度混淆的麻烦。大量的实验表明,与通常的看法不同,这种瓶颈结构比倒置的瓶颈对移动网络更有利。在ImageNet分类中,只需简单地用我们的沙漏块替换 inverted residual block,而无需增加参数和进行计算,则与MobileNetV2相比,分类精度可以提高1.7%以上。在Pascal VOC 2007测试集上,我们观察到目标检测的mAP也提高了0.9%。通过将其添加到神经体系结构搜索方法DARTS的搜索空间中,我们进一步验证了沙漏块的有效性。通过减少25%的参数,分类精度比以前的DARTS模型提高了0.13%。6 DGC
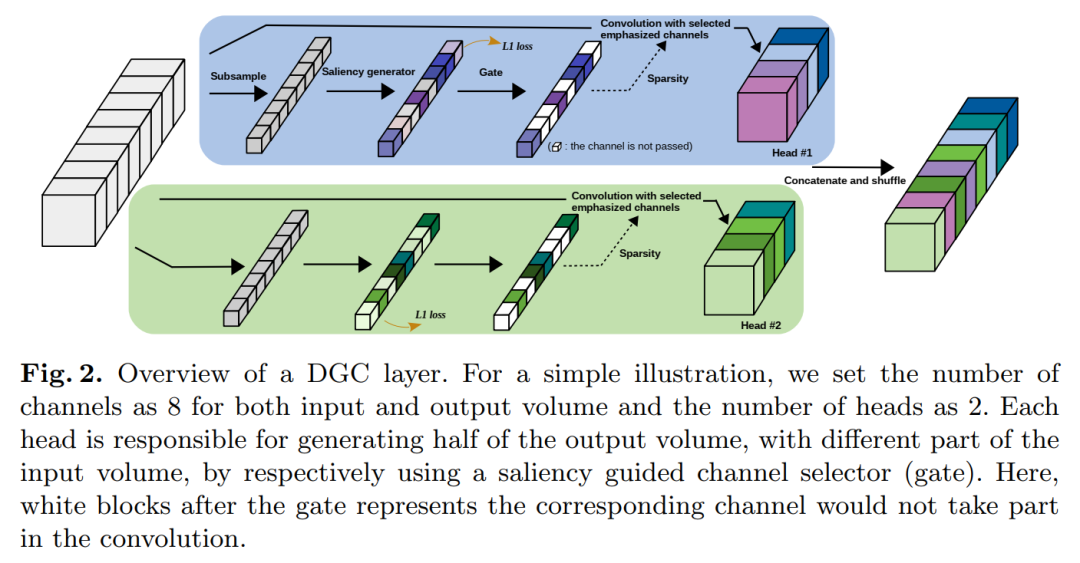
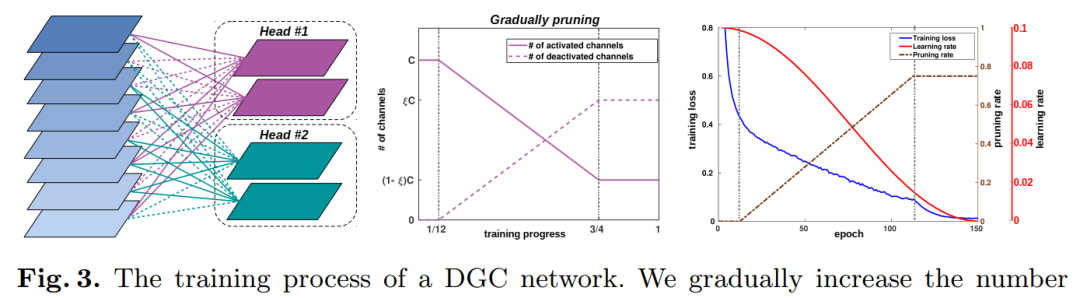
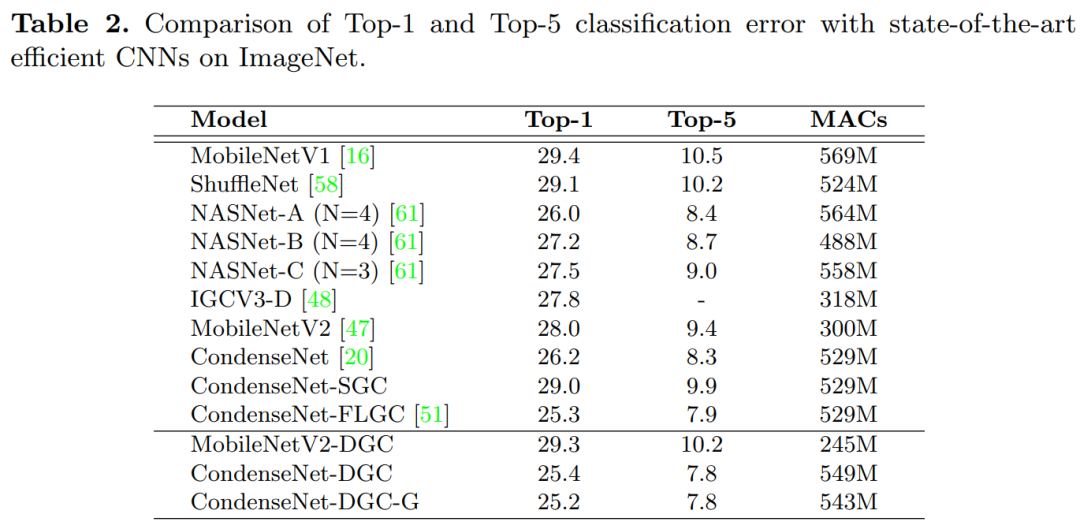
DGC:用于加速卷积神经网络的动态分组卷积(ECCV 2020)Dynamic Group Convolution for Accelerating Convolutional Neural Networks代码:https://github.com/zhuogege1943/dgc论文下:https://arxiv.org/abs/2007.04242为每个组配备一个小的特征选择器,以自动选择以输入图像为条件的最重要的输入通道,性能优于FLGC、SGC和CGNet等分组网络,代码刚刚开源!用分组卷积代替普通卷积可以显著提高现代深度卷积网络的计算效率,这已在紧凑型网络体系结构设计中广泛采用。但是,现有的分组卷积会永久性地切断某些连接,从而破坏了原始网络结构,从而导致精度显著下降。在本文中,我们提出了动态分组卷积(DGC),它可以动态地针对各个样本自适应地选择在每个组内连接输入通道的哪一部分。具体来说,我们为每个组配备一个小的特征选择器,以自动选择以输入图像为条件的最重要的输入通道。多个组可以自适应地捕获每个输入图像的丰富且互补的视觉/语义特征。DGC保留了原始的网络结构,并且同时具有与常规分组卷积相似的计算效率。
在包括CIFAR-10,CIFAR-100和ImageNet在内的多个图像分类基准上进行的大量实验证明,它比现有的分组卷积技术和动态执行方法更具优势。7 DCANet
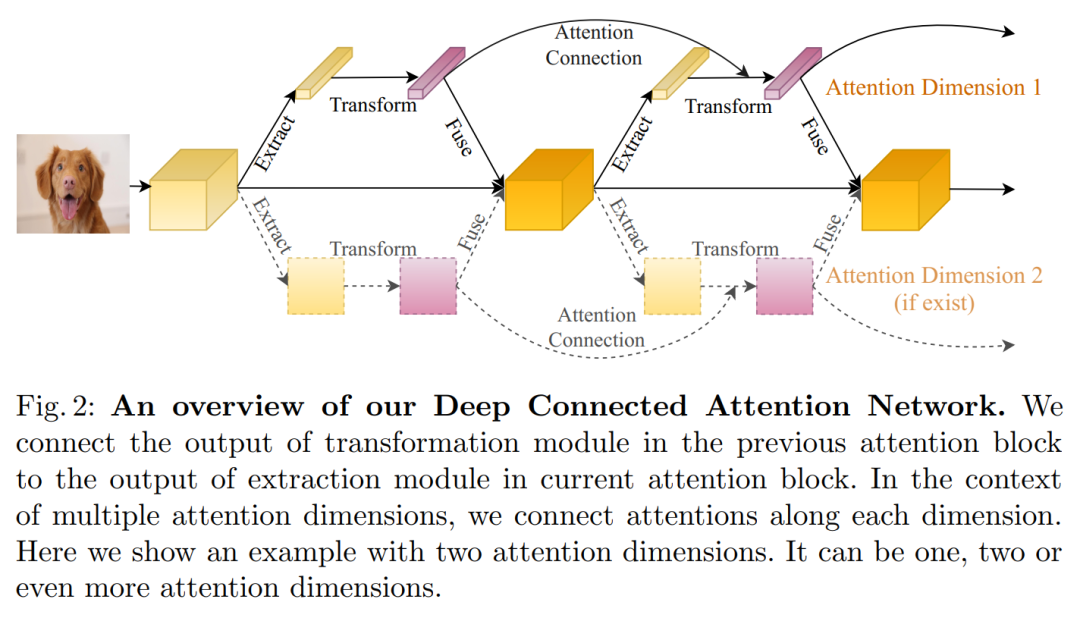
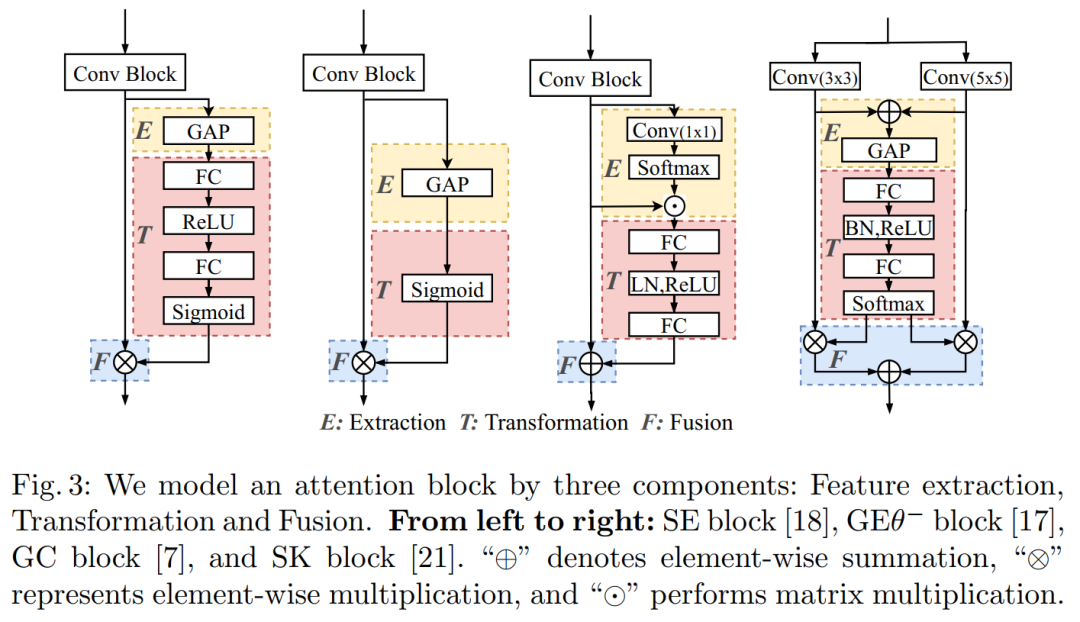
增强注意力!DCANet:学习卷积神经网络的连接注意力DCANet: Learning Connected Attentions for Convolutional Neural Networks
代码:https://github.com/eccv2020-4574/DCANet论文:https://arxiv.org/abs/2007.05099本文深入探索自注意力机制,并提出即插即用的DCA模块,增强你的注意力模型,提高网络性能!如DCA-CBAM/SE/SK-ResNet50组合,代码即将开源!尽管自注意力机制已在许多视觉任务中显示出不错的性能,但它一次只考虑当前的特征。我们表明,这种方式不能充分利用注意力机制。在本文中,我们介绍了深度连接的注意力网络(DCANet),这是一种新颖的设计,可以在不对内部结构进行任何修改的情况下增强CNN模型中的注意力模块。为了实现这一点,我们将相邻的注意力blocks互连,从而使信息在attention blocks之间流动。使用DCANet,可以对CNN模型中的所有注意力模块进行联合训练,从而提高了注意力学习的能力。我们的DCANet是通用的。它不限于特定的注意力模块或基础网络体系结构。
在ImageNet和MS COCO基准测试上的实验结果表明,DCANet在所有测试用例中以最小的额外计算开销始终胜过最新的注意力模块。所有代码和模型均公开提供。8 PSConv
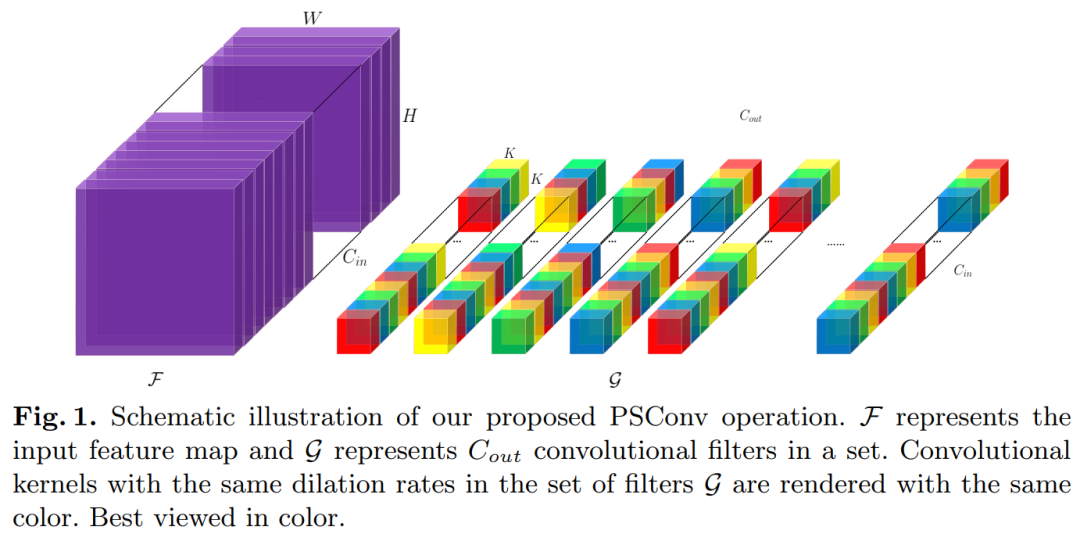
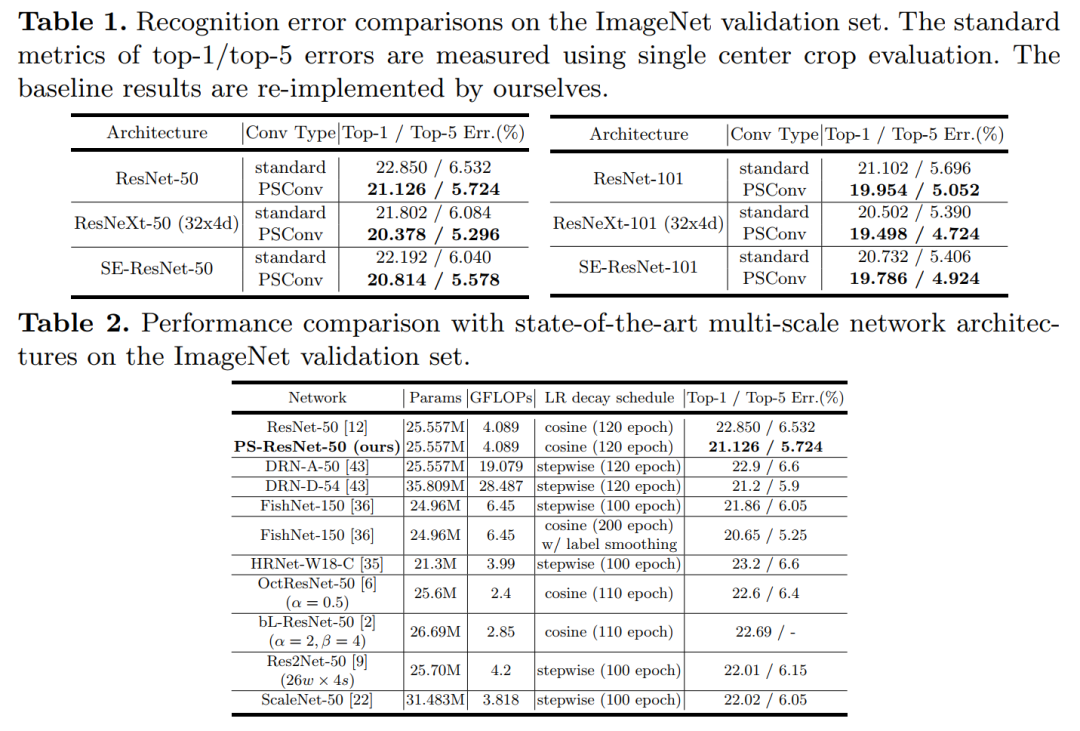
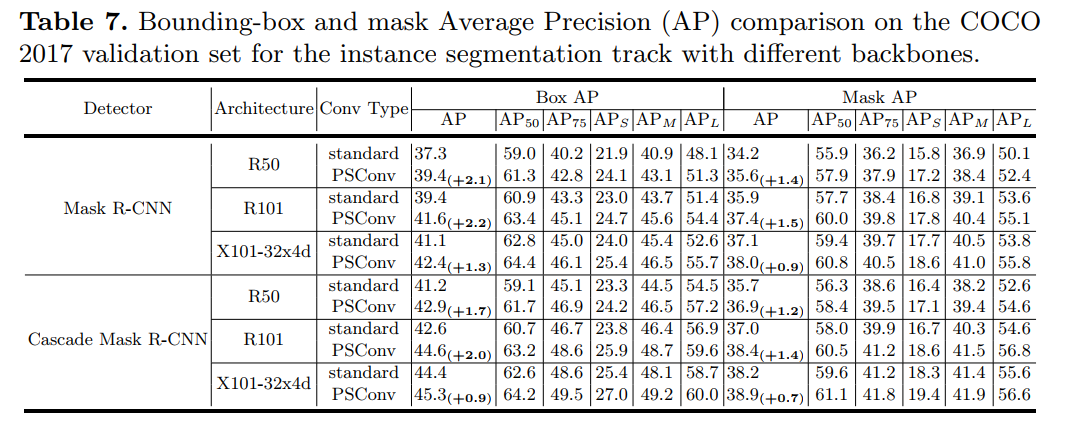
即插即用!PSConv:将特征金字塔压缩到紧凑的多尺度卷积层中(ECCV 2020)PSConv: Squeezing Feature Pyramid into One Compact Poly-Scale Convolutional Layer代码:https://github.com/d-li14/PSConv论文:https://arxiv.org/abs/2007.06191即插即用,涨点明显!用在ResNet-50等CNN,直接涨了1个多点;用在Mask R-CNN等网络上,直接涨近两个点!代码刚刚开源!尽管具有强大的建模能力,但是卷积神经网络(CNN)通常对尺度敏感。为了增强CNN尺度变化的鲁棒性,来自不同层或filters的多尺度特征融合在现有解决方案中引起了极大的关注,而更细粒度的kernel空间却被忽略了。我们通过更精细地利用多尺度特征来弥合这种"遗憾"。所提出的卷积运算被称为“多尺度卷积(PSConv)”,它混合了一系列的dilation rates,并在每个卷积层的单个卷积内核中巧妙地将它们分配给单个卷积层。具体地说,dilation rate沿着filter的输入和输出通道的轴周期性地变化,以整齐的样式在大范围的刻度上聚集特征。PSConv可以替代许多流行的CNN骨干中的vanilla卷积,从而在不引入其他参数和计算复杂性的情况下实现更好的表征学习。在ImageNet和MS COCO基准上进行的全面实验验证了PSConv的出色性能。9 WeightNet
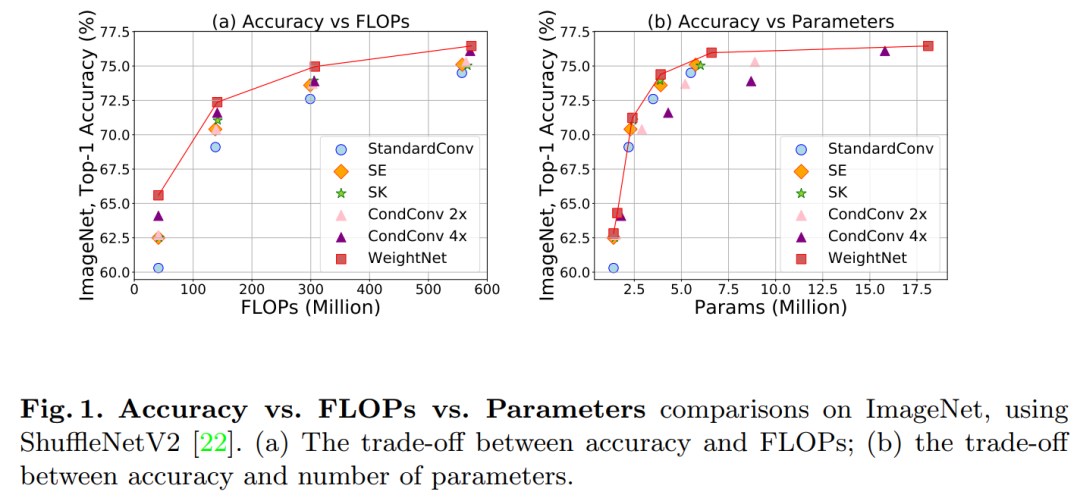
WeightNet:重新探索Weight网络的设计空间(ECCV 2020)WeightNet: Revisiting the Design Space of Weight Networks代码:https://github.com/megvii-model/WeightNet论文:https://arxiv.org/abs/2007.11823涨点神器!可较大提高ShuffleNetV2、ResNet50等CNN的性能,代码刚刚开源!我们提出了一个概念简单,灵活和有效的框架,用于weight 生成网络。我们的方法通常是将两个当前截然不同且极为有效的SENet和CondConv合并到同一weight 空间框架中。称为WeightNet的方法通过将另一组全连接的层简单添加到注意力激活层来泛化这两种方法。我们使用完全由(分组的)全连接层组成的WeightNet直接输出卷积权重。在内核空间而不是特征空间上,WeightNet易于训练并且节省内存。
由于具有灵活性,我们的方法在ImageNet和COCO检测任务上均优于现有方法,从而实现了更好的Accuracy-FLOP和Accuracy-Parameter权衡。灵活的重量空间上的框架有可能进一步提高性能。
10 FPT
南京理工提出FPT:特征金字塔Transformer(ECCV 2020)Feature Pyramid Transformer
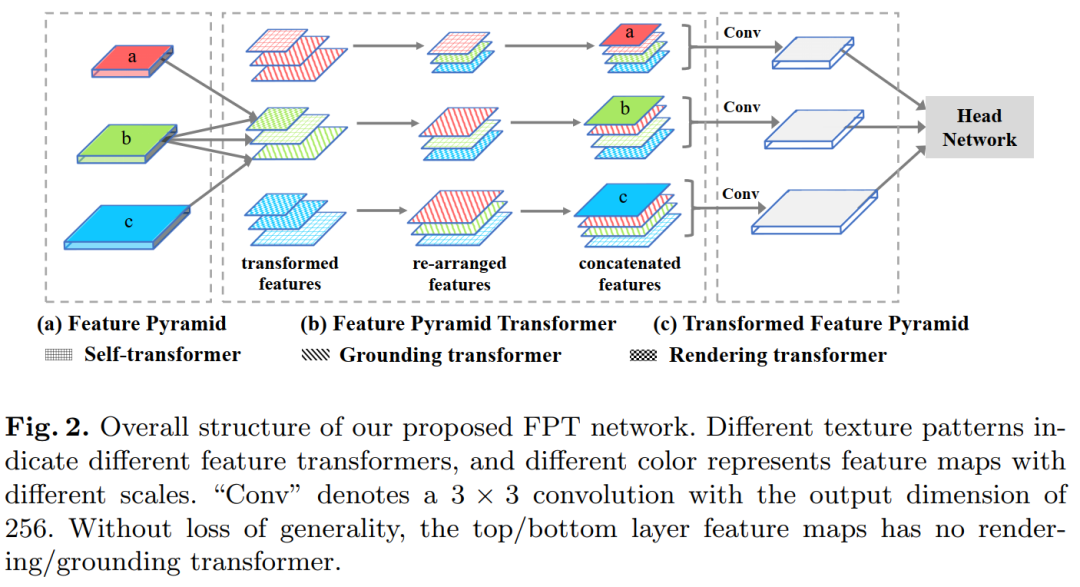
作者单位:南京理工&南洋理工&合工大&阿里达摩院等代码:https://github.com/ZHANGDONG-NJUST/FPT论文:https://arxiv.org/abs/2007.09451即插即用!涨点明显!本文提出FPT:特征金字塔新形态,Transformer大法好!可提高目标检测、语义/实例分割等任务性能,代码刚刚开源!跨空间和尺度的特征交互是现代视觉识别系统的基础,因为它们引入了有益的视觉系统。按照惯例,空间上下文被被动地隐藏在CNN越来越多的感受野中,或者被非局部卷积主动地编码。但是,非局部空间交互作用并不是跨尺度的,因此它们无法捕获位于不同尺度的对象(或零件)的非局部上下文。
为此,我们提出了一种跨空间和尺度的完全活跃的特征交互功能,称为特征金字塔Transformer(FPT)。通过使用self-level,自上而下和自下而上这三个交互方式的特殊设计的transformers,它将任何特征金字塔转换为相同大小但具有更丰富上下文的另一个特征金字塔。FPT充当通用的视觉骨干,具有合理的计算开销。
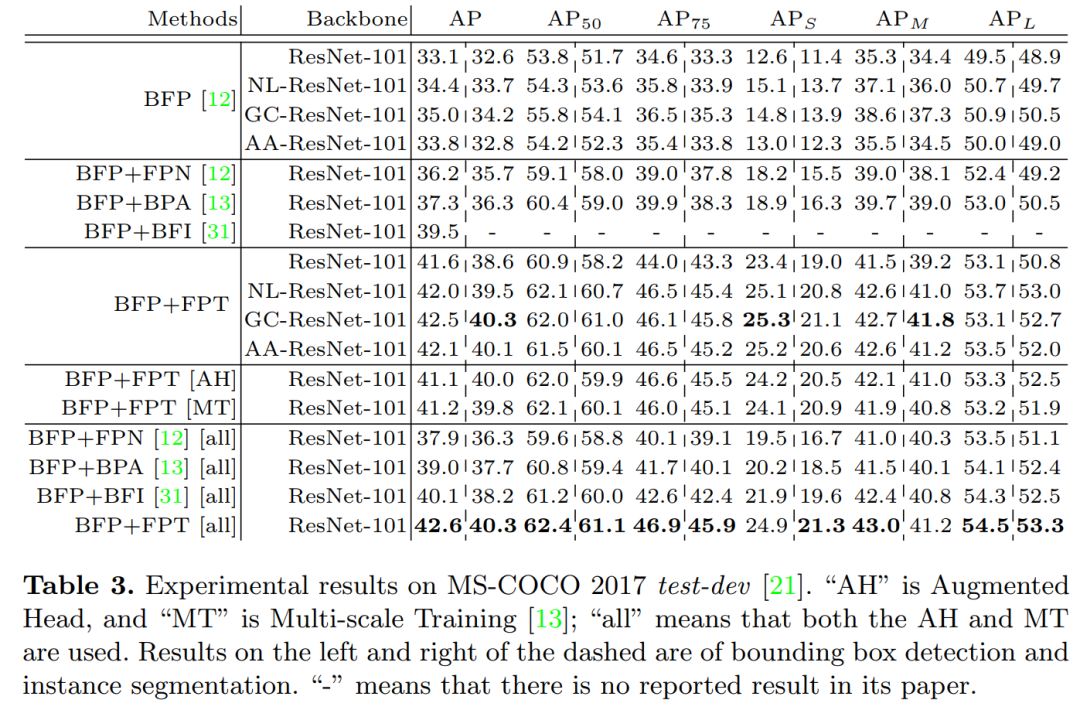
我们使用各种backbone和head网络在实例级(即,目标检测和实例分割)和像素级分割任务中进行了广泛的实验,并观察了所有基线和最新方法的持续改进。
推荐阅读
极市征集了大家关于陪伴的故事
投票通道现已开启
快来为你喜爱的TA加油吧!
极市平台公众号回复“七夕”即可获取投票链接
大家可添加极小东微信(ID:cvmart3)投稿~
△ 扫码添加极小东微信
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~觉得有用麻烦给个在看啦~